Download presentation
Presentation is loading. Please wait.

1
2分探索と2分木 ・ 2分探索 ・ ヒープ ・ 2分木

2
データを検索 ・ データの利用において、検索は基本のひとつ
・ 「データの中にこれはありますか?」という質問(こういう質問をクエリーという)にすばやく答える方法を考えよう -1つの方法は、バケツやハッシュを使うもの ・ データのため方ではなく、検索方法のほうからアプローチしてみよう
にすばやく答える方法を考えよう. -1つの方法は、バケツやハッシュを使うもの. ・ データのため方ではなく、検索方法のほうからアプローチしてみよう.")
3
辞書を引く ・ 例えば、辞書をひく、という操作を考えよう ・ 何かひきたい言葉があるときに、それを辞書の中からどうやって見つけ出すか??
適当にひらき、そこのページに言葉があるか調べ、なければそこの前か後ろを調べる 言葉が含まれるページの候補を絞り込んでいる ・ この方法を真似よう

4
2分探索(2分検索) ・ 簡単のため、データは数値の集まりとする
・ まず、データを小さい順にソートして並べておく。 s をデータの先頭の添え字、 t をデータの最後の添え字とする ・ q はありますか、と質問が来たら、まず、真ん中を見る q と一致するなら、ありましたよ、と場所を返す 一致しなければ、q と真ん中を比べて、探索範囲を絞る s t 1 3 7 8 9 11 13 17 18 19

5
探索範囲の絞込み ・ q より真ん中が大きい q があるとすれば、真ん中より前 t を、真ん中より1つ前に設定、再帰的に検索
s を、真ん中より1つ後ろに設定、再帰的に検索 ・ s より t のほうが小さくなったら終了 ・ 探索範囲は、(およそ)半分半分と減っていく s t s t 1 3 7 8 9 11 13 17 18 19
半分半分と減っていく. s. t. s. t. 1. 3. 7. 8. 9. 11. 13. 17. 18. 19.")
6
2分探索の計算時間 ・ 問題毎回、探索範囲が半分以下になる log2 n 回後には、探索範囲の大きさが1になり、終了する
計算時間は O(log2 n) 、情報理論的に最適 ・ メモリは O(n)。しかも、in place。最適 ・ つまりは、非常にすばらしい
 、情報理論的に最適. ・ メモリは O(n)。しかも、in place。最適. ・ つまりは、非常にすばらしい.")
7
練習問題 ・ 以下の数列で、8,17,19 を2分探索で検索せよ (s,t がどのように変化するか、記録すること) 1 3 7 8 9 11
13 17 18 19

8
配列データの弱み ・ 配列データを保持する場合、挿入や削除をするのは大変 O(n) 時間かかる
・ リストを使うと挿入削除は速いが、「真ん中を見つける」のに時間がかかる (先の例題のように、いくつか真ん中を保持する手もあるが、そうすると真ん中を保持する時間がかかる) ・ 一般に、挿入も削除も検索も更新も速い、というのは、それほど自明なことではない ・ しかし、手はある
 ・ 一般に、挿入も削除も検索も更新も速い、というのは、それほど自明なことではない. ・ しかし、手はある.")
9
まずは最小値から ・ 挿入削除が速くて、かつどのセルを見つけるのも速い、は欲張りなので、まずは、「最小値を見つけるのが速い」としよう
問題設定: ・ データ(数値)を保持すること ・ データの挿入&削除(あるいは単に最小値の削除)は短時間でできること ・ データの中の最小値が(いつでも)短時間で取り出せること ・ 一般に、このような機能を持つデータ構造を ヒープ という
を保持すること. ・ データの挿入&削除(あるいは単に最小値の削除)は短時間でできること. ・ データの中の最小値が(いつでも)短時間で取り出せること. ・ 一般に、このような機能を持つデータ構造を ヒープ という.")
10
最強を決める ・ 学校で一番足の速い人を決めよう
・ こういう場合、全員一度にレースをすることはできないので、まず、各クラスで一番を決め、各クラス1番の中でさらに一番を決める ・ クラスの中も、さらに小さいグループに分けて決める ・ 高校野球は、最強を決めるのに、一回 2チームしか評価できないので、トーナメントをする

