TF-IDF法とLSHアルゴリズムを用いた 関数単位のコードクローン検出法 井上研究室 山中裕樹
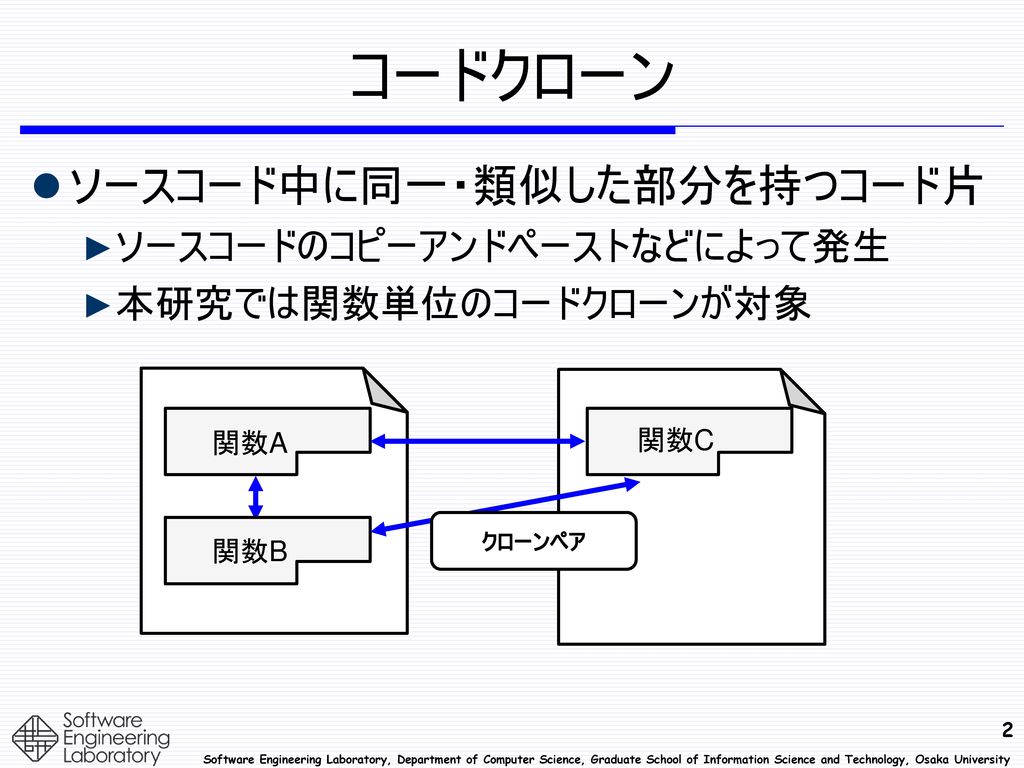
コードクローン ソースコード中に同一・類似した部分を持つコード片 ソースコードのコピーアンドペーストなどによって発生 本研究では関数単位のコードクローンが対象 関数A 関数C クローンペア 関数B
コードクローンの定義 [1] 種類 意味 タイプ1 レイアウト・空白・コメントの違いを除き完全に一致している タイプ2 タイプ1に加え変数名・型の違いを除き構文的に一致している タイプ3 タイプ2に加え文が挿入・削除・変更されている タイプ4 構文上異なる実装だが,類似処理を実行している [1]C. K. Roy, J. R. Cordy, R. Koschke. Comparison and evaluation of code clone detection techniques and tools: a qualitative approach. Science of Computer Programming, Vol. 74, No. 7, pp. 470–495, 2009.
コードクローン:タイプ1 関数A 関数B 種類 意味 タイプ1 レイアウト・空白・コメントの違いを除き完全に一致している タイプ2 タイプ1に加え変数名・型の違いを除き構文的に一致している タイプ3 タイプ2に加え文が挿入・削除・変更されている タイプ4 構文上異なる実装だが,類似処理を実行している int sum(int[] data){ int sum = 0; for(int i=0; i<data.length; i++){ sum = sum + data[i] ; } return sum; int sum(int[] data){ int sum = 0; for(int i=0; i<data.length; i++){ sum = sum + data[i] ; } return sum; 関数A 関数B
コードクローン:タイプ2 関数A 関数B 種類 意味 タイプ1 レイアウト・空白・コメントの違いを除き完全に一致している タイプ2 タイプ1に加え変数名・型の違いを除き構文的に一致している タイプ3 タイプ2に加え文の挿入・削除・変更されている タイプ4 構文上異なる実装だが,類似処理を実行している int sum(int[] data){ int sum = 0; for(int i=0; i<data.length; i++){ sum = sum + data[i] ; } return sum; double sum(double[] data){ double sum = 0; for(int j=0; j<data.length; j++){ sum = sum + data[j] ; } return sum; 関数A 関数B
コードクローン:タイプ3 関数A 関数B 種類 意味 タイプ1 レイアウト・空白・コメントの違いを除き完全に一致している タイプ2 タイプ1に加え変数名・型の違いを除き構文的に一致している タイプ3 タイプ2に加え文が挿入・削除・変更されている タイプ4 構文上異なる実装だが,類似処理を実行している int sum(int[] data){ int sum = 0; for(int i=0; i<data.length; i++){ sum = sum + data[i]; } return sum; int sum(int[] data){ int sum = 0; for(int i=0; i<data.length; i++){ sum += data[i]; } return sum; 関数A 関数B
コードクローン:タイプ4 関数A 関数B 種類 意味 タイプ1 レイアウト・空白・コメントの違いを除き完全に一致している タイプ2 タイプ1に加え変数名・型の違いを除き構文的に一致している タイプ3 タイプ2に加え文が挿入・削除・変更されている タイプ4 構文上異なる実装だが,類似処理を実行している int sum(int[] data){ int sum = 0; for(int i=0; i<data.length; i++){ sum = sum + data[i]; } return sum; int sum(int[] data){ int sum = 0, i=0; while(i<data.length){ sum += data[i]; i++; } return sum; 関数A 関数B
コードクローン検出の目的 リファクタリング支援 一貫した修正漏れによるバグの検出(タイプ3,4) メソッド の引上げ クローンペア Class S メソッド の引上げ Class A Class B hoge() hoge() hoge() Class A Class B クローンペア int sum(int[] data){ if ( data == null) return null; ・・・ } 例外処理の 追加漏れ int sum(int[] data){ //例外処理漏れ ・・・ }
