Download presentation
Presentation is loading. Please wait.

1
奈良先端科学技術大学院大学 情報科学研究科 松本裕治
2003年6月10日(火) 静岡大学情報学部 機械学習に基づく日本語解析システム 奈良先端科学技術大学院大学 情報科学研究科 松本裕治
 静岡大学情報学部. 機械学習に基づく日本語解析システム. 奈良先端科学技術大学院大学. 情報科学研究科. 松本裕治.")
2
形態素解析 文を単語に区切り、品詞を同定する処理 以下の3つの処理より成る 単語への分かち書き(tokenization)
文を単語単位の文字列に分ける処理 活用語処理(stemming, lemmatization) 英語の動詞や名詞の語尾、日本語の活用語の語尾などを処理し、原型と活用形情報を得る処理 品詞同定(part-of-speech tagging) 個々の単語の品詞を推定する処理
 英語の動詞や名詞の語尾、日本語の活用語の語尾などを処理し、原型と活用形情報を得る処理. 品詞同定(part-of-speech tagging) 個々の単語の品詞を推定する処理.")
3
形態素解析の問題点 それぞれの処理に曖昧性が発生する 単語への分かち書き 活用語処理 品詞同定
日本語では単語がスペースによって区切られてないため、分かち書きの曖昧性の問題が深刻 英語では、スペースによって単語がくぎられているが、例外も多い。 カンマやピリオドなどの句読点はスペースで区切られない。 ピリオドなどが常に句読点とは限らない(Mr., U.S.A., I’m など) 複数の語がひとつの語のような働きをする場合がある (“New York” “with regard to” など) 活用語処理 品詞同定 同じ形の語が複数の品詞や活用形の可能性がある場合がある
 複数の語がひとつの語のような働きをする場合がある. ( New York with regard to など) 活用語処理. 品詞同定. 同じ形の語が複数の品詞や活用形の可能性がある場合がある.")
4
形態素解析に必要な事項 基本的な処理: 辞書から単語を引いて、与えられた文と照合し、最も自然な単語列を求める 辞書 解の探索
入力文は文字列(単語毎に区切られていない) どの文字列を対象に辞書引きをするかが自明でない 解の探索 すべての可能な単語の組合せから(何らかの基準で)最適な単語列を発見する 単純に全探索を行うのは計算量が膨大 動的計画法に基づくアルゴリズムが用いられる(Viterbi algorithm)
 どの文字列を対象に辞書引きをするかが自明でない. 解の探索. すべての可能な単語の組合せから(何らかの基準で)最適な単語列を発見する. 単純に全探索を行うのは計算量が膨大. 動的計画法に基づくアルゴリズムが用いられる(Viterbi algorithm)")
5
形態素解析のための辞書の構成 文に含まれるすべての単語は、実はかなりの数
「単語毎に区切られていない」という文は正しくは、8単語からなる 「単語 / 毎 / に / 区切ら / れ / て / い / ない」 現在の辞書ですべての形態素を検索すると、上の文には69語もの異なる単語が含まれる 入力文のすべての部分文字列に対して辞書引きを行うのは、あまりにも効率が悪い 辞書の構成を工夫する必要がある 部分文字列のすべてを高速に検索するためのデータ構造がいくつか提案されている TRIE構造、パトリシア木、Suffix array など

6
日本語処理のための辞書の要件 単語の区切りが明確でないので、先頭から何文字までが単語なのかわからない。
先頭から1文字、2文字と順番に辞書を引く? しかし、どこまでを辞書引きの対象にすればよいかわからない このような接頭部分が重なった文字列を効率的に検索する方法が必要 TRIE構造 奈良先端科学技術大学院大学情報科学研究科

7
辞書検索のためのデータ構造:TRIE TRIE: 文字毎にポインタを持たせた木構造 a z c b b i a u d t t a c b
a bide aba ca aback case abc cat ad cute bib bible a z c b b i a u d t t a c b d s e c l e e 上の単語が登録 されたTRIE 赤丸が単語の終了 位置を表す k e