11
最小を決める ・ 数値データでも同じようにトーナメントをしたとしよう (最小を決めるトーナメント)
(最小を決めるトーナメント) ・ さて、数値が1つ、値が変わった場合、最小が変わるかもしれないが、どうチェックしたらいいだろう ・ 数値が小さくなった場合は簡単。最小と、変わった数値を比べればいい。つまり、数値の挿入&数値の変化は小さくしかならない、ならば最小値だけ覚えておけば十分 ・ 最小値が大きくなった場合 (あるいは削除した場合)、最小値を 計算しなおさなければならない???
 ・ さて、数値が1つ、値が変わった場合、最小が変わるかもしれないが、どうチェックしたらいいだろう. ・ 数値が小さくなった場合は簡単。最小と、変わった数値を比べればいい。つまり、数値の挿入&数値の変化は小さくしかならない、ならば最小値だけ覚えておけば十分. ・ 最小値が大きくなった場合. (あるいは削除した場合)、最小値を. 計算しなおさなければならない???")
12
再計算は一部でいい ・最小値が大きくなった場合、どこを計算しなおさなければいけないだろうか? 実は、全部ではない
・ 数値が変わったものから上に行くルート上の対戦カードだけ、チェックしなおせばいい ・ 逆に見れば、自分の下に変化した 数値がある対戦カードだけ、 チェックしなおせばいい

13
再計算の計算時間 ・再計算の手間はどれくらい? トーナメント表の高さ (トーナメント表のことを ヒープ木 とよぶこともある)
(トーナメント表のことを ヒープ木 とよぶこともある) ・ 頂上から1つずつレベルを下げていくと、チームの数は倍倍で増えていく ・ 頂つまり、一番下の数値のところにいくまでに log2n +1 回かかる ・ データ更新の計算時間は O(log n )
 ・ 頂上から1つずつレベルを下げていくと、チームの数は倍倍で増えていく. ・ 頂つまり、一番下の数値のところにいくまでに log2n +1 回かかる. ・ データ更新の計算時間は O(log n )")
14
挿入と削除 ・ ヒープに新しく要素を追加するときは、ヒープ木の一番右側に追加する
・ ヒープから要素を削除するときは、削除する要素にヒープ木の一番右側の要素を代入してヒープ木を更新したあと、右端の要素を削除し、ヒープ木の更新をする ・ どちらも計算時間は O(log n )
")
15
ヒープを実現するには ・ さて、ヒープを実際にメモリの中に構築するにはどうすればいいでしょうか?
リストのように、セルとポインタを作ればいいかな? ・ ヒープ木の隣接関係がつかめるよう、上と左右の下のセルにポインタを張る ・ 実は配列で、ポインタなしで作れる

16
配列でヒープ構造を ・ ヒープ木を上から1レベルずつ、各レベルを左から右にたどり、対戦カードに順番に 0 から番号をつける 一番下のレベルが n のとき、最後は 2n-2 になる 配列の大きさは 2n-1 ・ 自分の上・左下・右下が、計算で出せる 1 2 3 4 5 6 7 8 9 10 11 12

17
隣のセルの添え字 1 2 3 4 5 6 7 8 9 10 11 12 ・ ヒープの対戦カード(以後セルといいます)i の
・ i がn-1 より大きいなら、子はいない 1 2 3 4 5 6 7 8 9 10 11 12

