Download presentation
1
コンピュータ科学としての 分子コンピューティング
萩谷 昌己 東京大学 大学院情報理工学系研究科 コンピュータ科学専攻

2
分子コンピューティングとは 生体分子=情報処理装置 分子コンピューティングの目標 参考文献 化学反応の自律的制御 ⇒ 自身にコード化
微小・省エネルギー 超並列 分子の物理化学的性質 分子コンピューティングの目標 分子反応の持つ潜在的計算能力の理学的解明 分子反応に基づく新しい計算機能の工学的実現 参考文献 萩谷, 横森編: DNAコンピュータ, 培風館, 2001. DNA、RNA、タンパク質などの生体分子と通常分子の根本的な違いは、生体分子の持つ組み合わせてきな複雑さにあります。例えば、DNAなら4種類の塩基、タンパク質は20種類のアミノ酸の配列により複雑な情報を自由に表現することができます。さらに、生体分子は、この組合せ的な複雑さの中に、自分自身の化学反応を自律的に制御するための情報を、自分自身の中に符号化して格納することができます。 この絵はリボソームですが、mRNAという「入力」を(左上から)受け取り、アミノ酸を指定された順序で合成するという「処理」をほどこして、タンパク質を(右下へ)「出力」します。さらに、リボソーム自身はほとんどリボゾーマルRNAからできており、コードが反応を掌るという、われわれが日常使っているストアードメモリ方式の計算機と極めて類似した描像を持っています。 このように、個々の生体分子は計算能力を持った情報処理装置であり、生体はそのような情報処理装置の集合体であるとみなすことができます。 生体分子を情報処理装置と見た場合、従来のシリコンベースの計算機と比べるとかなり異なった特徴を持ちます。まず、サイズがナノメートルオーダーで微小であり、非常に少ないエネルギーで作動します。また、少ないスペースにアボガドロ数オーダーの大量の計算機を同時に持つことができます。分子は固定されておらず水溶液中で常に運動しています。そして、入出力をやはり分子で行うことができます。 分子計算とは、このような生体分子が潜在的に持っている計算能力を理学的に解明することと、これを利用して新しい計算機能を工学的に実現することを目的とする分野です。
受け取り、アミノ酸を指定された順序で合成するという「処理」をほどこして、タンパク質を(右下へ)「出力」します。さらに、リボソーム自身はほとんどリボゾーマルRNAからできており、コードが反応を掌るという、われわれが日常使っているストアードメモリ方式の計算機と極めて類似した描像を持っています。 このように、個々の生体分子は計算能力を持った情報処理装置であり、生体はそのような情報処理装置の集合体であるとみなすことができます。 生体分子を情報処理装置と見た場合、従来のシリコンベースの計算機と比べるとかなり異なった特徴を持ちます。まず、サイズがナノメートルオーダーで微小であり、非常に少ないエネルギーで作動します。また、少ないスペースにアボガドロ数オーダーの大量の計算機を同時に持つことができます。分子は固定されておらず水溶液中で常に運動しています。そして、入出力をやはり分子で行うことができます。 分子計算とは、このような生体分子が潜在的に持っている計算能力を理学的に解明することと、これを利用して新しい計算機能を工学的に実現することを目的とする分野です。")
3
分子コンピューティングの目標 分子反応の持つ計算能力の解析と その応用 分子反応に基づく新しい情報処理技術
分子による計算を活用した分子計測技術 ⇒ バイオテクノロジーへの応用 プログラムされた自己組織化や分子マシン ⇒ ナノテクノロジーへの応用 分子による進化的計算 ⇒ 分子進化工学への応用 分子反応に基づく新しい情報処理技術

4
関連分野 なまもの ソフトウェア 分子生物学 ゲノム情報 分子計算 進化的計算 分子進化工学 人工生命 分析 数理生物 合成 進化⊂計算

5
関連分野 分子エレクトロニクス ナノテクノロジー 量子コンピューティング 光コンピューティング 分子生物学・バイオテクノロジー
分子素子を用いた電子回路(既存の計算パラダイム) 分子回路の構成技術(ナノテクノロジー)としての分子コンピューティング 分子コンピューティングは分子エレクトロニクスを含むとも考えられる。 ナノテクノロジー 量子コンピューティング 光コンピューティング 分子生物学・バイオテクノロジー バイオインフォマティクス(ゲノム情報) 計算機技術の遺伝子情報解析への応用 ヒトゲノム・プロジェクトの一環 分子コンピューティングとは逆の方向だが、 分子コンピューティングの重要な応用分野と考えられる。 進化的計算・人工生命 人工分子進化(分子進化工学)
 分子回路の構成技術(ナノテクノロジー)としての分子コンピューティング. 分子コンピューティングは分子エレクトロニクスを含むとも考えられる。 ナノテクノロジー. 量子コンピューティング. 光コンピューティング. 分子生物学・バイオテクノロジー. バイオインフォマティクス(ゲノム情報) 計算機技術の遺伝子情報解析への応用. ヒトゲノム・プロジェクトの一環. 分子コンピューティングとは逆の方向だが、 分子コンピューティングの重要な応用分野と考えられる。 進化的計算・人工生命. 人工分子進化(分子進化工学)")
6
コンピュータ科学としての 分子コンピューティング
分子反応の持つ計算能力の解析 計算モデル・計算可能性・計算量 分子システム設計の計算論的側面 分子の設計・分子反応の設計 分子反応に基づく新しい情報処理技術 知的分子計測・分子メモリ 分子マシンの情報処理・生体内の情報処理 新しい計算パラダイム 膜コンピューティング、アモルファス・コンピューティング 光や量子との融合 分子エレクトロニクスとの融合

7
コンピュータ科学としての 分子コンピューティング
分子反応の持つ計算能力の解析 計算可能性・計算量 分子システム設計の計算論的側面 分子の設計・分子反応の設計 分子反応に基づく新しい情報処理技術 知的分子計測・分子メモリ 分子マシンの情報処理・生体内の情報処理 新しい計算パラダイム 膜コンピューティング、アモルファス・コンピューティング 光や量子との融合 分子エレクトロニクスとの融合

8
分子反応の持つ計算能力の解析 様々な計算モデル (計算モデルの)計算能力の解析 分子間の反応 vs. 分子内の反応 液相 vs. 固相
試験管、膜、細胞 他律的 vs. 自律的 (計算モデルの)計算能力の解析 計算可能性 計算量 --- 時間、領域 エラーや収量 --- 確率的な解析 現実の分子反応により忠実な解析へ
計算能力の解析. 計算可能性. 計算量 --- 時間、領域. エラーや収量 --- 確率的な解析. 現実の分子反応により忠実な解析へ.")
9
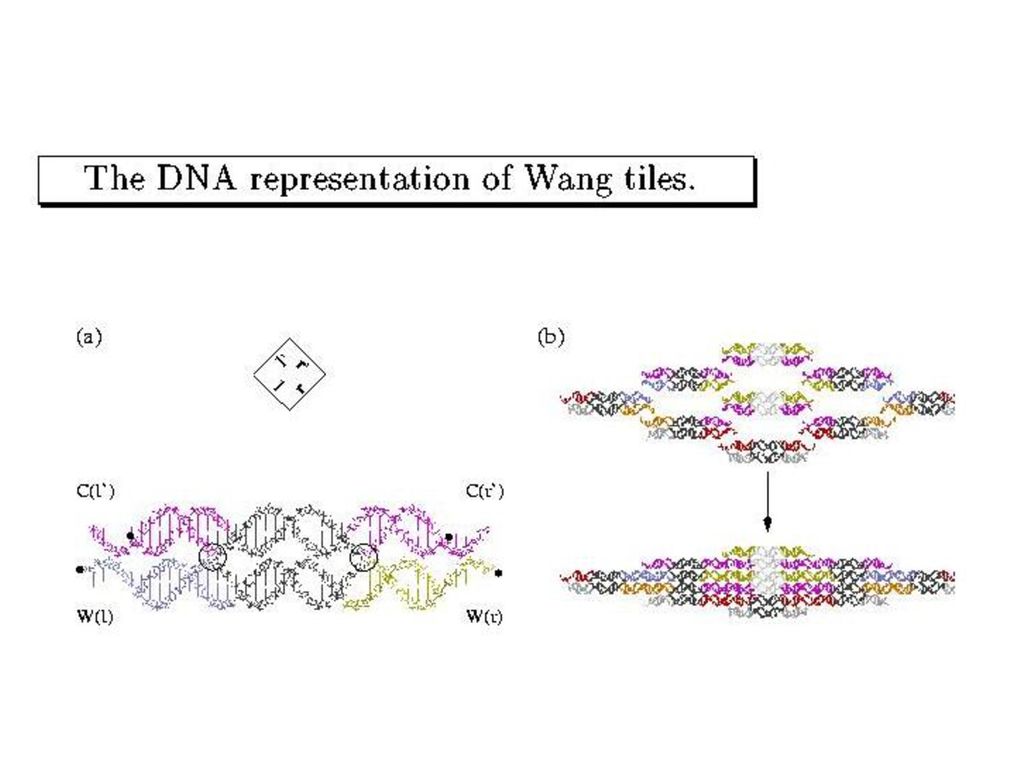
分子コンピューティング 様々な計算モデル(とその解析) Adleman-Lipton Seeman-Winfree
DNAの選択的ハイブリダイゼーションを利用した 解の候補のランダムな生成 データ並列計算による解の抽出 Suyama --- dynamic programming Sakamoto-Hagiya --- SAT Engine Seeman-Winfree 各種形態のDNA分子の自己組織化(self-assembly) 自己組織化による計算
 自己組織化による計算.")
10
分子コンピューティング 様々な計算モデル(とその解析) Head Ogihara-Ray Hagiya-Sakamoto Shapiro
遺伝子の組み換えによる言語の生成 Ogihara-Ray ブール回路の並列計算 Hagiya-Sakamoto 状態機械(Whiplash) Shapiro 有限オートマトン
 Shapiro. 有限オートマトン.")
11
Adleman-Liptonパラダイム Adleman (Science 1994) Lipton, et al. 分子による超並列計算
ハミルトン経路問題をDNAを用いて解く。 Lipton, et al. SAT問題をDNAを用いて解く。 分子による超並列計算 主として組み合わせ的最適化 DNAの自己会合によるランダムな生成 解の候補 = DNA分子 生物学実験技術を駆使した解の抽出 現状ではバイオテクノロジーのベンチマーク 遺伝子解析への応用を視野に入れた研究

