仮想マシンの並列処理性能に対するCPU割り当ての影響の評価 九州工業大学情報工学部機械情報工学科 光来研究室B4 11237054 中田 理公
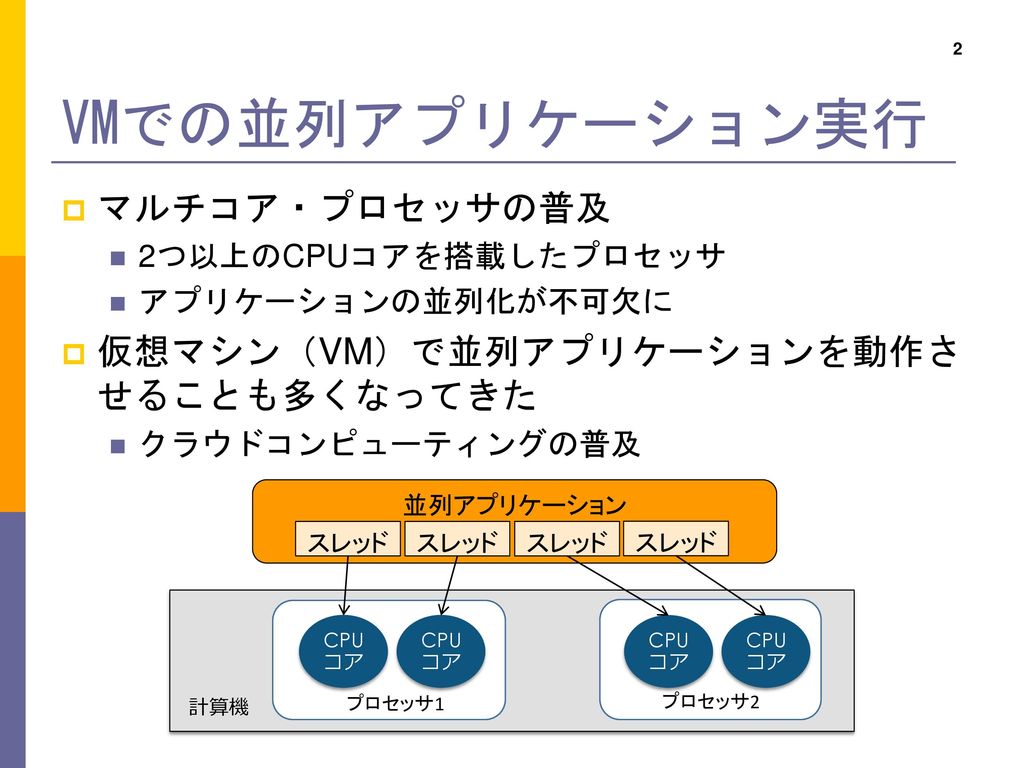
VMでの並列アプリケーション実行 マルチコア・プロセッサの普及 仮想マシン(VM)で並列アプリケーションを動作させることも多くなってきた 2つ以上のCPUコアを搭載したプロセッサ アプリケーションの並列化が不可欠に 仮想マシン(VM)で並列アプリケーションを動作させることも多くなってきた クラウドコンピューティングの普及 並列アプリケーション 現在→ マルチコアプロセッサとは→ 複数のCPUコアに1つのアプリケーションを同時に割り当てることができるようにするため、下の図のように、→ また、→ スレッド CPU コア CPU コア CPU コア CPU コア 計算機 プロセッサ1 プロセッサ2
VMへのCPU割り当て VMの仮想CPUにプロセッサ内のCPUコアを割り当てて実行 割り当て方法 スケジューリングによる動的な割り当て CPUアフィニティによる固定的な割り当て VM 1 VM 2 VMへのCPU割り当ては、計算機上で複数のVMを動かせるようにするため、プロセッサ内のCPUコアを割り当てて実行しています。 →図のVM1のようにVMが使用するCPUコアを状況に応じてスケジューリングにより動的に割り当てる場合があります。 また、図のVM2のようにVMが使用するCPUコアを固定して割り当てることもできます。 しかし、⇒ 仮想 CPU 仮想 CPU 仮想 CPU 仮想 CPU CPU コア CPU コア CPU コア CPU コア プロセッサ1 プロセッサ2 計算機
? CPU仮想化の影響 VMへのCPU割り当てによっては並列アプリケーションの処理性能に大きな影響を及ぼす可能性 VM内のアプリケーションやOSにCPU割り当ての詳細は分からない OSはプロセッサを意識してスケジューリングを行うことが多い 例:1つのアプリケーションにはできるだけ同一プロセッサ内のCPUコアを使わせる ? しかし、VMにおいてはCPU割り当ての詳細が分からないためOSがプロセッサを意識してスケジューリングしても、物理的には同一プロセッサではないかもしれないため、そのスケジューリングが逆効果になったりする場合があります。 CPU コア0 CPU コア? CPU コア ... ... ... プロセッサ? プロセッサ1 プロセッサ2 計算機 VM 仮想 CPU 仮想 CPU
研究の目的 VMへのCPU割り当てがアプリケーションの並列処理性能にどのような影響を与えるかを調査 対象とする並列アプリケーション Tascell [1] により並列化されたフィボナッチ数の計算 fib(n) = fib(n-1) + fib(n-2) 5 下の図は、例えばfib(5)を得るためには、fib(4)とfib(3)が必要であり、fib(4)はfib(3)とfib(2)が必要となるということを表しています。フィボナッチ数の計算の並列化は、この右側の3以下の部分は別々に計算できるためスレッドに分けることができます。 4 3 3 2 2 1 スレッド2 スレッド1 2 1 [1] T. Hiraishi, et al., Backtracking-based Load Balancing, In Proc. Symp. PPoPP 2009.