18
ヒープの構造体 ・ ヒープの構造体は、配列と、配列の大きさと、ヒープの大きさ ・ i 番目のセルの値を a に変更するルーチン
void AHEAP_chg ( AHEAP *H, int i, int a ){ int j; H->h[i] = a; while ( i>0 ){ j = i (i%2)*2; // j := sibling of i if ( H->h[j] < a ) a = H->h[j]; i = (i-1) / 2; // i := parent of i if ( H->h[i] == a ) break; // no need to update } typedef struct { int *h; // array for values int end; // size of array int num; // current size of heap } AHEAP;
{ int j; H->h[i] = a; while ( i>0 ){ j = i (i%2)*2; // j := sibling of i. if ( H->h[j] < a ) a = H->h[j]; i = (i-1) / 2; // i := parent of i. if ( H->h[i] == a ) break; // no need to update. } typedef struct { int *h; // array for values. int end; // size of array. int num; // current size of heap. } AHEAP;")
19
挿入と削除 ・ 新しいセルを挿入する際には、num を1つ大きくして、最後にセルの a に変更 void AHEAP_ins ( AHEAP *H, int a ){ H->num++; H->h[H->num*2-3] = H->h[(H->num*2-2)/2] AHEAP_chg ( H, H->num*2-2, a); } void AHEAP_del ( AHEAP *H, int i ){ AHEAP_chg ( H, i, H->h[H->num*2-2]); AHEAP_chg ( H, (H->num*2-2)/2, H->h[H->num*2-3]); H->num--; 1 2 3 4 5 6 7 8 9 10 11 12
![挿入と削除 ・ 新しいセルを挿入する際には、num を1つ大きくして、最後にセルの a に変更. void AHEAP_ins ( AHEAP *H, int a ){ H->num++; H->h[H->num*2-3] = H->h[(H->num*2-2)/2]](http://slidesplayer.net/slide/11353092/61/images/19/%E6%8C%BF%E5%85%A5%E3%81%A8%E5%89%8A%E9%99%A4+%E3%83%BB+%E6%96%B0%E3%81%97%E3%81%84%E3%82%BB%E3%83%AB%E3%82%92%E6%8C%BF%E5%85%A5%E3%81%99%E3%82%8B%E9%9A%9B%E3%81%AB%E3%81%AF%E3%80%81num+%E3%82%92%EF%BC%91%E3%81%A4%E5%A4%A7%E3%81%8D%E3%81%8F%E3%81%97%E3%81%A6%E3%80%81%E6%9C%80%E5%BE%8C%E3%81%AB%E3%82%BB%E3%83%AB%E3%81%AE+a+%E3%81%AB%E5%A4%89%E6%9B%B4.+void+AHEAP_ins+%28+AHEAP+%2AH%2C+int+a+%29%7B+H-%3Enum%2B%2B%3B+H-%3Eh%5BH-%3Enum%2A2-3%5D+%3D+H-%3Eh%5B%28H-%3Enum%2A2-2%29%2F2%5D.jpg "AHEAP_chg ( H, H->num*2-2, a); } void AHEAP_del ( AHEAP *H, int i ){ AHEAP_chg ( H, i, H->h[H->num*2-2]); AHEAP_chg ( H, (H->num*2-2)/2, H->h[H->num*2-3]); H->num--;")
20
最小値を持つセルの検索 ・ 一番上(セル i )からスタートして、最小値を持つ子どもの方に降りていく int AHEAP_findmin ( AHEAP *H, int i ){ if ( H->num <= 0 ) return (-1); while ( i < H->num-1 ){ if ( H->h[i*2+1] == H->h[i] ) i = i*2+1; else i = i*2+2; } return ( i ); 1 2 3 4 5 6 7 8 9 10 11 12
{ if ( H->h[i*2+1] == H->h[i] ) i = i*2+1; else i = i*2+2; } return ( i );")
21
閾値以下の値を全て見つける 1 2 3 4 5 6 7 8 9 10 11 12 ・ 一番左にある、閾値以下の値を持つものを見つける
int AHEAP_findlow_leftmost ( AHEAP *H, int a , int i ){ if ( H->num <= 0 ) return (-1); if ( H->h[0] > a ) return (-1); while ( i < H->num-1 ){ if ( H->h[i*2+1] <= a ) i = i*2+1; else i = i*2+2; } return ( i ); ・ (セル i )の直右にある、閾値以下の値を持つものを見つける int AHEAP_findlow_nxt ( AHEAP *H, int i ){ for ( ; i>0 ; i=(i-1)/2 ){ if ( i%2 == 1 && H->h[i+1] <= a ) return ( AHEAP_findlow_leftmost ( H, a, i+1 ); return ( -1 ); 1 2 3 4 5 6 7 8 9 10 11 12
{ if ( H->num <= 0 ) return (-1); if ( H->h[0] > a ) return (-1); while ( i < H->num-1 ){ if ( H->h[i*2+1] <= a ) i = i*2+1; else i = i*2+2; } return ( i ); ・ (セル i )の直右にある、閾値以下の値を持つものを見つける. int AHEAP_findlow_nxt ( AHEAP *H, int i ){ for ( ; i>0 ; i=(i-1)/2 ){ if ( i%2 == 1 && H->h[i+1] <= a ) return ( AHEAP_findlow_leftmost ( H, a, i+1 ); return ( -1 );")
22
ヒープの利用例 1 2 3 4 5 6 7 8 9 10 11 12 ・ 数列をソートする(小さい順に並べ替える)
-数列の数値を全てヒープに挿入する -小さい順に1つずつ取り出す ・ グラフ構造からクラスタリングをする 1 2 3 4 5 6 7 8 9 10 11 12