8
辞書検索のためのデータ構造:TRIE 日本語でも同様 あ 轟 奈 大 ら 良 平 わ 阪 府 洋 ま し 先 県 大 端 庁 学
赤丸が単語の終了 位置を表す き 大

9
TRIEの特徴 対象文字列の先頭から文字を順番にたどっていくことによって、すべての単語を検索可能 入力文字列の長さに比例した時間で探索が可能
辞書引き終了のタイミングが自動的にわかる TRIEの葉の末端に来るか、検索対象の文字に対応する枝がない場合に探索を終了すればよい TRIEの欠点 メモリ効率が悪い 各節点からアルファベットの数の枝が出るが、木の下の方では、ほとんどの節点は少数の枝しかもたない 節点のデータ構造の効率が極めて悪い 日本語の場合は、文字種(数千種類)だけの出力枝を各節点に持たせるのは現実的に不可能
だけの出力枝を各節点に持たせるのは現実的に不可能.")
10
TRIE構造実現のための工夫 日本語の場合: 問題の解決策
各文字(2バイト文字)ごとに出力枝をもたせるのではなく、2バイトコードのうちの1バイトごとに節点を作る これにより、中間の節点は(1バイトコード文字であるアルファベットや数字を除いて)無駄になるが、メモリ効率は大幅によくなる(各節点からの出力枝の数は高々28 =128本) これでも、多くの節点は、それより遥かに少ない枝しかもたず、各節点が無駄なデータ領域を持つことになる 問題の解決策 ダブル配列によるデータ領域の圧縮 2分木による再構成 パトリシア木
ごとに出力枝をもたせるのではなく、2バイトコードのうちの1バイトごとに節点を作る. これにより、中間の節点は(1バイトコード文字であるアルファベットや数字を除いて)無駄になるが、メモリ効率は大幅によくなる(各節点からの出力枝の数は高々28 =128本) これでも、多くの節点は、それより遥かに少ない枝しかもたず、各節点が無駄なデータ領域を持つことになる. 問題の解決策. ダブル配列によるデータ領域の圧縮. 2分木による再構成 パトリシア木.")
11
2分木を用いたTRIE すべての文字を2進数表示で考える 各節点は、2つの枝(0と1に対応)しか持たない
枝に関する無駄な領域は大幅に削減できるが、無駄な節点が多数できる それぞれの文字の 2進数表現よって2進木 の位置と対応つける 1 a= b= c=

12
2分木TRIEの特徴と欠点 2分木にすることによって節点は2出力しかもたず、コンパクトに表現できる
しかし、実際の単語を登録すると、ほとんどの節点は、1本の枝しか必要としない 枝分かれのないパス a= 1 b= 1 1 1 1 1 1 1 c=

13
パトリシア木 2分木TRIEの枝分かれのないパスを縮退し、途中に節点を設けない 枝が分岐するところにだけ、節点を作る
各節点は、自分が何ビット目の節点かの情報をもつ 節点に書かれた数字は、 入力文字列の何ビット目 の0, 1の値を確認せよ、と いう意味 10 8 7 1 1 9 1 8 1 a= 1 1 12 4 b= 1 11 c=

14
パトリシア木の特徴 2分木TRIEと比較すると、枝が分岐するところにのみ節点を設けるところが特徴:記憶効率が大幅に向上
各節点では、指定されたビットの0,1のチェックしかしない 最終的に検索が成功した時点で改めて検索文字との照合を行う必要がある 節点に書かれた数字は、 入力文字列の何ビット目 の0, 1の値を確認せよ、と いう意味 10 8 7 1 1 9 1 8 1 a= 1 1 12 4 b= 1 11 c=