12
Adlemanの最初のDNAコンピュータ
O0 O6 PCR PAGE AF-SEP O1 O2 O3 O4 O5 HP

13
Adleman による実験 実験操作へ 頂点3 頂点4 ATCGATCG TAAGATA TAGCATTC 有向辺3 4 ATCGATCG
(Science 1994) 4 3 1 start 6 goal 2 5 実験操作へ 頂点3 頂点4 ATCGATCG TAAGATA TAGCATTC 有向辺3 4 ハイブリダイゼーション ATCGATCG TAAGATA 抽出・検知 TAGCATTC 解分子
 start. 6. goal 実験操作へ. 頂点3. 頂点4. ATCGATCG. TAAGATA. TAGCATTC. 有向辺3 4. ハイブリダイゼーション. ATCGATCG. TAAGATA. 抽出・検知. TAGCATTC. 解分子.")
14
解の抽出・検知 PCR 長さ20 長さ140 頂点6 頂点0 ゲル電気泳動 頂点5の 相補配列 頂点1の 相補配列 磁石
頂点2を含む配列の抽出 各頂点について実行 解分子の抽出 磁石 頂点5を含む配列の抽出

15
Adleman-Liptonパラダイム 全ての解候補の生成 解の検査と抽出 解の検出 全ての 代入の生成 (Lipton 1995,
充足可能性問題) 0 0 0 0 変数Xn 変数X1 変数X2 変数X3 1 1 1 1 解の検査と抽出 Ti : 文字列の多重集合 (試験管) 解の検出 [Detect 命令] [Separate命令] T2 =+(T1, s) : s を含む配列の抽出 T2 =-(T1, s) : s を含まない配列の抽出 [Merge命令] T3 =T1 U T2 : T1 と T2 の混合 [Amplify命令] (T2, T3) =T1 : T1 の増幅(コピー)
 0. 0. 0. 0. 変数Xn. 変数X1. 変数X2. 変数X3. 1. 1. 1. 1. 解の検査と抽出. Ti : 文字列の多重集合 (試験管) 解の検出. [Detect 命令] [Separate命令] T2 =+(T1, s) : s を含む配列の抽出. T2 =-(T1, s) : s を含まない配列の抽出. [Merge命令] T3 =T1 U T2 : T1 と T2 の混合. [Amplify命令] (T2, T3) =T1 : T1 の増幅(コピー)")
16
SuyamaのDNAコンピュータ “counting” (Ogihara and Ray)
O(20.4n) molecules for n-variable 3-SAT “dynamic programming” (Suyama) 生成と選択の繰り返し 解の候補の部分的な生成 解の候補の選択 指数オーダーには変わりはないが、 O(20.4n) は O(2n) よりずっと少ない。 固相法 磁気ビーズによるアフィニティ・セパレーション 自動化に適している ⇒ Robot!
 molecules for n-variable 3-SAT. dynamic programming (Suyama) 生成と選択の繰り返し. 解の候補の部分的な生成. 解の候補の選択. 指数オーダーには変わりはないが、 O(20.4n) は O(2n) よりずっと少ない。 固相法. 磁気ビーズによるアフィニティ・セパレーション. 自動化に適している ⇒ Robot!")
17
基本演算とその実装 get (T, +s), get (T, -s) amplify (T, T1, T2, …Tn)
annealing immobilization cold wash hot wash get (T, +s) get (T, -s) amplify (T, T1, T2, …Tn) PCR and divide T T1, T2, …Tn append (T, s, e) e annealing and ligation s immobilization cold wash hot wash Taq DNA ligase
 get (T, -s) amplify (T, T1, T2, …Tn) PCR. and. divide. T. T1, T2, …Tn. append (T, s, e) e. annealing. and. ligation. s. immobilization. cold wash. hot wash. Taq DNA ligase.")
18
3CNF-SAT を解く DP的なDNA アルゴリズム

19
3CNF-SAT問題とその解

20
3CNF-SATを解くDP的アルゴリズム k’s loop: k ranges over variable indices
j’s loop: j ranges over clause indices if xk is the 3rd literal of the j-th clause then remove those assignments which satisfy neither the 1st nor the 2nd literal append XkF to the remaining assignments (do similarly if Øxk is the 3rd literal) k = 3 x3 X1T X2T X1T X2T X3F X1F X2T ) ( 3 2 1 x Ú Ø X1T X2F X3F X1T X2F X1F X2F ) ( 3 2 1 x Ú
 k = 3. x3. X1T X2T. X1T X2T X3F. X1F X2T. ) ( x. Ú. Ø. X1T X2F X3F. X1T X2F. X1F X2F. ) ( x. Ú.")
21
3CNF-SATを解くDP的アルゴリズム k’s loop: k ranges over variable indices
j’s loop: j ranges over clause indices if xk is the 3rd literal of the j-th clause then remove those assignments which satisfy neither the 1st nor the 2nd literal append XkF to the remaining assignments (do similarly if Øxk is the 3rd literal) k = 3 Øx3 X1T X2T ) ( 3 2 1 x Ø Ú X1F X2T X3T X1F X2T X1T X2F ) ( 3 2 1 x Ú X1FX2F X3T X1F X2F
 k = 3. Øx3. X1T X2T. ) ( x. Ø. Ú. X1F X2T X3T. X1F X2T. X1T X2F. ) ( x. Ú. X1FX2F X3T. X1F X2F.")
22
3CNF-SATを解くDP的アルゴリズム k’s loop: k ranges over variable indices
j’s loop: j ranges over clause indices if xk is the 3rd literal of the j-th clause then remove those assignments which satisfy neither the 1st nor the 2nd literal append XkF to the remaining assignments (do similarly if Øxk is the 3rd literal) k = 4 x4 X1F X2T X3T ) ( 4 3 2 x Ú Ø X1F X2F X3T ) ( 4 3 2 x Ú Ø X1T X2T X3F X4F X1T X2T X3F X1T X2F X3F ) ( 4 3 2 x Ú
 k = 4. x4. X1F X2T X3T. ) ( x. Ú. Ø. X1F X2F X3T. ) ( x. Ú. Ø. X1T X2T X3F X4F. X1T X2T X3F. X1T X2F X3F. ) ( x. Ú.")
23
10-variable and 43-clause instance of 3SAT

24
DNA Computer Robot based on MAGTRATIONTM (Prototype No.1)
")
25
DNAコンピュータのプログラミング protocol-level script-level Pascal/C-level
[Instrument] [Reset Counter] 0 [Home Position] 0 [MJ-Open Lid] ・・・ [Get1(0)] [Get2(1)] [Append(2)] [Exit] protocol-level (1-1-4) [MJ-Open Lid] Do 2 _SEND "LID OPEN" Do 10 _SEND "LID?" Wait_msec 500 _CMP_GSTR "OPEN" IF_Goto EQ 0 ;open Wait_msec 1000 Loop ; Time out End ;open script-level Pascal/C-level
] [Get2(1)] [Append(2)] [Exit] protocol-level. (1-1-4) [MJ-Open Lid] Do 2. _SEND LID OPEN Do 10. _SEND LID Wait_msec 500. _CMP_GSTR OPEN IF_Goto EQ 0 ;open. Wait_msec Loop. ; Time out. End. ;open. script-level. Pascal/C-level.")
26
Akira Suyama 東大教授(生物物理)
")
27
ヘアピン・エンジン(SATエンジン) 特平11-165114 Sakamoto et al., Science, May 19, 2000.
DNAのヘアピン構造を利用した選択 ヘアピンの制限酵素切断 exclusive PCR 3-SAT 各節から選んだリテラルから成る一本鎖 DNA 相補的なリテラル = 相補的配列 矛盾したリテラルの選択 ⇒ ヘアピン 6-variable 10-clause 3-SAT Problem SAT計算の本質的部分 = ヘアピン形成 節や変数の数によらないステップ数 Autonomous molecular computation