既存のコードクローン検出手法 構文的な類似性に着目した手法 処理の意味的な類似性に着目した手法 CCFinder[2] など メリット:タイプ1,2のコードクローンを高速に検出可能 デメリット:タイプ3,タイプ4のコードクローンの検出が困難 処理の意味的な類似性に着目した手法 MeCC[3] など メリット:タイプ1- タイプ4のコードクローンを検出可能 デメリット:検出時間に膨大な時間がかかる [2] T. Kamiya, S. Kusumoto, K. Inoue. CCFinder: a multilinguistic token-based code clone detection system for large scale source code. IEEE Trans. Softw. Eng., Vol. 28, No. 7, pp. 654–670, 2002. [3] H. Kim, Y. Jung, S. Kim, K. Yi. MeCC: memory comparison-based clone detector. In Proc. of ICSE ’11, pp. 301–310, 2011.
全タイプの関数単位のコードクローンを高速に検出 提案手法の概要 関数中のワードに重み付けを行い特徴ベクトルを計算 識別子名を構成する単語 ( 関数名,変数名 ) 予約語に含まれる単語 ( if, while ) 近似アルゴリズムを用いて特徴ベクトルをクラスタリング 全タイプの関数単位のコードクローンを高速に検出
検出アルゴリズム STEP1:各関数からワードの抽出 STEP2: TF-IDF法を用いて関数を特徴ベクトルに変換 STEP3: LSHアルゴリズムを用いて特徴ベクトルをクラスタリング STEP4: クラスタ中の特徴ベクトル間の類似度を計算 STEP1 STEP2 STEP3 STEP4 類似度 関数対 クローン 0.95 Function A ✓ Function B 0.70 Function C Function D Function E 0.90 ・・・ Function A Function A ワード 回数 xxx 3 yyy 2 ・・・ Function A Function B Function B Function B Function C Function D Function E ワード 回数 xxx 2 yyy 4 ・・・ ソースコード クローンペアリスト ワードリスト 特徴ベクトル クラスタ
STEP1:ワードの抽出 各関数から識別子名・予約語を抽出 2文字以下の識別子は全て同一のワード(メタワード)として扱う 複数の単語の場合,区切り文字や大文字で分割 例:dataSize ⇒ data + size 関数 Aのワードリスト 関数 Aのソースコード ワード 出現回数 予約語 int 4 for 1 return 分割した 識別子名 data sum size 2 メタワード int sum(int[] data, int dataSize){ int sum = 0; for(int i=0; i<dataSize; i++) sum += data[i]; return sum; }
STEP2:特徴ベクトルの計算 × TF-IDF法を利用 各ワードの重みを特徴量として 各関数を特徴ベクトルに変換 文書中の単語に関する重み付けの手法 TF値とIDF値の積で表される TF値 IDF値 関数中の ワードの出現頻度 ソースコード全体の ワードの希少さ × 各ワードの重みを特徴量として 各関数を特徴ベクトルに変換
STEP3:特徴ベクトルのクラスタリング LSH(Locality-Sensitive Hashing)[4]を利用 近似最近傍探索アルゴリズムの一つ ハッシュ関数を用いて高速にクラスタリング可能 クローンペアと成りうる候補を絞ることが目的 関数名 特徴ベクトル Function A (5,4,2,1,・・・ ) Function B (0,0,2,2,・・・ ) Function C Function D (3,4,2,1,・・・ ) Function E (5,4,2,3,・・・ ) Function F (0,1,2,2,・・・ ) ・・・ Function A Function D Function F Function B Function C Function E クラスタリング 関数のクラスタ 各関数の特徴ベクトル [4] P. Indyk, R. Motwani. Approximate nearest neighbors: towards removing the curse of dimensionality. In Proc. of STOC ’98, pp. 604-613, 1998.