15
規則に基づく形態素解析 データに基づいて統計的にパラメータ学習を行う最近の傾向に比べて、人手による規則に基づいて解析を行う方法が80年代以前は主流。 規則(ヒューリスティックス)に基づく手法 最長一致法 与えられた文を単語に切る際に、最も綴りの長い単語を優先する。 分割数最小法 文全体が最小個数の単語に切られる単語列を優先する。 文節数最小法 文全体の文節数が最小になるような単語列を選ぶ (文節 --- 自立語列に続く付属語列からなるかたまり) これらの方法では曖昧性が解消されない例が多い
 これらの方法では曖昧性が解消されない例が多い.")
16
規則に基づく方法の問題点 最長一致法 分割数最小法 文節数最小法 「全日本部課長会議」 「いるかどうかわからない」 「木のはが枯れている」
「全日 / 本部 / 課長 / 会議」「全 / 日本 / 部課長 / 会議」 分割数最小法 「いるかどうかわからない」 「いるか / どうか / わから / ない」 「いる / か / どう / か / わから / ない」 文節数最小法 「木のはが枯れている」 「木 / の / は(係助詞) / が // 枯れ / て / いる」 「木 / の // は(名詞) / が // 枯れ / て / いる」
 / が // 枯れ / て / いる」 「木 / の // は(名詞) / が // 枯れ / て / いる」")
17
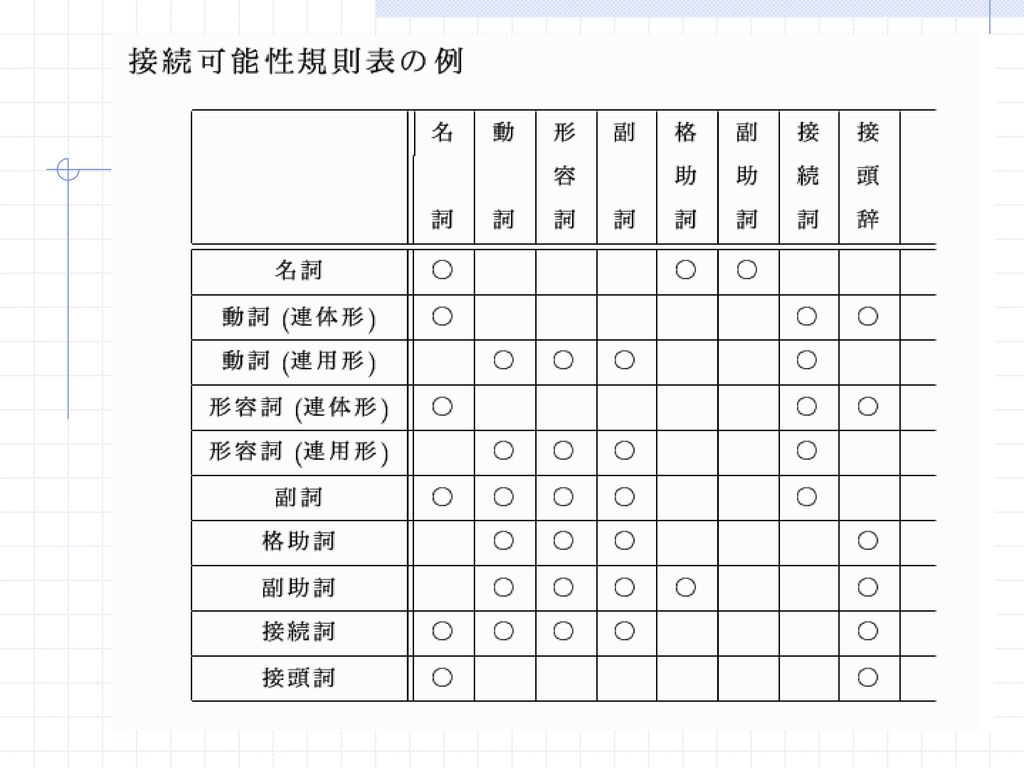
接続可能性規則(表)に基づく形態素解析 最長一致法などの単純な方法では、細かい品詞などの区別ができない。
単語、あるいは、品詞が連接して文中に現れる可能性を規則として列挙し、可能な品詞列だけを解として求める方法 連接可能性規則表は、品詞(あるいは単語)による2次元の行列として表される 文法的に不自然な品詞の連接を制限することができるので、ある程度の曖昧性を解消することができるが、複数の解が存在する可能性は残る
による2次元の行列として表される. 文法的に不自然な品詞の連接を制限することができるので、ある程度の曖昧性を解消することができるが、複数の解が存在する可能性は残る.")
19
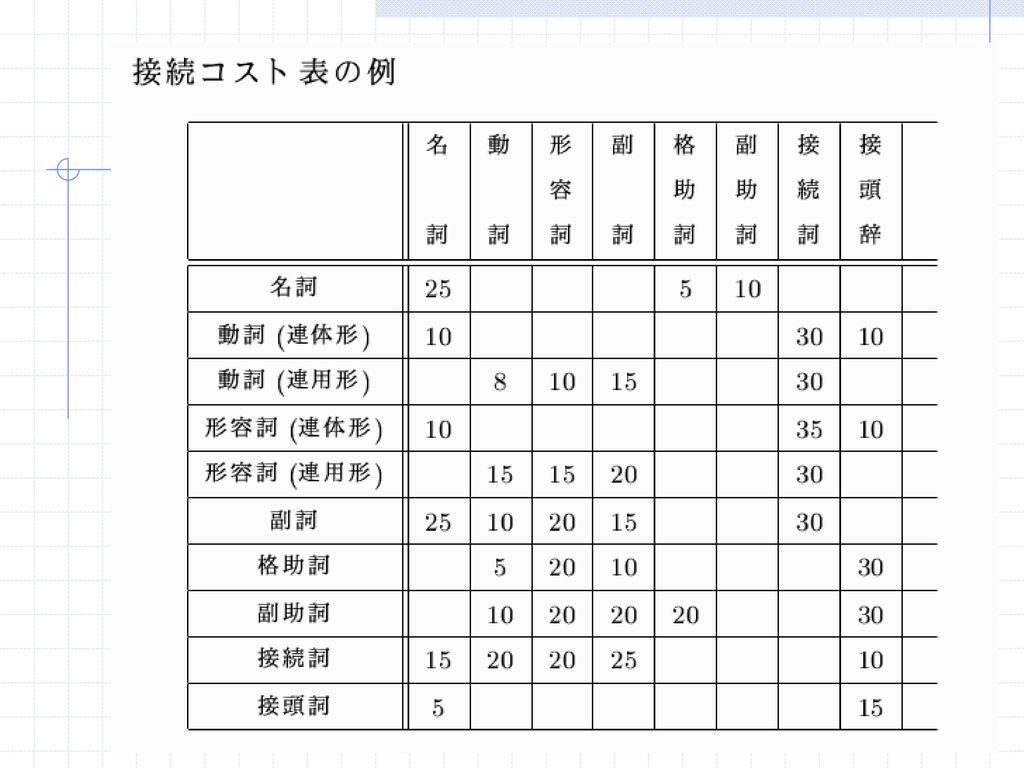
接続コスト表によるコスト最小法 単語、あるいは、品詞が連接して文中に現れる可能性の強さをコストとして数値化し、もっともコストの低い品詞列を解として求める方法 連接コスト表は、品詞(あるいは単語)を行と列にもち、コストを要素とする2次元の行列によって表される 複数の解の間の優劣をコストによって区別することができる どのようにしてコストを設定するかが問題 人手によってコストを決めるのは、負担が大きい コストの決め方に一貫性を保つのが難しい