28
(a∨b∨c)∧(¬d∨e∨¬f)∧ … ∧(¬c∨¬b∨a)∧ ...
制限酵素による切断 exclusive PCR b ¬b

30
ヘアピン構造による選択 制限酵素による切断 リテラルを表す配列中に 制限酵素サイトを挿入 Exclusive PCR
増幅率が低い。 exclusive PCRでは、各サイクルで溶液を薄めることにより、ヘアピンと非ヘアピンの増幅率の差を大きくしている。 実験操作の数は変数や節の数に依存しない。

31
Kensaku Sakamoto 東大&理研(生物化学)
")
32
Adleman-Liptonパラダイムに関する 現在のコンセンサス
電子コンピュータを凌駕するには程遠い。 スケールアップ問題 「分子が計算する」ことの proof of conceptとしては重要。 少なくとも、バイオテクノロジーの ベンチマークとして使うことができる。 さらに、遺伝子計測への応用(Suyama)。
。")
33
Seeman-Winfreeの DNAの自己組織化による計算
3分岐 ... 線形 .... ヘアピン .... DX(ダブルクロスオーバー) 様々なDNA構造分子
 様々なDNA構造分子.")
37
The experimental result will be presented at DNA9, 2003.

38
DNA9, 2003

39
LaBeanたちによるtriple crossover分子

40
Headの遺伝子組み換えによる計算 数学的モデル(スプライシング・モデル) スプライシング操作 制限酵素とライゲースによる遺伝子組み換えの
CC C TTAA G CC x= GG G AATT C GG EcoRI y= AA G AATT C TT TT C TTAA G AA AATT CTT GAA AAG TTC TTAA GGG CCC TTAA AATT CGG GCC z= GGG AATT CTT CCC TTAA GAA w= AAG AATT CGG TTC TTAA GCC

41
組み換えによる言語の生成 スプライシング規則: r = u1$u2#u3$u4
(x1u1u2x2, y1u3u4y2) |-r (x1u1u4y2, y1u3u2x2) R: スプライシング規則の集合 A: 文字列の集合(公理) L: RとAによって生成される言語 xÎA ならば、 xÎL x, yÎL かつ rÎR かつ (x, y)|-r (z,w) ならば、 z,wÎL RとAが有限ならば、Lは正則になる。
 |-r (x1u1u4y2, y1u3u2x2) R: スプライシング規則の集合. A: 文字列の集合(公理) L: RとAによって生成される言語. xÎA ならば、 xÎL. x, yÎL かつ rÎR かつ (x, y)|-r (z,w) ならば、 z,wÎL. RとAが有限ならば、Lは正則になる。")
42
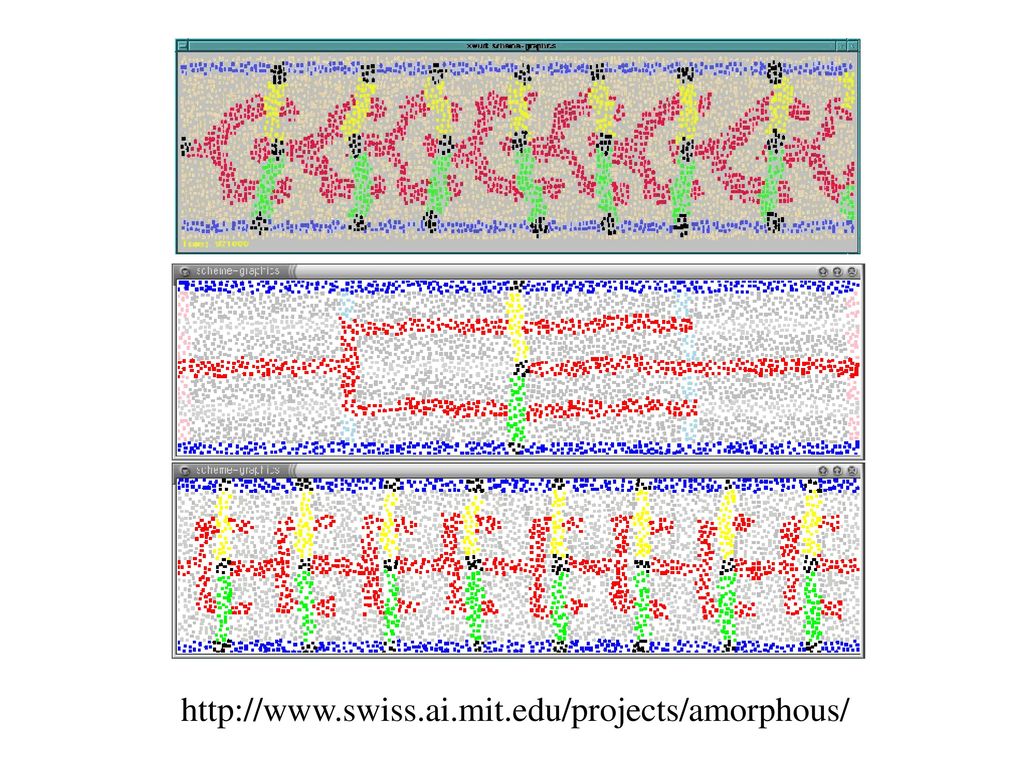
分子計算の計算可能性 DNAの自己組織化の計算可能性 Winfreeの結果 遺伝子組み換えの計算可能性 スプライシング・モデルの様々な拡張

43
Winfreeの結果 (線形)構造分子によって生成される言語族 =正則言語族 (線形+ヘアピン+3分岐)構造分子によって 生成される言語族
=文脈自由言語族 (線形+DX)構造分子によって =帰納的可算言語族 =チューリング計算可能
構造分子によって. =帰納的可算言語族. =チューリング計算可能.")
44
Winfreeのモデルによる計算過程の例
c = f(a,b) d = g(a,b) c d a b a b Initial Configuration 1次元セルオートマトンの模倣
 d = g(a,b) c. d. a. b. a. b. Initial Configuration. 1次元セルオートマトンの模倣.")
45
Erik Winfree Caltech, Assistant Professor (CS) MacArthur Fellow
Presidential Early Career Award

