Download presentation
Presentation is loading. Please wait.

1
Seven Databases in Seven Weeks HBase ふつかめ

2
Hbase とは何か Google File Sytem (GFS) MapReduceBigTable Google の 内部システム (発表した論文より) Hadoop Distributed File Sytem (HDFS) MapReduceHBase Hadoop プロジェクト ( Google クローン) バッチ処理リアルタイム応答 復習
 MapReduceBigTable Google の 内部システム (発表した論文より) Hadoop Distributed File Sytem (HDFS) MapReduceHBase Hadoop プロジェクト ( Google クローン) バッチ処理リアルタイム応答 復習")
3
RowKeyColumnFamily1ColumnFamily2ColumnFamily3 1Column1Column2Column1Column2Column1 2Column2Column3Column2Column3 BigTable ( ソート済列志向データベース ) スキーマで定義する スキーマレス(自由に追加できる) 必須 ソート済 #FFF ある Column #000 #0F0 #00F #F00 timestamp 1 timestamp 2 timestamp 3 timestamp 4 timestamp 5 タイムスタンプでバージョニングされる 復習
 スキーマで定義する スキーマレス(自由に追加できる) 必須 ソート済 #FFF ある Column #000 #0F0 #00F #F00 timestamp 1 timestamp 2 timestamp 3 timestamp 4 timestamp 5 タイムスタンプでバージョニングされる 復習")
4
RowKeyColumnFamily1ColumnFamily2ColumnFamily3 1 2 3 4 5 6 7 8 9 リージョン リージョン分割・自動シャーディング リージョン テーブルはリージョンで物理的に分割(シャーディング)される リージョンはクラスタ中のリージョンサーバが担当する リージョンは ColumnFamily 毎に作られる リージョンは ソート済の RowKey を適当なサイズで分割する 復習
される リージョンはクラスタ中のリージョンサーバが担当する リージョンは ColumnFamily 毎に作られる リージョンは ソート済の RowKey を適当なサイズで分割する 復習")
5
HBase の特徴 自動シャーディング・自動フェールオーバー データの一貫性 (CAP:Consistency) Hadoop/HDFS 統合 テーブルサイズが大きくなった時、自動的に分割する 分割されたシャードは、ノード障害時に自動的にフェールオーバーする データの更新は反映された瞬間から読出可能 結果的に同じ値が読めるようになる(結果整合性)条件緩和を取らない Hadoop の HDFS 上 に展開できる Hadoop/MapReduce で API を挟まず HBase を入出力の対象にできる 復習
 Hadoop/HDFS 統合 テーブルサイズが大きくなった時、自動的に分割する 分割されたシャードは、ノード障害時に自動的にフェールオーバーする データの更新は反映された瞬間から読出可能 結果的に同じ値が読めるようになる(結果整合性)条件緩和を取らない Hadoop の HDFS 上 に展開できる Hadoop/MapReduce で API を挟まず HBase を入出力の対象にできる 復習")
6
7 つのデータベース7つの世界 での構成 1日目: CRUD とテーブル管理 2日目:ビッグデータを扱う 3日目:クラウドに持っていく スタンドアロンで Hbase を動かす テーブルを作る データの出し入れをする Wikipedia ダンプを投入する スクリプト (Not Shell) での操作に慣れる Thrift を使って操作する Whirr を使って EC2 にデプロイする 今回は扱いません
 での操作に慣れる Thrift を使って操作する Whirr を使って EC2 にデプロイする 今回は扱いません")
7
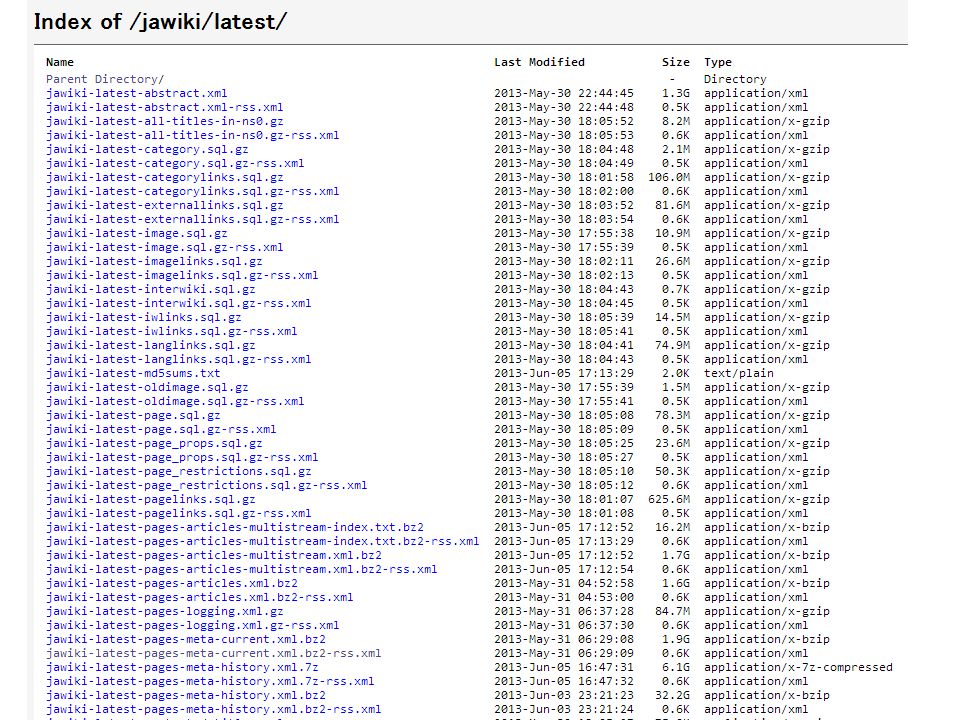
Wikipedia の ダンプファイルを HBase で扱う

9