21
連接表に基づく方法の問題点と解決策 接続可能性規則 接続コスト最小法
複数の可能な解の間の優劣をつけることができない。 接続コスト最小法 人手によるコスト値の決定が非常に困難 以下では、確率をベースに品詞の接続の強さを測り、それをコストとして定義しなおす。 理由:確率値の逆数の対数をコストと見ると、コスト最小法を確率モデルと等価と考えることが可能。 これにより、正しいデータ(タグ付コーパス)からのコスト(確率値)学習が可能になる
からのコスト(確率値)学習が可能になる.")
22
統計情報に基づく形態素解析 品詞付与された解析済みコーパスから、単語の出現のしやすさ、品詞(単語)のつながりやすさを確率値として求める。
文を構成する単語の出現確率が直前のn-1語にのみ依存すると仮定して言語の文をモデル化する n=3 のとき,tri-gram model, n=2のとき,bi-gram modelという。 「茶筌(奈良先端大で開発した形態素解析システム)」は bi-gram と tri-gram の混合を用いている。 文として単語列が与えられた際に最大の出現確率をもつ品詞列を求めることが目的 そのために、単語の出現確率や品詞の連接確率の積が最大になるような品詞列を求める
」は bi-gram と tri-gram の混合を用いている。 文として単語列が与えられた際に最大の出現確率をもつ品詞列を求めることが目的. そのために、単語の出現確率や品詞の連接確率の積が最大になるような品詞列を求める.")
23
以下で用いる記号の説明