46
スプライシング・モデルの拡張 いくつかの答え: 環状分子 マルチ試験管 時間差 スプライシング・モデル の生成能力 < 正則言語族
< 正則言語族 (スプライシング)+α? = 万能計算能力 いくつかの答え: 環状分子 マルチ試験管 時間差
+α = 万能計算能力. いくつかの答え: 環状分子. マルチ試験管. 時間差.")
47
環状組換えシステム プラスα として 環状文字列(環状DNA)を用いることを許す。 終端記号と非終端記号の区別を許す。
( e.g. 大腸菌染色体とFプラスミドの組換え ) x u u x u u x 1 1 4 1 1 2 2 u u 3 4 u x 2 2 u 3 y スプライシング規則: u1$u2#u3$u4 y
 x. u. u. x. u. u. x u. u u. x u. 3. y. スプライシング規則: u1$u2#u3$u4. y.")
48
分子計算の計算量 時間 領域(=並列度) トレードオフの解析が重要 実験操作の回数 各操作に必要な時間 分子の数 分子の大きさ(長さ)
分子の計算能力の解析にはより本質的 領域(=並列度) 分子の数 最大 トータル 分子の大きさ(長さ) トレードオフの解析が重要
 分子の数. 最大. トータル. 分子の大きさ(長さ) トレードオフの解析が重要.")
49
計算量の解析 Reif (SPAA’95) Beaver (DNA1, 1995) Rooß and Wagner (I&C, 1996)
A nondeterministic Turing machine computation with input size n, space s and time 2O(s) can be executed in our PAM Model using O(s) PA-Match steps and O(s log s) other PAM steps, employing aggregates of length O(s). Beaver (DNA1, 1995) Polynomial-step molecular computers compute PSPACE. Rooß and Wagner (I&C, 1996) Exactly the problems in PNP=DP2 can be solved in polynomial time using Lipton’s model.
 can be executed in our PAM Model using O(s) PA-Match steps and O(s log s) other PAM steps, employing aggregates of length O(s). Beaver (DNA1, 1995) Polynomial-step molecular computers compute PSPACE. Rooß and Wagner (I&C, 1996) Exactly the problems in PNP=DP2 can be solved in polynomial time using Lipton’s model.")
50
Rooß and Wagner (I&C, 1996) Exactly the problems in PNP=DP2 can be solved in polynomial time using Lipton’s model. BIO({UN,BX,IN},{EM})-P = PNP= DP2 UN: union (merge) T3 =T1 U T2 BX: bit extraction (separate) T2 =+(T1, s) T2 =-(T1, s) IN: initialization (random generation) EM: emptyness test (detect) -P: polynomial time PNP: polynomial time with NP-oracle
-P = PNP= DP2. UN: union (merge) T3 =T1 U T2. BX: bit extraction (separate) T2 =+(T1, s) T2 =-(T1, s) IN: initialization (random generation) EM: emptyness test (detect) -P: polynomial time. PNP: polynomial time with NP-oracle.")
51
計算量の解析 Rothemund and Winfree (STOC 2000)
For any f (N) non-decreasing unbounded computable functions, the number of tiles required for the self-assembly of an N×N square is bounded infinitely often by f (N). Winfree, Eng and Rozenberg (DNA6, 2000) Linear assembly of string tiles can generate the output languages of finite-visit Turing Machines.
 non-decreasing unbounded computable functions, the number of tiles required for the self-assembly of an N×N square is bounded infinitely often by f (N). Winfree, Eng and Rozenberg (DNA6, 2000) Linear assembly of string tiles can generate the output languages of finite-visit Turing Machines.")
52
反応のエラーと収量 収量 エラー 確率的な解析 平衡 --- 平衡定数 (K) 平衡に到達する時間 --- 反応速度 (k)
例: A « B [B] = (K/(1+K))(1-e-(k+k-1) t ) K = k/k-1 エラー 例: ミス・ハイブリダイゼーション エラーの確率は0にはならない。 確率的な解析
)(1-e-(k+k-1) t ) K = k/k-1. エラー. 例: ミス・ハイブリダイゼーション. エラーの確率は0にはならない。 確率的な解析.")
53
確率的な解析 Karp, Keynon and Waarts (SODA’96) Kurtz (DNA2, 1996)
The number of extract operations required for achieving error-resilient bit evaluation is Q(éloge dù×élogg dù). Kurtz (DNA2, 1996) thermodynamical analysis of path formation in Adleman’s experiment time needed to form a Hamiltonian path --- W(n 2) Winfree (1998, Ph.D. Thesis) thermodynamical analysis of DNA Tiling Rose, et al. (GECCO’99, etc.) computational incoherency (thermodynamical analysis of mis-hybridization)
. Kurtz (DNA2, 1996) thermodynamical analysis of path formation in Adleman’s experiment. time needed to form a Hamiltonian path --- W(n 2) Winfree (1998, Ph.D. Thesis) thermodynamical analysis of DNA Tiling. Rose, et al. (GECCO’99, etc.) computational incoherency (thermodynamical analysis of mis-hybridization)")
54
Kurtz (DNA2, 1996) time needed to form a Hamiltonian path --- W(n 2)
Line digraph ávñ: the set of molecules that represent paths containing v at an interior vertex ávñ(t) = t / (t+n-1)(n-1) [e0,n-1]: the path from 0 to n-1 [e0,n-1] £ ávñ The W(n 2) lower bound follows immediately. n-1
 = t / (t+n-1)(n-1) [e0,n-1]: the path from 0 to n-1. [e0,n-1] £ ávñ. The W(n 2) lower bound follows immediately. n-1.")
55
Kurtz (DNA2, 1996) Simple feedback digraph [e0,n-1] £ 1 / ((2n-4)2n-3)
![Kurtz (DNA2, 1996) Simple feedback digraph [e0,n-1] £ 1 / ((2n-4)2n-3)](http://slidesplayer.net/slide/11558024/62/images/55/Kurtz+%28DNA2%2C+1996%29+Simple+feedback+digraph+%5Be0%2Cn-1%5D+%C2%A3+1+%2F+%28%282n-4%292n-3%29.jpg "Kurtz (DNA2, 1996) Simple feedback digraph [e0,n-1] £ 1 / ((2n-4)2n-3)")
56
Complexity Analysis of SAT Engine

57
Hairpin Formation Jacobson-Stockmayer equation Error probability
n : hairpin length the probability that the two ends come close 1/n 1.5 t : time for hairpin formation the ratio of hairpins 1-exp(-t /n 1.5) Error probability e : the probability that hairpin formation fails (false positive) exp(-t /n 1.5) < e t > n 1.5 ln(1/e )
 Error probability. e : the probability that hairpin formation fails (false positive) exp(-t /n 1.5) < e. t > n 1.5 ln(1/e )")
58
Stepwise Formation of Assignments
M : number of assignments M / 3: number of copies of each literal n : number of clauses Error probability p : the probability of correct hybridization p = 1 / (3+a) e : the probability of no correct assignment (false negative) (1-p n) M < e M > (3+a) ln(1/e )
 e : the probability of no correct assignment (false negative) (1-p n) M < e. M > (3+a) ln(1/e )")
59
One-step Formation of Assignments
Error probability The volume gets larger as the number of clauses gets larger. p : the probability of correct hybridization p = f (t /n) / 3 f (x) ® 1 as x ® ¥ Time is proportional to the number of clauses. The number of assignments is the same as in the case of stepwise formation.
 / 3. f (x) ® 1 as x ® ¥ Time is proportional to the number of clauses. The number of assignments is the same as in the case of stepwise formation.")
60
Overall Analysis Error probability Orders
e 1 : the number of molecules that fail to form hairpin (false positive) M exp(-t /n 1.5) < e 1 e 2 : the probability of no correct assignment (false negative) M = (3+a) ln(1/e 2) t > (1+a) n ln(1/e 1 )+ln(ln(1/e 2 ))+n 2.5 ln(3+a) Orders time --- O(n 2.5) number of molecules --- O((3+a) n ln(1/e 2))
 M exp(-t /n 1.5) < e 1. e 2 : the probability of no correct assignment (false negative) M = (3+a) ln(1/e 2) t > (1+a) n ln(1/e 1 )+ln(ln(1/e 2 ))+n 2.5 ln(3+a) Orders. time --- O(n 2.5) number of molecules --- O((3+a) n ln(1/e 2))")
61
コンピュータ科学としての 分子コンピューティング
分子反応の持つ計算能力の解析 計算可能性・計算量 分子システム設計の計算論的側面 分子の設計・分子反応の設計 分子反応に基づく新しい情報処理技術 知的分子計測・分子メモリ 分子マシンの情報処理・生体内の情報処理 新しい計算パラダイム 膜コンピューティング、アモルファス・コンピューティング 光や量子との融合 分子エレクトロニクスとの融合

62
分子プログラミング 分子システム設計の計算論的側面 分子の設計 分子反応の設計 分子マシン DNAの場合 = 配列設計
構造 ⇒ 配列(inverse folding) 自己組織化パターンの設計・分子マシンの設計 分子反応の設計 反応条件や操作順序の設計 シミュレーション・ツール 分子マシン 分子プログラミングの現在の目標の一つ
 自己組織化パターンの設計・分子マシンの設計. 分子反応の設計. 反応条件や操作順序の設計. シミュレーション・ツール. 分子マシン. 分子プログラミングの現在の目標の一つ.")
63
配列設計 配列セットの評価 配列セットの探索 逆問題 ミスハイブリダイゼーションの回避
ハミング距離 エネルギー計算 ⇒ mfold(Zuker)、Vienaパッケージ 一様なTm(融解温度、melting temperature) 配列セットの探索 遺伝的アルゴリズム 符号理論 --- 有田のテンプレート法 逆問題 構造 ⇒ 配列(inverse folding) Vienaグループ
、Vienaパッケージ. 一様なTm(融解温度、melting temperature) 配列セットの探索. 遺伝的アルゴリズム. 符号理論 --- 有田のテンプレート法. 逆問題. 構造 ⇒ 配列(inverse folding) Vienaグループ.")
64
[AT]か [GC] の位置を全配列共通にする
テンプレート法 Arita and Kobayashi, 2002 [AT]か [GC] の位置を全配列共通にする (これをテンプレートと呼ぶ) 例. 011010 より ACCTGA, TGCTCA, TCGACA, etc. → こうすると、全配列の融解温度は揃う。
![[AT]か [GC] の位置を全配列共通にする](http://slidesplayer.net/slide/11558024/62/images/64/%5BAT%5D%E3%81%8B+%5BGC%5D+%E3%81%AE%E4%BD%8D%E7%BD%AE%E3%82%92%E5%85%A8%E9%85%8D%E5%88%97%E5%85%B1%E9%80%9A%E3%81%AB%E3%81%99%E3%82%8B.jpg "テンプレート法. Arita and Kobayashi, [AT]か [GC] の位置を全配列共通にする. (これをテンプレートと呼ぶ) 例 より. ACCTGA, TGCTCA, TCGACA, etc. → こうすると、全配列の融解温度は揃う。")
65
スタッキング・エネルギー -ΔG kcal/mol (DNA/DNA) by Sugimoto et al. 2 1
AA AT TA CA CT GA GT CG GC GG TT TA AT GT GA CT CA GC CG CC