23
ヒープの利用例:ハフマン木の構築 35 20 15 11 7 A9 B6 C5 D4 E3 F8
・ (単語などが) n 個あり、それぞれ頻度がある ・ 頻度が最小なものと、その次のものを列の数値を全てヒープに挿入する -頻度が小さい順に2つ取り出す -両者を合併し、1つになるまで同様に繰り返す ・ 右の子、左の子に01を割当ててコード化すると、各文字を01のコードに割当てられる。 最適な圧縮形式になっている 35 20 15 11 7 A9 B6 C5 D4 E3 F8
 n 個あり、それぞれ頻度がある. ・ 頻度が最小なものと、その次のものを列の数値を全てヒープに挿入する. -頻度が小さい順に2つ取り出す. -両者を合併し、1つになるまで同様に繰り返す. ・ 右の子、左の子に01を割当ててコード化すると、各文字を01のコードに割当てられる。 最適な圧縮形式になっている A9. B6. C5. D4. E3. F8.")
24
練習問題:ヒープ ・ 以下の数値でヒープを作り、そこに 7, 2, 13 を順に挿入せよ 4, 6, 8, 9, 11, 15, 17

25
メモリ効率を上げる 1 2 3 4 5 6 7 8 9 10 11 12 ・ このヒープは、値を n 個覚えるのに、メモリを 2n-1 使う
2倍程度使っている ・ もう少し効率良くならないか 中間セルにも値が蓄えられているようにすればいい 1 2 3 4 5 6 7 8 9 10 11 12