24
確率最大化に基づく形態素解析 入力文(w1,n=w1,w2,…,wn)が与えられた時に、各単語の品詞(s1,n=s1,s2,…,sn)を求めたい。 確率に基づく方法では、入力文に対して生起確率が最大となる品詞列を求める 入力文が与えられた時に、品詞が s0,n+1 である確率 (条件付確率の定義) 上の式で、s0 および sn+1 は、文頭および文末を表す 特別な品詞
 上の式で、s0 および sn+1 は、文頭および文末を表す. 特別な品詞.")
25
前のページの式のそれぞれの項を以下のように簡単化する

26
前の式の中のそれぞれの確率は、次のようにして見積もる

27
確率値の計算の例 単語の生起確率 品詞の連接確率 例えば、「学校」という名詞がコーパス中に30回現れたとする
また、コーパス全体に現れる名詞の総数を10000回とする。 このとき、「学校」の名詞としての出現確率は、 品詞の連接確率 例えば、コーパス中に名詞が10000回出現し、その直後に格助詞が3000回出現したとする このとき、名詞と格助詞の連接確率は、

28
確率値からコストへの変換 形態素解析は、全体の生起確率が最大となるような品詞列を求めることに帰着される
確率を直接扱うと、長い文では、全体の生起確率が非常に小さい値となり、計算機でアンダーフローを起こす可能性がある 確率値のかわりに、以下のようにして実数(あるいは整数値)によるコストに変換することがよく行なわれる。 確率値を考え、その最大確率を与える品詞列を考えるかわりに、確率値の逆数の対数をとり、その最小値を求める。 これにより、かけ算ではなく加算によって最大確率の品詞列を求めることができるようになる。
によるコストに変換することがよく行なわれる。 確率値を考え、その最大確率を与える品詞列を考えるかわりに、確率値の逆数の対数をとり、その最小値を求める。 これにより、かけ算ではなく加算によって最大確率の品詞列を求めることができるようになる。")
29
確率値から対数値への 確率値最大の品詞列を求める問題を、確率値の対数をとることで、最小の対数値を求める問題に変更できる
結果として得られるのは、対数値の和の最小化問題

30
最大の確率(最小のコスト)をもつ品詞列の推法
入力文を単語に区切る方法は一意ではない(単語境界の曖昧性) 区切られた単語に対する品詞は一意ではない(品詞の曖昧性) 1通りの単語列(w1,w2,…,wn)およびそれに対する品詞列(s0, s1,…, sn+1)を考えると、その確率値は次のようになる つまり、単語生起確率と品詞の連接確率の積 (実際には、これらの対数の和で計算)
 区切られた単語に対する品詞は一意ではない(品詞の曖昧性) 1通りの単語列(w1,w2,…,wn)およびそれに対する品詞列(s0, s1,…, sn+1)を考えると、その確率値は次のようになる. つまり、単語生起確率と品詞の連接確率の積. (実際には、これらの対数の和で計算)")
31
最大確率の品詞列を求めることは、以下のような可能性のうち、最小コストの経路を求めるのと同じ問題