66
どうずらしても、連結した部分を考えても、
ミスマッチを含むテンプレート 上手にテンプレートを選べば、 シフト、リバースの際でも必ずミスマッチをもつ。 例: 110100のとき 110100 110100 110100 110100 110100 110100 110100 どうずらしても、連結した部分を考えても、 ミスマッチは最低2個存在

67
テンプレートの選び方 テンプレート T を、以下のパターンと最低 d 個のミスマッチを持つように選ぶ。 TR TTR 、 TRT
TT、 TRTR 注: TRはTの逆配列。T=110100なら、001011

68
テンプレートの例 長さ 6 (ミスマッチ 2) 110100 (26個中) 長さ 11 (ミスマッチ 4)
110100 (26個中) 長さ 11 (ミスマッチ 4) , , (211個中) 長さ 23 (ミスマッチ 9) , , (223個中)
 長さ 11 (ミスマッチ 4) , , (211個中) 長さ 23 (ミスマッチ 9) , , (223個中)")
69
DNA配列の設計法 “テンプレート + 誤り訂正符号” 1 1 0 1 0 0 (テンプレート)
誤り訂正符号は何でも利用可。 BCH 符号 Golay 符号 Hamming 符号 など。 A T C A G G (DNA配列) (テンプレート) (任意の符号語)
 (テンプレート) (任意の符号語)")
70
Masanori Arita 東大助教授(バイオインフォマティクス)
")
71
Inverse Folding Vienaグループ McCaskillのアルゴリズムの利用 コスト関数の最小化による配列の探索
Ω : 目的の構造 x: 配列 E(x,Ω): x におけるΩ の自由エネルギー G(x): 配列 x の集団自由エネルギー(McCaskill) p: x におけるΩ の確率
: x におけるΩ の自由エネルギー. G(x): 配列 x の集団自由エネルギー(McCaskill) p: x におけるΩ の確率.")
72
左の図の木の辺の数字はエネルギーの壁の高さ。頂点の数字は安定度の順位。

73
各温度でのエネルギーの壁の高さを表すグラフ。

75
分子反応の設計 反応条件 操作の順序 シミュレーション 温度 塩濃度 時間 e-PCR VNA
VNA

76
VNA: 仮想 DNAのシミュレータ 抽象的だが、十分に物理的 反応 抽象モデルと実際の反応との間の橋渡し
分子 ― 仮想ストランドのハイブリッド abcd || CDEF 反応 hybridization denaturation restriction ligation self-hybridization extension

77
VNA (続き) 目的 実行例 実装 DNA計算の方式の実現可能性の検証 生物学実験の妥当性の検証 (e.g., PCR実験)
生物学実験の適切なパラメータの探索 実行例 OgiharaとRayによるブール式の計算 Winfreeによるdouble-crossover unitの生成 PCR実験 実装 Java ⇒ アプレットとして実行可能

78
VNA (続き) 方法 組み合せ的爆発の回避 融合 シミュレーション技術における貢献 GAによるパラメータ探索 組み合せ的数え上げ
連続的シミュレーション (微分方程式) 組み合せ的爆発の回避 シミュレーション技術における貢献 閾値 確率的 GAによるパラメータ探索 PCR実験の増幅率の最適化 融合
 組み合せ的爆発の回避. シミュレーション技術における貢献. 閾値. 確率的. GAによるパラメータ探索. PCR実験の増幅率の最適化. 融合.")
80
コンピュータ科学としての 分子コンピューティング
分子反応の持つ計算能力の解析 計算可能性・計算量 分子システム設計の計算論的側面 分子の設計・分子反応の設計 分子反応に基づく新しい情報処理技術 知的分子計測・分子メモリ 分子マシンの情報処理・生体内の情報処理 新しい計算パラダイム 膜コンピューティング、アモルファス・コンピューティング 光や量子との融合 分子エレクトロニクスとの融合

81
分子反応に基づく新しい 情報処理技術 知的分子計測・分子メモリ 分子マシンの情報処理・生体内の情報処理 新しい計算パラダイム
ブール式の学習の遺伝子発現解析への応用 分子マシンの情報処理・生体内の情報処理 DNAナノテクノロジー: 構造からマシンへ ナノテクノロジーにおけるコンピュータ科学(者) 新しい計算パラダイム 膜コンピューティング アモルファス・コンピューティング 光や量子との融合 分子エレクトロニクスとの融合
 新しい計算パラダイム. 膜コンピューティング. アモルファス・コンピューティング. 光や量子との融合. 分子エレクトロニクスとの融合.")
82
ブール式の学習の遺伝子発現解析への応用 知的DNAチップの提案 知的DNAチップの遺伝子発現解析への応用の 提案 3つ手法の組み合わせ
(例からのブール式の帰納的学習) DNAチップ技術 知的DNAチップ実現方法 知的DNAチップの遺伝子発現解析への応用の 提案
 DNAチップ技術. 知的DNAチップ実現方法. 知的DNAチップの遺伝子発現解析への応用の. 提案.")
83
DNA計算を用いた遺伝子発現解析の 情報処理
直接入力: 遺伝子の発現 DNAコンピュータ 出力: DNAチップ上 での出力 DNA符号化数 (Encode) GGGGGGGG ATATCCCC CCCCTTTT 試験管内での情報処理 in vitro DNA分子の直接入力 超並列性
 GGGGGGGG. ATATCCCC. CCCCTTTT. 試験管内での情報処理. in vitro. DNA分子の直接入力. 超並列性.")
84
知的DNAチップ “(Dcn1∧¬Dcn2)∨Dcn3” “Dcn1∨Dcn3” “¬Dcn1∨ (Dcn2 ∧ ¬Dcn3)” Dcn3
marker stopper ¬Dcn2 Dcn1 label Dcn3 marker stopper Dcn1 label label ¬Dcn3 Dcn2 marker stopper ¬Dcn1

85
DNAナノテクノロジー DNAによる自己組織化
DNAの網 分子糊としてのDNA DNAによるナノ粒子の自己組織化 DNAによるナノワイアの自己組織化 DNAタイル DNA自身による構造形成 プログラムされた自己組織化

86
ここで、DNAの大きさについて Seeman先生 二本鎖の直径は2nm。 一回転が10~10.5ベースペア。
スタックの幅が0.34nm、従って、一回転が3.5nmくらい。 Seeman先生

87
DNAの網 (阪大・産研・川合研究室) SiO2/Si基盤 親水性のあるSiO2基板上にのみネットワークを形成 写真はμメートル四方

88
DNAによるナノ粒子の自己組織化初期の研究
C. A. Mirkin et al. DNA-based method for rationally assembling nanoparticles into macroscopic materials. Nature 382, (1996) A. P. Alivisatos et al. Organization of ‘nanocrystal molecules’ using DNA. Nature 382, (1996)
 A. P. Alivisatos et al. Organization of ‘nanocrystal molecules’ using DNA. Nature 382, (1996)")
89
ナノ粒子:C. A. Mirkin et al. Nature (1996)
直径13nm

90
ナノ粒子:A. P. Alivisatos et al. Nature (1996)
")
91
ナノ粒子からワイヤへ E. Braun et al. Nature (1998)
電極間の距離は12~16μm。 λ-DNA ワイヤの長さは12μm、直径は100nm。 銀イオン

92
ナノワイアの自己組織化 N. I. Kovtyukhova and T. E. Mallouk
Nanowires as Building Blocks for Self-Assembling Logic and Memory Circuits Chem. Eur. J., 8, (2002) ワイアの直径は15nmから350nm。
 ワイアの直径は15nmから350nm。")
93
Winfree-SeemanのDNAタイル
(double crossover分子)
")
94
Journal of Nanoparticle Research 4: 313-317 (2002)
金のナノパーティクル 直径は1.4nm S. Xiao et al. Journal of Nanoparticle Research 4: (2002)
")
95
Nadrian Seeman New York University, Professor (chemistry)
1995 Feynman Prize in Nanotechnology