26
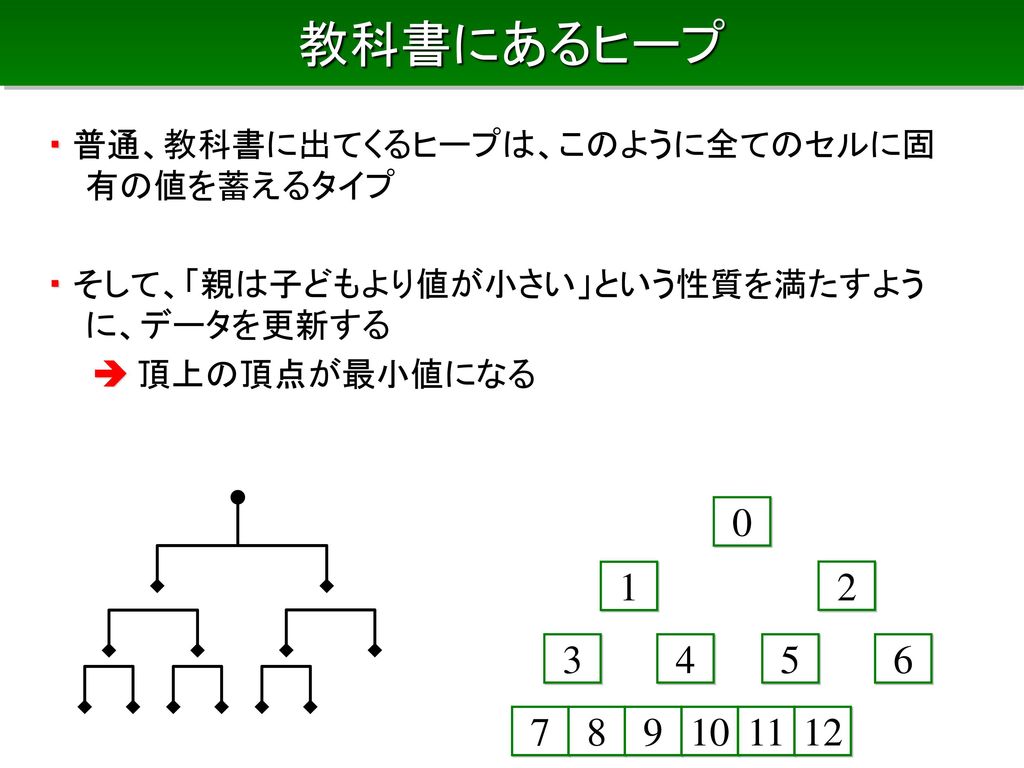
教科書にあるヒープ ・ 普通、教科書に出てくるヒープは、このように全てのセルに固有の値を蓄えるタイプ ・ そして、「親は子どもより値が小さい」という性質を満たすように、データを更新する 頂上の頂点が最小値になる 1 2 3 4 5 6 7 8 9 10 11 12
27
ヒープの更新 - 値の変更は、小さくなったら、親と入れ替え、大きくなったら、子と入れ替え、を再帰的に - 挿入は、一番右下にセルを追加 - 削除は、一番右下をコピーし、値を更新し、サイズを1つ減少 ・ だいたい、先ほどのヒープと同じやり方でできる 7 2 9 8 3 7 10 11 9 10 4 4