<mediawiki xmlns=http://www.mediawiki.org/xml/export-0.8/http://www.mediawiki.org/xml/export-0.8/ xmlns:xsi=http://www.w3.org/2001/XMLSchema-instancehttp://www.w3.org/2001/XMLSchema-instance xsi:schemaLocation=http://www.mediawiki.org/xml/export-0.8/ http://www.mediawiki.org/xml/export-0.8.xsdhttp://www.mediawiki.org/xml/export-0.8/ http://www.mediawiki.org/xml/export-0.8.xsd version="0.8" xml:lang="ja"> Wikipedia http://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8 MediaWiki 1.22wmf2 first-letter メディア 特別 アンパサンド 0 5 46524710 44911376 2013-03-06T22:31:33Z Addbot 712937 ボット : 言語間リンク 31 件を [[d:| ウィキデータ ]] 上の [[d:q11213]] に転記 {{ 記号文字 |&}} [[Image:Trebuchet MS ampersand.svg|right|thumb|100px|[[Trebuchet MS]] フォント ]] [[Category: ラテン語の語句 ]] 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … サンプルデータ
![<mediawiki xmlns= xmlns:xsi= xsi:schemaLocation= version= 0.8 xml:lang= ja > Wikipedia MediaWiki 1.22wmf2 first-letter メディア 特別 アンパサンド T22:31:33Z Addbot ボット : 言語間リンク 31 件を [[d:| ウィキデータ ]] 上の [[d:q11213]] に転記 {{ 記号文字 |&}} [[Image:Trebuchet MS ampersand.svg|right|thumb|100px|[[Trebuchet MS]] フォント ]] [[Category: ラテン語の語句 ]] 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … サンプルデータ](http://images.slidesplayer.net/39/11021658/slides/slide_9.jpg "<mediawiki xmlns= xmlns:xsi= xsi:schemaLocation= version= 0.8 xml:lang= ja > Wikipedia MediaWiki 1.22wmf2 first-letter メディア 特別 アンパサンド T22:31:33Z Addbot ボット : 言語間リンク 31 件を [[d:| ウィキデータ ]] 上の [[d:q11213]] に転記 {{ 記号文字 |&}} [[Image:Trebuchet MS ampersand.svg|right|thumb|100px|[[Trebuchet MS]] フォント ]] [[Category: ラテン語の語句 ]] 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … サンプルデータ")
10
<mediawiki xmlns=http://www.mediawiki.org/xml/export-0.8/http://www.mediawiki.org/xml/export-0.8/ xmlns:xsi=http://www.w3.org/2001/XMLSchema-instancehttp://www.w3.org/2001/XMLSchema-instance xsi:schemaLocation=http://www.mediawiki.org/xml/export-0.8/ http://www.mediawiki.org/xml/export-0.8.xsdhttp://www.mediawiki.org/xml/export-0.8/ http://www.mediawiki.org/xml/export-0.8.xsd version="0.8" xml:lang="ja"> Wikipedia http://ja.wikipedia.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8 MediaWiki 1.22wmf2 first-letter メディア 特別 アンパサンド 0 5 46524710 44911376 2013-03-06T22:31:33Z Addbot 712937 ボット : 言語間リンク 31 件を [[d:| ウィキデータ ]] 上の [[d:q11213]] に転記 {{ 記号文字 |&}} [[Image:Trebuchet MS ampersand.svg|right|thumb|100px|[[Trebuchet MS]] フォント ]] [[Category: ラテン語の語句 ]] 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … サンプルデータ Rowkey:titleidtextrevision アンパサンド 5 {{ 記号文字 … parentid:44911376 …