96
様々な分子マシン

97
SeemanのDNAモーター 2状態のDX分子

98
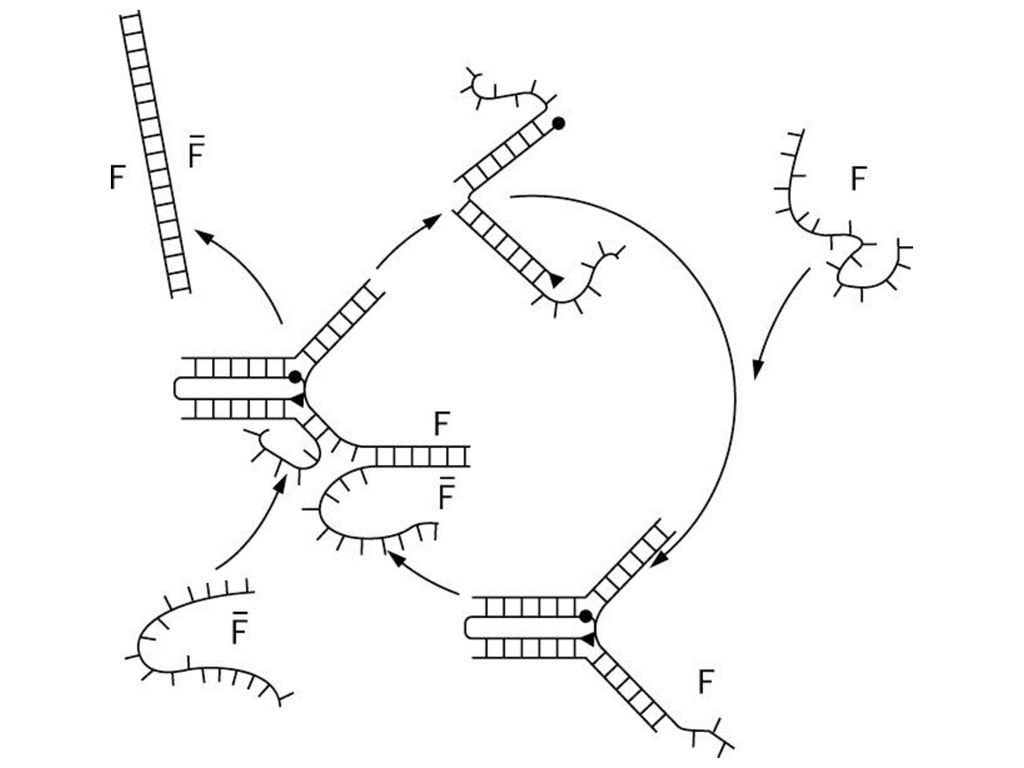
1) 2) Komiya et al. Whiplash PCR (WPCR) B B A C B A B A C
: stopper sequence B 1) B A C B A B A C 2) This figure shows the scheme of successive transitions. The head A anneals onto the transition table, and then the new state B is polymerized. After the polymerization, the formed hairpin structure is denatured, and the head B is ready for the next transition. Komiya et al.
 B. A. C. B. A. B. A. C. 2) This figure shows the scheme of successive transitions. The head A anneals onto the transition table, and then the new state B is polymerized. After the polymerization, the formed hairpin structure is denatured, and the head B is ready for the next transition. Komiya et al.")
99
3) 4) Whiplash PCR (WPCR) B A B A C B B A C C
The head B, now the current state of the machine, searches and anneals onto the next position in the transition table. The annealing of “B” allows the next state C to be newly polymerized. By iterating this “Annealing, Polymerization, and Denaturation” cycle according to the transition table, DNA molecules perform successive state transitions. B A C 4) C
 C.")
100
Polymerization Stop I explain the basic biochemical reaction composing Whiplash PCR. Each state is encoded by a 15-nucleotide sequence. A sequence at the 3’-end of a DNA molecule works as the head of a state machine, simultaneously representing a current state. A concatenation of two states, termed “state pair”, defines a transition rule. A transition table is represented by a sequence of transition rules. The head anneals onto its complementary sequence in the transition table by forming a hairpin structure intramolecularly, and then a DNA polymerase catalyzes the polymerization of the new state. If the reaction mixture doesn’t contain dTTP, polymerization will stop exactly before the repeated “A”, the stopper sequence. We call this method “Polymerization Stop”.

101
Back-hybridization B A B A C B B A C B A C
Note here that, the new state B can anneal not only onto the next position, but also onto the previous position where B was just polymerized. We call this kind of hairpin formation “back-hybridization”. Back-hybridization does not trigger any polymerization, but may cause a reduction in the efficiency of Whiplash PCR. Distribution of competing alternative hairpin forms and probability of success in transitions should be estimated. Competing Alternative Hairpin Forms

102
Temperature optimization for WPCR
・8 M urea 8% PAGE Komiya, et al. not incubated (℃) This figure shows temperature optimization for Whiplash PCR of 2 rounds on liquid phase with PLATINUM Pfx DNA polymerase. After denaturation at high temperature, transitions were performed under the isothermal condition. Bands that appeared at the highest position are the DNA molecules before transitions. Those at the lowest position are the molecules that finished the 1st round of transitions. And those at the middle position are the molecules that accomplished the 2nd round. The middle band with the highest intensity appeared in the lane of 78℃. Note that, under the thermal cycle schedule like normal PCR, the efficiency decreases. This result is supported by the statistical thermodynamic analysis recently reported in Physical Review E by John A.Rose. Thermal schedule 94℃ for 1 min. ↓ x ℃ for 5 min. x =59.8 ~ 92.2 in 1X Pfx buffer (the composition unknown) 1 mM MgSO4 0.2 mM dATP, dCTP, dGTP 1.5 units Platinum Pfx DNA polymerase
 This figure shows temperature optimization for Whiplash PCR. of 2 rounds on liquid phase with PLATINUM Pfx DNA polymerase. After denaturation at high temperature, transitions were performed under the isothermal condition. Bands that appeared at the highest position are the DNA molecules. before transitions. Those at the lowest position are the molecules that finished the 1st round of transitions. And those at the middle position are the molecules that accomplished the 2nd round. The middle band with the highest intensity appeared in the lane of 78℃. Note that, under the thermal cycle schedule like normal PCR, the efficiency decreases. This result is supported by the statistical thermodynamic analysis recently reported in Physical Review E by John A.Rose. Thermal schedule. 94℃ for 1 min. ↓ x ℃ for 5 min. x =59.8 ~ in 1X Pfx buffer. (the composition unknown) 1 mM MgSO mM dATP, dCTP, dGTP. 1.5 units Platinum Pfx DNA polymerase.")
103
・12% PAGE Successful implementation of transitions Komiya, et al.
( bp ) 155 140 125 110 This picture shows the successful implementation of 8 successive transitions. PCR products are analyzed by 12% polyacrylamide gel electrophoresis. In all lanes from 1 to 8, bands appeared at the positions of the expected length, respectively. The band in the lane i indicates there exist DNA molecules that finished the transition of the ith round and up. We excised the band in the lane 8, and confirmed the implementation of 8 successive transitions by sequencing analysis. 95 80 65 50
 This picture shows the successful implementation of 8 successive transitions. PCR products are analyzed by 12% polyacrylamide gel electrophoresis. In all lanes from 1 to 8, bands appeared at the positions of the expected length, respectively. The band in the lane i indicates there exist DNA molecules that finished the transition of the ith round and up. We excised the band in the lane 8, and confirmed the implementation of 8 successive transitions by sequencing analysis")
104
Ken Komiya 東大(生物化学)
")
105
ShapiroのDNAオートマトン IIS型制限酵素 認識部位 スペーサ a’ 入力の残り <S,a> <S,a>
遷移分子 a’ 入力の残り 入力の残り <S’,a’> 入力文字a’の配列は、各S’に対して<S’,a’>を含んでいる。 遷移分子は、スペーサを調整して、適切な個所で切断する。

106
ShapiroのDNAオートマトン Nature 2001 2入力文字、2状態 FokI a=CTGGCT b=CGCAGC
5’-p…22…GGATGTAC 3’-GGT…22…CCTACATGCCGAp S0,a→S0 5’-p…22…GGATGACGAC 3’-GGT…22…CCTACTGCTGCCGAp S0,a→S1

107
ギネスブック認定 (世界最小のコンピュータ)
")
108
YurkeのDNAピンセット

110
三状態機械

112
Seeman: DNAによるDXの制御

113
System to Test the PX-JX2 Device

114
AFM Evidence for Operation
of the PX-JX2 Device Yan, H., Zhang, X., Shen, Z. & Seeman, N.C. (2002), Nature 415,
, Nature 415,")
115
ナノテクノロジーにおける コンピュータ科学(者)
Ralph C. Merkle 元は暗合の専門家 Biotechnology as a route to nanotechnology, Trends in Biotechnology, July 1999, Vol.17 No.7, pages 2000年4月1日のHofstadter Symposium J. Storrs Hall (Josh) 元は並列計算? sci.nanotech の管理人 Utility Fog (万能霧)で有名 Markus Krummenacker
 元は並列計算? sci.nanotech の管理人. Utility Fog (万能霧)で有名. Markus Krummenacker.")
116
Weiss:微生物論理ゲート Engineered communications for microbial robotics
プラスミドに、蛍光タンパクの遺伝子と、転写制御タンパクの遺伝子を組み込んで、別々の大腸菌に形質転換。 論理素子(インバーター)を実現
を実現")
117
DNA8, 2002