実験環境 計算機 仮想マシン プロセッサ : Opteron 6376 2.3GHz (16コア) 2基 メモリ : 320GB 仮想化ソフトウェア : Xen 4.4.0 仮想マシン 仮想CPU : 16個 メモリ : 4GB OS : Linux 3.13.0 VM 仮想 CPU0 ... 仮想 CPU15 まず、VMにオーバヘッドがあるか調べるため⇒ CPU コア0 CPU コア15 CPU コア16 CPU コア31 ... ... プロセッサ1 プロセッサ2 計算機
実環境との性能比較 VMに同一プロセッサ内のCPUコア16個を割り当てた 24%程度の仮想化オーバヘッドがある 4スレッド以上で性能向上が鈍化 8スレッドを超えると再び性能が大きく向上 VMと、VMを用いない実環境で性能比較を行いました。 VMには、同一プロセッサ内のCPUコア16個を割り当てた その結果が、下のグラフです。 縦軸、横軸、対数グラフ、線種の説明をする →このような挙動を示すのは、1基のプロセッサのみを割り当てたのが原因ではないかと考え⇒
CPU割り当ての影響 VMに2基のプロセッサからCPUコア16個を割り当てた 2基に分散させる比率により性能が異なる 均等に分散させた場合(8-8)が最も性能がよい 1基だけの場合と比べて最大38%の性能向上 CPU割り当ての影響を調査 凡例は、2基のプロセッサに分散させたCPUコアの数を示しています。 0-16は1つのプロセッサのみを割り当てた場合であり、8-8は2基のプロセッサに均等に割り当てたということです。 このように性能の違いが出るのは、CPUコアの競合が原因ではないかと考え⇒
CPUコアの競合の調査 Opteron 6376はCMT (Clustered Multi-Thread) を採用 モジュール 0 モジュール 1 CPUコアの競合について調査しました。まず、今回使ったマシンのCPUについて説明します。→ そこで、競合しているモジュールの数を測定しました。⇒ 命令デコーダ 命令デコーダ CPU コア0 CPU コア1 CPU コア2 CPU コア3 L2キャッシュ L2キャッシュ プロセッサ
競合モジュール数の測定 各CPUコアの使用率を測定し、CPUコアが2つとも使われているモジュールを競合と判断 競合モジュール数と性能は強く相関 競合モジュール数が大きいほど性能が低下 では、実際にはどのようにCPUを使用しているのか、8-8と0-16のそれぞれの場合において説明します⇒
8-8の場合のCPU使用状況 モジュールが正しく考慮されている 8スレッドまで競合しないようにCPUコアを使用 性能が向上 8スレッド以上では使用するCPUコアが競合を起こす 性能が向上しにくくなる モジュール0 モジュール1 CPU コア0 CPU コア1 CPU コア2 CPU コア3 CPU コア4 CPU コア5 CPU コア6 CPU コア7 CPU コア8 CPU コア9 CPU コア10 CPU コア11 CPU コア12 CPU コア13 CPU コア14 CPU コア15 8-8では各プロセッサの前半の8コアを割り当てています。CPU使用状況は * このように→ プロセッサ1 CPU コア16 CPU コア17 CPU コア18 CPU コア19 CPU コア20 CPU コア21 CPU コア22 CPU コア23 CPU コア24 CPU コア25 CPU コア26 CPU コア27 CPU コア28 CPU コア29 CPU コア30 CPU コア31 プロセッサ2