![<mediawiki xmlns= xmlns:xsi= xsi:schemaLocation= version= 0.8 xml:lang= ja > Wikipedia MediaWiki 1.22wmf2 first-letter メディア 特別 アンパサンド T22:31:33Z Addbot ボット : 言語間リンク 31 件を [[d:| ウィキデータ ]] 上の [[d:q11213]] に転記 {{ 記号文字 |&}} [[Image:Trebuchet MS ampersand.svg|right|thumb|100px|[[Trebuchet MS]] フォント ]] [[Category: ラテン語の語句 ]] 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … サンプルデータ Rowkey:titleidtextrevision アンパサンド 5 {{ 記号文字 … parentid: …](http://images.slidesplayer.net/39/11021658/slides/slide_10.jpg "<mediawiki xmlns= xmlns:xsi= xsi:schemaLocation= version= 0.8 xml:lang= ja > Wikipedia MediaWiki 1.22wmf2 first-letter メディア 特別 アンパサンド T22:31:33Z Addbot ボット : 言語間リンク 31 件を [[d:| ウィキデータ ]] 上の [[d:q11213]] に転記 {{ 記号文字 |&}} [[Image:Trebuchet MS ampersand.svg|right|thumb|100px|[[Trebuchet MS]] フォント ]] [[Category: ラテン語の語句 ]] 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … サンプルデータ Rowkey:titleidtextrevision アンパサンド 5 {{ 記号文字 … parentid: …")
11
hbase(main):004:0> create 'wiki', 'id', 'text', 'revision' 0 row(s) in 2.4180 seconds hbase(main):005:0> disable 'wiki' 0 row(s) in 2.3650 seconds hbase(main):006:0> alter 'wiki', {NAME=>'text', COMPRESSION=>'GZ', BLOOMFILTER=>'ROW'} Updating all regions with the new schema... 1/1 regions updated. Done. 0 row(s) in 1.2860 seconds hbase(main):007:0> enable 'wiki' 0 row(s) in 2.7430 seconds Rowkey:titleidtextrevision アンパサンド 5 {{ 記号文字 … parentid:44911376 … スキーマ定義 ColumnFamily:Text の 圧縮・ BloomFilter 有効 スキーマ作成 BloomFilter ‘ROW’ : RowKey のみ 'ROWCOL' : RowKey/ColumnFamily リージョン中に指定した RowKey/ColumnFamily がないことを高速に検知する リージョン中の RowKey/ColmnFamily クエリ
 in seconds hbase(main):007:0> enable wiki 0 row(s) in seconds Rowkey:titleidtextrevision アンパサンド 5 {{ 記号文字 … parentid: … スキーマ定義 ColumnFamily:Text の 圧縮・ BloomFilter 有効 スキーマ作成 BloomFilter ‘ROW’ : RowKey のみ ROWCOL : RowKey/ColumnFamily リージョン中に指定した RowKey/ColumnFamily がないことを高速に検知する リージョン中の RowKey/ColmnFamily クエリ.")