118
新しい計算パラダイム 膜コンピューティング アモルファス・コンピューティング その他にも… Paun MIT のグループ
Abelson と Sussman Knight Utility Fog にも影響を受けたらしい。 その他にも… Smart Dust Programmable Matter Quantum-Dot Cell Automaton …

119
細胞膜モデル G. Paun (1998) 細胞膜(membrane)による計算過程の制御 スーパーセルシステム=万能計算モデル (例)
G=(V,μ, M ,..., M , (R ,ρ ),...,(R ,ρ ),4) 1 4 1 4 1 4 V={a,b,b',c,f} アルファベット μ=[ [ [ ] [ ] ] ] 膜構造 1 2 3 3 4 4 2 1 M 膜 i 内要素の多重集合 i (R , ρ ) 膜 i 内の規則の順序集合 i i
,...,(R ,ρ ),4) V={a,b,b ,c,f} アルファベット. μ=[ [ [ ] [ ] ] ] 膜構造 M. 膜 i 内要素の多重集合. i. (R , ρ ) 膜 i 内の規則の順序集合. i. i.")
120
細胞膜モデルによる n の計算 1 1 4 4 3 2 2 1 1 4 4 2 a, f b' f a ->b' a ->bδ
f ->ff n+1 2 3 b ->b' b ->b(c, in ) (f->ff)>(f ->aδ) b ->b' b ->b(c, in ) (f->ff)>(f ->aδ) 4 4 2 2 1 1 n+1 4 n+1 b a 4 b f n n+1 n+1 2 (n+1) 2 2 c c a 2 b ->b' b ->b(c, in ) (f->ff)>(f ->aδ) 4 2 細胞膜モデルによる n の計算 2
 (f->ff)>(f ->aδ) b ->b b ->b(c, in ) (f->ff)>(f ->aδ) n n+1. b. a. 4. b. f. n. n+1. n (n+1) c. c. a. 2. b ->b b ->b(c, in ) (f->ff)>(f ->aδ) 細胞膜モデルによる n の計算. 2.")
121
アモルファス計算 自己組織化のための新しい計算パラダイム Computational particle
微細加工技術と細胞工学 低コストで様々なプロセッサ Computational particle 小さい計算力と少量メモリー 不規則配置、可動性 非同期、局地的相互作用 誤った挙動、環境の影響 同一プログラム 自分たちの位置や方向に 関する情報をもたない 近接のparticleと短距離 (半径r)の通信をする。 全体としては超並列計算システムになっている。 回路の自己組織化のシミュレーション
の通信をする。 全体としては超並列計算システムになっている。 回路の自己組織化のシミュレーション.")
122
Amorphous Computingとは
背景 微細加工技術と細胞工学 低コストで様々なプロセッサを作る (厳密に正確な動作は不要) 新しい計算パラダイムとしての研究 不規則に配置されて、 非同期に局地的に相互作用するような, 計算機能の要素“computational particle”の 集合としてモデル化。 効果的にプログラムするにはどうすればよいか。 生物学的な組織の形成に関連? 生物学は単なるメタファーでなく,実装に使えないか?
 新しい計算パラダイムとしての研究. 不規則に配置されて、 非同期に局地的に相互作用するような, 計算機能の要素 computational particle の. 集合としてモデル化。 効果的にプログラムするにはどうすればよいか。 生物学的な組織の形成に関連? 生物学は単なるメタファーでなく,実装に使えないか?")
123
Computational particleの性質
誤った挙動を示す可能性もある。 環境に影響される。 何らかの動作をするかもしれない。 動き回るかもしれない。 小さい計算能力と少量のメモリーを持つ。 全particleは同様にプログラムされている。 (局所状態の保持や乱数発生は可能) 自分たちの位置や方向に関する情報をもたない。 近接のparticleと短距離(半径r)の通信をする。 全体としては超並列計算システムになっている。 Cellular automata, 自己組織化システム
 自分たちの位置や方向に関する情報をもたない。 近接のparticleと短距離(半径r)の通信をする。 全体としては超並列計算システムになっている。 Cellular automata, 自己組織化システム.")
124
Wave propagationによる パターン形成
最初の“anchor” particleから始めてメッセージ(ホップの情報を持つ)を伝達していく。 生物学的なパターン形成と関連。 2つのanchor particleにより「成長の阻害」や「屈動性(tropism)」などもプログラムできる。 Cooreによるgrowing-point language(GPL)で プログラミングし、コンパイルしてparticleに セット。 Packet-radio network
を伝達していく。 生物学的なパターン形成と関連。 2つのanchor particleにより「成長の阻害」や「屈動性(tropism)」などもプログラムできる。 Cooreによるgrowing-point language(GPL)で プログラミングし、コンパイルしてparticleに セット。 Packet-radio network.")
125
Growing-point languageによる プログラムの例

126
パターン形成の例

128
量子ドット・コンピュータ QCAによるインバータ キワモノか? 量子コンピュータとは違う。 量子ドット・セル・オートマトン(QCA)
ドミノのように四個の 量子ドットを並べる。 ドミノ内ではトンネル効果に よって電子が移動。 ドミノの相互作用により 状態が伝搬する。 配線が必要無い? しかし、量子ドットを正確に 配置しなければならない。 QCAによるインバータ ドミノはセルという。 セルには四個の量子ドットと二個の電子。 隣り合うセル内の電子はクーロン力によって相互作用する。

129
BASICS

130
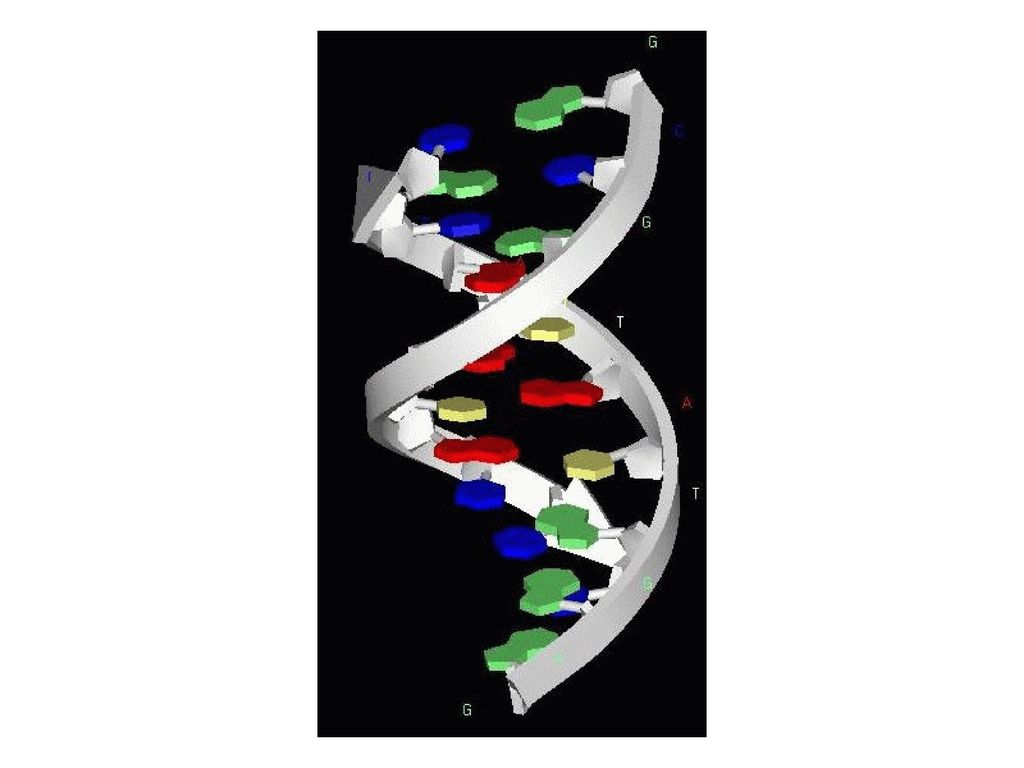
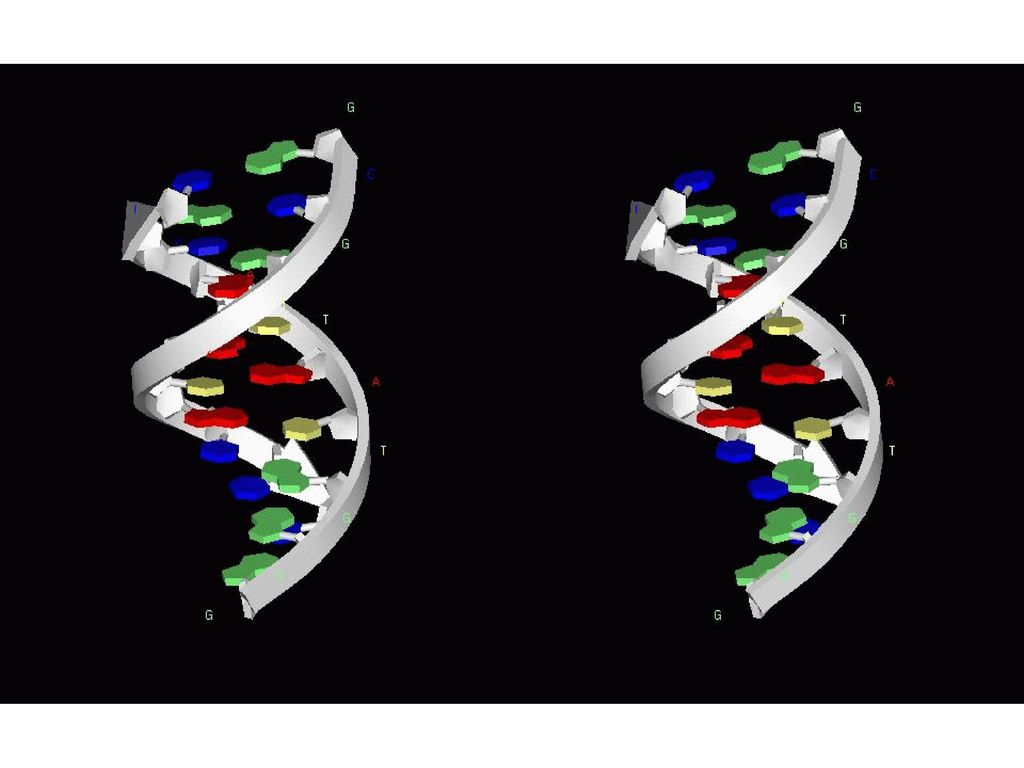
DNA 糖 リン酸 塩基 デオキシリボース プリン塩基 --- 6角形と5角形の二つのリング ピリミジン塩基 --- 6角形一つ
アデニン(A:Adenine) グアニン(G:Guanine) ピリミジン塩基 --- 6角形一つ チミン(T:Thymine) シトシン(C:Cytosine)
 グアニン(G:Guanine) ピリミジン塩基 --- 6角形一つ. チミン(T:Thymine) シトシン(C:Cytosine)")
131
正確にはnucleoside リン酸基が付くとnucleotide