32
形態素解析の例 で くるま で くる くる まで 4200 3200 格助詞 0 1000 名詞 2500 700 助動詞 (連用) 0
1300 4500 文頭 3150 くる 動詞 カ変(基本) 450 2700 くる 動詞 五段(基本) 3000 2700 まで 格助詞 0 1400 5700 4550 1400 7100
 450 くる. 動詞. 五段(基本) 3000 まで. 格助詞. 0")
33
形態素解析の例 で くるま まつ で くる まで くる 4200 3200 6900 格助詞 0 1000 名詞 2500 700 動詞
五段(基本) 1900 800 で 助動詞 (連用) 0 1300 7900 1500 800 4500 文頭 3150 くる 動詞 カ変(基本) 450 2700 7250 まで 格助詞 0 1400 2700 5700 4550 くる 動詞 五段(基本) 3000 1400
 1900 で. 助動詞. (連用) 0 文頭 くる. 動詞. カ変(基本) 450 まで. 格助詞. 0 くる. 動詞. 五段(基本) 3000")
34
形態素解析の例 で くるま まつ まつ で くる くる まで 4200 3200 6900 格助詞 0 1000 名詞 2500 700
動詞 五段(基本) 1900 800 まつ 名詞 2500 600 1300 4500 文頭 3150 1500 で 助動詞 (連用) 0 くる 動詞 カ変(基本) 450 2700 1200 7300 1400 800 2700 8200 5700 4550 600 くる 動詞 五段(基本) 3000 まで 格助詞 0 7650 1400
 1900 まつ. 名詞. 2500 文頭 で. 助動詞. (連用) 0. くる. 動詞. カ変(基本) 450 くる. 動詞. 五段(基本) 3000. まで. 格助詞. 0")
35
形態素解析の例 で くるま まつ まつ で くる くる まで 4200 3200 6900 格助詞 0 1000 名詞 2500 700
動詞 五段(基本) 1900 800 まつ 名詞 2500 600 文末 500 7400 1300 4500 文頭 3150 1500 で 助動詞 (連用) 0 くる 動詞 カ変(基本) 450 2700 960 1200 7300 8260 1400 800 2700 5700 4550 くる 動詞 五段(基本) 3000 まで 格助詞 0 600 1400
 1900 まつ. 名詞. 2500 文末 文頭 で. 助動詞. (連用) 0. くる. 動詞. カ変(基本) 450 くる. 動詞. 五段(基本) 3000. まで. 格助詞. 0")
36
形態素解析の例 で くるま まつ で くる まつ くる まで 4200 3200 6900 格助詞 0 名詞 2500 1000 動詞
五段(基本) 1900 800 500 700 7400 1300 4500 文頭 3150 1500 文末 で 助動詞 (連用) 0 くる 動詞 カ変(基本) 450 2700 1200 600 7300 960 まつ 名詞 2500 1400 800 2700 5700 4550 くる 動詞 五段(基本) 3000 まで 格助詞 0 600 1400
 1900 文頭 文末. で. 助動詞. (連用) 0. くる. 動詞. カ変(基本) 450 まつ. 名詞. 2500 くる. 動詞. 五段(基本) 3000. まで. 格助詞. 0")
37
形態素解析の例 で くるま まつ で くる まつ くる まで 4200 3200 6900 格助詞 0 名詞 2500 1000 動詞
五段(基本) 1900 800 500 700 7400 1300 4500 文頭 3150 1500 文末 で 助動詞 (連用) 0 くる 動詞 カ変(基本) 450 2700 1200 600 7300 960 まつ 名詞 2500 1400 800 2700 5700 4550 くる 動詞 五段(基本) 3000 まで 格助詞 0 600 1400
 1900 文頭 文末. で. 助動詞. (連用) 0. くる. 動詞. カ変(基本) 450 まつ. 名詞. 2500 くる. 動詞. 五段(基本) 3000. まで. 格助詞. 0")
38
日本語形態素解析システム「茶筌」 実データから学習した確率に基づくコスト最小化に基づいた日本語形態素解析システム
以下の場所からフリーソフトとして、Windows版およびUnix版の「茶筌」が入手可能 現在は、約100万語の品詞情報付きのデータから学習している。 今回説明したような、直前の品詞からの接続確率だけでなく、次のように拡張されたモデルに基づいている 部分的に直前の2つの品詞列に基づく確率を用いている 一部の品詞については、品詞単位ではなく、単語単位に確率値を計算している

Similar presentations


アルゴリズム.>")
 情報工学科 木村昌臣 篠埜 功.>")









 http://www.info.kochi-tech.ac.jp/k1sakai/Lecture/COMP/2011/index.html.>")


 辻 慶太(水) http://slis.sakura.ne.jp/cje3.>")