12
include Java import org.apache.hadoop.hbase.client.HTable import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.HBaseConfiguration import javax.xml.stream.XMLStreamConstants require "time" def jbytes(*args) args.map { |arg| arg.to_s.to_java_bytes } end factory = javax.xml.stream.XMLInputFactory.newInstance reader = factory.createXMLStreamReader(java.lang.System.in) table = HTable.new( HBaseConfiguration.new, "wiki" ) document = nil buffer = nil count = 0 while reader.has_next type = reader.next if type == XMLStreamConstants::START_ELEMENT tag = reader.local_name case tag when 'page' then document = {} when /title|id|parentid|timestamp|text/ then buffer = [] end elsif type == XMLStreamConstants::CHARACTERS text = reader.text buffer << text unless buffer.nil? elsif type == XMLStreamConstants::END_ELEMENT tag = reader.local_name case tag when /title|id|parentid|timestamp|text/ then document[tag] = buffer.join when 'revision' key = document['title'].to_java_bytes ts = (Time.parse document['timestamp']).to_i p = Put.new(key, ts) p.add( *jbytes("text", "", document['text']) ) p.add( *jbytes("id", "", document['id']) ) p.add( *jbytes("revision", "parendid", document['parentid']) ) table.put(p) count += 1 table.flushCommits() if count % 50 == 0 puts "#{count} records inserted (#{document['title']})" if count % 1000 == 0 end table.flushCommits() puts "#{count}" exit データ投入用コード [root@HBase01 opt]# cat jawiki-latest-pages-meta-current.xml | time hbase-0.94.7/bin/hbase org.jruby.Main hoge.rb 2362613 860.30user 172.80system 28:29.00elapsed 60%CPU (0avgtext+0avgdata 696352maxresident)k 304inputs+4072outputs (0major+91296minor)pagefaults 0swaps 実行例
![include Java import org.apache.hadoop.hbase.client.HTable import org.apache.hadoop.hbase.client.Put import org.apache.hadoop.hbase.HBaseConfiguration import javax.xml.stream.XMLStreamConstants require time def jbytes(*args) args.map { |arg| arg.to_s.to_java_bytes } end factory = javax.xml.stream.XMLInputFactory.newInstance reader = factory.createXMLStreamReader(java.lang.System.in) table = HTable.new( HBaseConfiguration.new, wiki ) document = nil buffer = nil count = 0 while reader.has_next type = reader.next if type == XMLStreamConstants::START_ELEMENT tag = reader.local_name case tag when page then document = {} when /title|id|parentid|timestamp|text/ then buffer = [] end elsif type == XMLStreamConstants::CHARACTERS text = reader.text buffer << text unless buffer.nil.](http://images.slidesplayer.net/39/11021658/slides/slide_12.jpg "elsif type == XMLStreamConstants::END_ELEMENT tag = reader.local_name case tag when /title|id|parentid|timestamp|text/ then document[tag] = buffer.join when revision key = document[ title ].to_java_bytes ts = (Time.parse document[ timestamp ]).to_i p = Put.new(key, ts) p.add( *jbytes( text , , document[ text ]) ) p.add( *jbytes( id , , document[ id ]) ) p.add( *jbytes( revision , parendid , document[ parentid ]) ) table.put(p) count += 1 table.flushCommits() if count % 50 == 0 puts #{count} records inserted (#{document[ title ]}) if count % 1000 == 0 end table.flushCommits() puts #{count} exit データ投入用コード opt]# cat jawiki-latest-pages-meta-current.xml | time hbase /bin/hbase org.jruby.Main hoge.rb user system 28:29.00elapsed 60%CPU (0avgtext+0avgdata maxresident)k 304inputs+4072outputs (0major+91296minor)pagefaults 0swaps 実行例.")
13
document = nil buffer = nil count = 0 while reader.has_next type = reader.next if type == XMLStreamConstants::START_ELEMENT tag = reader.local_name case tag when 'page' then document = {} when /title|id|parentid|timestamp|text/ then buffer = [] end elsif type == XMLStreamConstants::CHARACTERS text = reader.text buffer << text unless buffer.nil? elsif type == XMLStreamConstants::END_ELEMENT tag = reader.local_name case tag when /title|id|parentid|timestamp|text/ document[tag] = buffer.join when 'revision' key = document['title'].to_java_bytes ts = (Time.parse document['timestamp']).to_i p = Put.new(key, ts) p.add( *jbytes("text", "", document['text']) ) p.add( *jbytes("id", "", document['id']) ) p.add( *jbytes("revision", "parendid", document['parentid']) ) table.put(p) count += 1 table.flushCommits() if count % 50 == 0 if count % 1000 == 0 puts "#{count} records inserted (#{document['title']})“ end table.flushCommits() puts "#{count}" exit アンパサンド 0 5 46524710 44911376 2013-03-06T22:31:33Z Addbot 712937 … 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … 開始タグ 終了タグ タグ内要素 投入 データ投入用コード
![document = nil buffer = nil count = 0 while reader.has_next type = reader.next if type == XMLStreamConstants::START_ELEMENT tag = reader.local_name case tag when page then document = {} when /title|id|parentid|timestamp|text/ then buffer = [] end elsif type == XMLStreamConstants::CHARACTERS text = reader.text buffer << text unless buffer.nil.](http://images.slidesplayer.net/39/11021658/slides/slide_13.jpg "elsif type == XMLStreamConstants::END_ELEMENT tag = reader.local_name case tag when /title|id|parentid|timestamp|text/ document[tag] = buffer.join when revision key = document[ title ].to_java_bytes ts = (Time.parse document[ timestamp ]).to_i p = Put.new(key, ts) p.add( *jbytes( text , , document[ text ]) ) p.add( *jbytes( id , , document[ id ]) ) p.add( *jbytes( revision , parendid , document[ parentid ]) ) table.put(p) count += 1 table.flushCommits() if count % 50 == 0 if count % 1000 == 0 puts #{count} records inserted (#{document[ title ]}) end table.flushCommits() puts #{count} exit アンパサンド T22:31:33Z Addbot … 4duebxtzaadjddpy3036cey6451d992 wikitext text/x-wiki … 開始タグ 終了タグ タグ内要素 投入 データ投入用コード.")