133
リン酸基 5’ 3’

136
二本鎖の直径は2nm。 一回転が10~10.5ベースペア。 スタックの幅が0.34nm、従って、一回転が3.5nmくらい。

137
A-DNA B-DNA Z-DNA

138
RNAとDNA

139
実験操作 PCR(ポリメラーゼ連鎖反応) ゲル電気泳動 アフィニティ・セパレーション 制限酵素による切断 ライゲースによる連結
クローニングとシーケンシング

140
PCR(ポリメラーゼ連鎖反応) プライマー 変性 プライマー プライミング 伸張 3’ 3’
 プライマー 変性 プライマー プライミング 伸張 3’ 3’")
141
ゲル電気泳動 長い分子 短い分子 下 上 ポリアクリルアミドゲル電気泳動 マイナス極 プラス極

142
DNA一本鎖の分離 標 的 分 子 プローブ 相補的 アニ―リング アビジン ビーズ ビオチン 抽出 磁石

143
DNA(RNA)の二次構造 ベースペア i.j の集合 k-ループ --- k 個のベースペアで囲まれたループ
1-ループ ヘアピン(hairpin) 2-ループ スタック(stack) バルジ(bulge) 内部(interior) マルチ・ループ(multi-loop) ループに対してエネルギーが割り当てられる。
 2-ループ. スタック(stack) バルジ(bulge) 内部(interior) マルチ・ループ(multi-loop) ループに対してエネルギーが割り当てられる。")
144
ヘアピン スタック バルジ 内部 3-ループ これらの構造にエネルギーを割り当てる。 (nearest neighborモデル)
")
145
a. ヘアピン b. 内部 c. バルジ d. マルチ e. スタック f. シュードノット

146
動的プログラミング W(i, j) : i 番目のベースと j 番目の間の最小エネルギー
V(i, j) : i と j がペアである場合の最小エネルギー W(i, j) = min(W(i+1, j), W(i, j-1), V(i, j), min(W(i, k)+W(k+1, j)) i£k<j V(i, j) = min(eh(i, j), es(i, j)+V(i+1, j-1), VBI(i, j), VM(i, j)) eh(i, j) : ヘアピンのエネルギー es(i, j) : スタックのエネルギー
 : i と j がペアである場合の最小エネルギー. W(i, j) = min(W(i+1, j), W(i, j-1), V(i, j), min(W(i, k)+W(k+1, j)) i£k<j. V(i, j) = min(eh(i, j), es(i, j)+V(i+1, j-1), VBI(i, j), VM(i, j)) eh(i, j) : ヘアピンのエネルギー. es(i, j) : スタックのエネルギー.")
147
動的プログラミング VBI(i, j) = min(ebi(i, j, i¢, j¢)+V(i¢, j¢))
i<i¢<j¢<j i¢-i+j-j¢>2 ebi(i, j, i¢, j¢) : 内部ループのエネルギー O(n4) になってしまう。 VM(i, j) = min(W(i+1, k)+W(k+1, j-1)) i<k<j-1 マルチ・ループのエネルギーが 0 の場合。
 : 内部ループのエネルギー. O(n4) になってしまう。 VM(i, j) = min(W(i+1, k)+W(k+1, j-1)) i<k<j-1. マルチ・ループのエネルギーが 0 の場合。")
148
内部ループ 内部ループのエネルギー ebi(i, j, i¢, j¢) が、 ループの長さ (i¢-i+j-j¢)×c ならば、
VBI(i, j) = min(VBI(i, j, l)) l VBI(i, j, l) = min(VBI(i+1, j, l-1) + c, VBI(i, j-1, l-1) + c, c×l + V(i+1, j-l+1), c×l + V(i+l-1, j-1)) O(n3) になる。
 = min(VBI(i, j, l)) l. VBI(i, j, l) = min(VBI(i+1, j, l-1) + c, VBI(i, j-1, l-1) + c, c×l + V(i+1, j-l+1), c×l + V(i+l-1, j-1)) O(n3) になる。")
149
マルチ・ループ マルチ・ループのエネルギーの近似: a + b×k´ + c×k k´ = 5 k = 3 k´: ペアを組まない塩基の数
O(n3) になる。 k´ = 5 k = 3
 になる。 k´ = 5. k = 3.")
150
McCaskillのアルゴリズム 個々の構造のエネルギーを求めるのではなく、 可能なすべての構造のエネルギーの分布を 求める。
分配関数(partition function) 特定のベースペアが形成される確率 どちらも、動的プログラミングによる。
 特定のベースペアが形成される確率. どちらも、動的プログラミングによる。")
151
演習III課題(分子計算) (3)生命情報(分子計算)
生物の持つ計算能力の解析,および,生物を用いた新しい計算機(計算する人工生物)の可能性について探求します.cf.生命情報論 分子計算(DNA計算)に関する論文購読,シミュレーション,実験?
の可能性について探求します.cf.生命情報論. 分子計算(DNA計算)に関する論文購読,シミュレーション,実験")
152
演習III課題(分子計算) 最近のNatureやScienceなどの論文を読む。 実験技術に関して調べる。 実験? 配列の設計
CRESTのプロジェクトに関連した実験 実験? 希望があれば。見学は毎年やっている。 配列の設計 符号理論に基づく配列セットの設計 与えられた構造をとるような配列の設計 (inverse folding) CRESTのプロジェクトに関連 分子計算のシミュレーション
 CRESTのプロジェクトに関連. 分子計算のシミュレーション.")
153
生命情報論課題(萩谷分) 分子コンピューティングの計算モデルを 一つあげて、その計算可能性や計算量について議論せよ。
分子コンピューティングの将来性について 以下のいずれかの観点から述べよ。 バイオテクノロジーへの応用の可能性 ナノテクノロジーへの応用の可能性 新しい計算パラダイムを生み出す可能性

154
情報科学特別講義I(萩谷分) 分子コンピューティングの計算モデルを一つあげて解説せよ。(文献を調べるとよい。)
DNA/RNAの二次構造を予測する方法と、逆に二次構造から配列を設計する方法について説明せよ。(文献を調べるとよい。) 分子コンピューティング(および分子エレクトロニクス)の将来への期待なども含めて、講義の感想を述べよ。
 分子コンピューティング(および分子エレクトロニクス)の将来への期待なども含めて、講義の感想を述べよ。")






 情報工学科 木村昌臣 篠埜 功.>")




>")





>")