0-16の場合のCPU使用状況 8-8の場合とCPUコアの使われ方が異なる 4スレッドを超えるとCPUコアの競合が発生 12スレッドを超えると再び競合 モジュール0 モジュール1 CPU コア0 CPU コア1 CPU コア2 CPU コア3 CPU コア4 CPU コア5 CPU コア6 CPU コア7 CPU コア8 CPU コア9 CPU コア10 CPU コア11 CPU コア12 CPU コア13 CPU コア14 CPU コア15 また、0-16では * プロセッサ2のみを割り当てています。CPUの使用状況は * このように4スレッドまでは競合していませんが→ * 性能が向上しにくくなり→ このようにCPUコアの使い方になっているのは⇒ プロセッサ1 CPU コア16 CPU コア17 CPU コア18 CPU コア19 CPU コア20 CPU コア21 CPU コア22 CPU コア23 CPU コア24 CPU コア25 CPU コア26 CPU コア27 CPU コア28 CPU コア29 CPU コア30 CPU コア31 プロセッサ2
原因となるスケジューラの特定 どちらのスケジューラに原因があるか調べた OSのスレッドスケジューラを無効化 影響なし Xenの仮想CPUスケジューラを無効化 挙動が大きく変化した Xenのスケジューラの問題であることがわかった OS無効化 Xen無効化 OSとXenのどちら→ スレッドと仮想CPUを固定することにより→ 仮想CPUと物理CPUを1対1で割り当てることにより→ そこで、Xenのスケジューラの問題を分析しました。
Xenのスケジューラの問題の分析 ユーザによるCPU割り当てとXenによるCPUコアのグループ化の競合が原因 今回の実験では、2基のプロセッサの前半8コアを優先的に使用 8-8の場合、各プロセッサの前半8コアを均等に使用 0-16の場合、プロセッサ2の前半8コアを先にすべて使用 モジュール内で競合すると性能が落ちるため⇒ モジュール0 モジュール1 CPU コア0 CPU コア1 CPU コア2 CPU コア3 CPU コア4 CPU コア5 CPU コア6 CPU コア7 CPU コア8 CPU コア9 CPU コア10 CPU コア11 CPU コア12 CPU コア13 CPU コア14 CPU コア15 プロセッサ1 CPU コア16 CPU コア17 CPU コア18 CPU コア19 CPU コア20 CPU コア21 CPU コア22 CPU コア23 CPU コア24 CPU コア25 CPU コア26 CPU コア27 CPU コア28 CPU コア29 CPU コア30 CPU コア31 プロセッサ2
モジュールを考慮したCPU割り当て 常に競合が起きないようにモジュール内の1つのCPUコアのみを16個割り当てた 16スレッドまでほぼ理想的に性能が向上 8スレッド以上では実環境とほぼ同等 →た場合の性能を調べました。
関連研究 VM上で並列アプリケーションを動かす際の性能低下の原因がいくつか報告されている ロックホルダ・プリエンプション [Uhlig et al. '04] ロックを保持しているスレッドに割り当てられたCPUが他のスレッドに奪われることで処理が進まなくなる現象 vCPUスタッキング [Sukwong et al. '11] ロックを待っているスレッドがロックを保持しているスレッドより先にCPUを得たため処理が進められない現象
まとめ CPUの割り当てがアプリケーションの並列処理性能に大きな影響を与えることが分かった 今後の課題 Xenのスケジューラの問題であることが分かった モジュールを考慮したCPU割り当てにより、性能を大幅に改善することができた 今後の課題 モジュールをよりよく考慮したスケジューラの開発 今回用いたアプリケーション以外についても、CPU割り当ての影響を調査