閾値(0.9)以上であればクローンペアとして検出 STEP4: ベクトル間の類似度計算 各クラスタ内で特徴ベクトル間の類似度を計算 コサイン類似度を利用 特徴ベクトル 間の類似度の計算方法 閾値(0.9)以上であればクローンペアとして検出
評価実験 実験1:ベンチマークを用いた検出性の評価 実験2:既存手法との比較実験 実験3:検出したコードクローンの調査 本手法でコードクローンを検出することができるか 実験2:既存手法との比較実験 検出時間と検出精度の比較 実験3:検出したコードクローンの調査 本手法でどのようなタイプ4のコードクローンを検出できたか
全タイプのコードクローンを検出することを確認 実験1:検出性の評価 Royらのベンチマーク[5]を利用 タイプ1-タイプ4の16個のクローンペアが用意 タイプ1 タイプ2 タイプ3 タイプ4 ベンチマーク 3 4 5 検出結果 2 全タイプのコードクローンを検出することを確認 [5] C. K. Roy, J. R. Cordy, R. Koschke. Comparison and evaluation of code clone detection techniques and tools: a qualitative approach. Science of Computer Programming, Vol. 74, No. 7, pp.470-495, 2009.
実験2:既存手法との比較 メモリベースの検出ツールMeCCと比較 MeCCの評価実験で利用されたOSSに適用 タイプ1-タイプ4の関数単位のコードクローン検出 MeCCの評価実験で利用されたOSSに適用 検出精度・検出時間を比較 プロジェクト名 言語 サイズ バージョン ApacheHTTPD C 343KLOC 2.2.14 Python 435KLOC 2.5.1 PostgreSQL 937KLOC 8.5.1
検出精度の比較結果 適合率と各タイプの正解検出数を比較 MeCCよりも高い適合率で検出可能である 各タイプの検出数もMeCCを上回っている プロジェクト名 適合率 検出クローン タイプ1 タイプ2 タイプ3 タイプ4 本手法 ApacheHTTPD 95.4% 71 100 190 11 Python 94.5% 19 103 159 21 PostgreSQL 94.7% 57 230 341 17 合計 94.6% 147 433 690 49 MeCC 87.5% 2 84 10 85.3% 3 127 82 13 83.1% 9 120 88 14 85.0% 331 241 37 MeCCよりも高い適合率で検出可能である 各タイプの検出数もMeCCを上回っている
MeCCよりも高速な検出を行うことが可能 検出時間の比較結果 MeCCの実行環境と同一のものを利用 Ubuntu 64-bit ( RAM: 8.0GB, CPU: Intel Xeon 2.4GHz) ApacheHTTPD Python PostgreSQL 本手法 1m43s 2m13s 4m39s MeCC 310m34s 65m26s 428m32s MeCCよりも高速な検出を行うことが可能
実験3:コードクローンの実例(1/2) 繰り返し処理の置き換え for文を用いた繰り返し do-while文を用いた繰り返し static const XML_Char * poolCopyStringN(STRING_POOL *pool, const XML_Char *s, int n) { if (!pool->ptr && !poolGrow(pool)) return NULL; for (; n > 0; --n, s++) { if (!poolAppendChar(pool, *s)) } s = pool->start; poolFinish(pool); return s; static const XML_Char * FASTCALL poolCopyString(STRING_POOL *pool, const XML_Char *s) { // 例外処理漏れの可能性がある! do { if (!poolAppendChar(pool, *s)) return NULL; }while (*s++); s = pool->start; poolFinish(pool); return s; } for文を用いた繰り返し do-while文を用いた繰り返し
実験3:コードクローンの実例(2/2) 文の並び替え 例外処理の 位置が異なる static PyObject * dequeiter_next(dequeiterobject *it) { PyObject *item; if (it->deque->state != it->state) { it->counter = 0; PyErr_SetString(PyExc_RuntimeError, "deque mutated during iteration"); return NULL; } if (it->counter == 0) assert (!(it->b == it->deque->rightblock && it->index > it->deque->rightindex)); ・ static PyObject * dequereviter_next(dequeiterobject *it) { PyObject *item; if (it->counter == 0) return NULL; if (it->deque->state != it->state) { it->counter = 0; PyErr_SetString(PyExc_RuntimeError, "deque mutated during iteration"); } assert (!(it->b == it->deque->leftblock && it->index < it->deque->leftindex)); ・ 例外処理の 位置が異なる
まとめと今後の課題 まとめ 今後の課題 全タイプの関数単位のコードクローン検出法を提案 既存手法と比較して高精度・高速な検出を実現 TF-IDF法を利用して関数を特徴ベクトルに変換 LSHアルゴリズムを用いて特徴ベクトルをクラスタリング 既存手法と比較して高精度・高速な検出を実現 今後の課題 LSI(Latent Semantic Indexing)などの手法との比較 様々なプログラミング言語に対応 他のコードクローン検出ツールとの比較
ご清聴ありがとうございました