14
実験 投入時 取出し時 Q: text 領域の GZ 圧縮により高速化するのか? A: 46min -> 26min (70% 高速化 ) Q: text 領域の GZ 圧縮によりデータ領域は節約されるのか? A: 8.1GB -> 2.6GB (32% のサイズに圧縮 ) Q: text 領域の GZ 圧縮により get は高速化するのか? A: 有意な差がない Q: 全体 scan と部分 scan での速度差は? A: 0.136[s] ( 開始 RowKey 指定,10 件 ) vs 119.738[s]( 全体,Column 値条件検索 ) Q: text 領域の GZ 圧縮により scan は高速化するのか? A: 条件による(次ページ)
![実験 投入時 取出し時 Q: text 領域の GZ 圧縮により高速化するのか? A: 46min -> 26min (70% 高速化 ) Q: text 領域の GZ 圧縮によりデータ領域は節約されるのか? A: 8.1GB -> 2.6GB (32% のサイズに圧縮 ) Q: text 領域の GZ 圧縮により get は高速化するのか? A: 有意な差がない Q: 全体 scan と部分 scan での速度差は? A: 0.136[s] ( 開始 RowKey 指定,10 件 ) vs [s]( 全体,Column 値条件検索 ) Q: text 領域の GZ 圧縮により scan は高速化するのか? A: 条件による(次ページ)](http://images.slidesplayer.net/39/11021658/slides/slide_14.jpg "実験 投入時 取出し時 Q: text 領域の GZ 圧縮により高速化するのか? A: 46min -> 26min (70% 高速化 ) Q: text 領域の GZ 圧縮によりデータ領域は節約されるのか? A: 8.1GB -> 2.6GB (32% のサイズに圧縮 ) Q: text 領域の GZ 圧縮により get は高速化するのか? A: 有意な差がない Q: 全体 scan と部分 scan での速度差は? A: 0.136[s] ( 開始 RowKey 指定,10 件 ) vs [s]( 全体,Column 値条件検索 ) Q: text 領域の GZ 圧縮により scan は高速化するのか? A: 条件による(次ページ)")
15
GZ 圧縮と Text (大きな ColumnFamily )と scan hbase(main):001:0> scan 'wiki', {COLUMN=>['id','revision'], FILTER => "SingleColumnValueFilter('revision','parendid',=,'binary:46628036')"} hbase(main):001:0> scan 'wiki', {FILTER => "SingleColumnValueFilter('revision','parendid',=,'binary:46628036')"} hbase(main):001:0> scan 'wiki', {FILTER => "SingleColumnValueFilter('text','',=,'substring: ぱんだねこ ')"} titleidtextrevision リージョン
![GZ 圧縮と Text (大きな ColumnFamily )と scan hbase(main):001:0> scan wiki , {COLUMN=>[ id , revision ], FILTER => SingleColumnValueFilter( revision , parendid ,=, binary: ) } hbase(main):001:0> scan wiki , {FILTER => SingleColumnValueFilter( revision , parendid ,=, binary: ) } hbase(main):001:0> scan wiki , {FILTER => SingleColumnValueFilter( text , ,=, substring: ぱんだねこ ) } titleidtextrevision リージョン](http://images.slidesplayer.net/39/11021658/slides/slide_15.jpg "GZ 圧縮と Text (大きな ColumnFamily )と scan hbase(main):001:0> scan wiki , {COLUMN=>[ id , revision ], FILTER => SingleColumnValueFilter( revision , parendid ,=, binary: ) } hbase(main):001:0> scan wiki , {FILTER => SingleColumnValueFilter( revision , parendid ,=, binary: ) } hbase(main):001:0> scan wiki , {FILTER => SingleColumnValueFilter( text , ,=, substring: ぱんだねこ ) } titleidtextrevision リージョン")
Similar presentations
 Server DFS HBase.>")













>")
.>")
.>")

 2006/06/29 竹内豪.>")