28
数値の変更のコード ・ ヒープの構造体は、前回と同じ ・ i 番目のセルの値を a に変更するルーチン
void HEAP_chg ( AHEAP *H, int i, int a ){ int aa = H->h[i]; H->h[i] = a; if ( aa > a ) HEAP_chg_up ( H, i ); if ( aa < a ) HEAP_chg_down ( H, i ); } typedef struct { int *h; // array for values int end; // size of array int num; // current size of heap } HEAP;
{ int aa = H->h[i]; H->h[i] = a; if ( aa > a ) HEAP_chg_up ( H, i ); if ( aa < a ) HEAP_chg_down ( H, i ); } typedef struct { int *h; // array for values. int end; // size of array. int num; // current size of heap. } HEAP;")
29
ヒープの更新 (上り) ・ ヒープを更新する際には、値を小さくしたときは上に、値を大きくしたときは下に、親子の入れ替えをしながら進む
void HEAP_up ( AHEAP *H, int i ){ int a; while ( i>0 ){ if ( H->h[(i-1)/2]<= H->h[i] ) break; a = H->h[(i-1)/2]; H->h[(i-1)/2] = H->h[i]; H->h[i] = a; i = (i-1)/2 } ・ セルの値を変更すると、場所が入れ替わるので、各値の場所を覚えておきたいときには不向き typedef struct { int *h; // array for values int end; // size of array int num; // current size of heap } HEAP;
{ int a; while ( i>0 ){ if ( H->h[(i-1)/2]<= H->h[i] ) break; a = H->h[(i-1)/2]; H->h[(i-1)/2] = H->h[i]; H->h[i] = a; i = (i-1)/2. } ・ セルの値を変更すると、場所が入れ替わるので、各値の場所を覚えておきたいときには不向き. typedef struct { int *h; // array for values. int end; // size of array. int num; // current size of heap. } HEAP;")
30
ヒープの更新 (下り) ・ 値を大きくしたときは、子どもより親のほうが小さくなるかもしれない
・ その際には、子どもと親を入れ替えるのだが、その際に、値の小さいほうの子ども、と入れ替える必要がある void HEAP_down ( AHEAP *H, int i ){ int ii, a; while ( i<H->num/2 ){ ii = i*2+1; if (i*2+1 < H->num && H->h[ii]>H->h[ii+1]) ii = ii+1; if ( H->h[ii] >= H->h[i] ) break; a = H->h[ii]; H->h[ii] = H->h[i]; H->h[i] = a; i = ii; } typedef struct { int *h; // array for values int end; // size of array int num; // current size of heap } HEAP;
{ int ii, a; while ( i<H->num/2 ){ ii = i*2+1; if (i*2+1 < H->num && H->h[ii]>H->h[ii+1]) ii = ii+1; if ( H->h[ii] >= H->h[i] ) break; a = H->h[ii]; H->h[ii] = H->h[i]; H->h[i] = a; i = ii; } typedef struct { int *h; // array for values. int end; // size of array. int num; // current size of heap. } HEAP;")
31
閾値以下の値を全て見つける 7 2 9 8 3 7 10 11 9 10 4 4 ・ 再帰呼び出しで、比較的簡単に
int HEAP_findlow ( AHEAP *H, int a , int i ){ if ( i>=H->num ) return; if ( H->h[i] > a ) return; printf (“%d\n”, H->h[i] HEAP_findlow ( H, a, i*2+1) HEAP_findlow ( H, a, i*2+2) } 7 2 9 8 3 7 10 11 9 10 4 4
{ if ( i>=H->num ) return; if ( H->h[i] > a ) return; printf ( %d\n , H->h[i] HEAP_findlow ( H, a, i*2+1) HEAP_findlow ( H, a, i*2+2) }")
32
練習問題:ヒープ (2) ・ 以下の数値で、教科書ヒープを作り、そこに 7, 2, 13 を順に挿入せよ
4, 6, 8, 9, 11, 15, 17

33
~余談~: 実際のヒープの速度 ・ ヒープを検索/更新する時間は O(log n)
~余談~: 実際のヒープの速度 ・ ヒープを検索/更新する時間は O(log n) ・ しかし、実際にプログラミングしてみると、100万要素くらいあっても、普通にメモリアクセスするのに比べて 4-5倍程度しか時間がかからない (log2 100万 ≒ 20 ) ・ なぜだろうか
 ・ しかし、実際にプログラミングしてみると、100万要素くらいあっても、普通にメモリアクセスするのに比べて 4-5倍程度しか時間がかからない (log2 100万 ≒ 20 ) ・ なぜだろうか.")
34
~余談~: 実際のヒープの速度 (2) ・ ヒープを検索/更新するときは、葉から根までを更新する
~余談~: 実際のヒープの速度 (2) ・ ヒープを検索/更新するときは、葉から根までを更新する ・ 1回アクセスすると、アクセスした部分はキャッシュに入り、次回短時間でアクセスできる ・ 何回も繰り返すと、根に近い部分は全部キャッシュに入ってしまう。時間がかかるのは、下の部分だけ ・ キャッシュに入らないのが、4-5レベル ということ
 ・ ヒープを検索/更新するときは、葉から根までを更新する. ・ 1回アクセスすると、アクセスした部分はキャッシュに入り、次回短時間でアクセスできる. ・ 何回も繰り返すと、根に近い部分は全部キャッシュに入ってしまう。時間がかかるのは、下の部分だけ. ・ キャッシュに入らないのが、4-5レベル. ということ.")
35
このあたりで木に関する用語の定義を ・ (グラフ理論では)頂点(あるいは点、ノード)、が 枝 で結ばれた構造をグラフという(枝は、2つの頂点を結ぶ) ・ グラフの中で、わっかになった構造を持たないものを木という ・ 頂上の頂点(根という)が指定されている木は根付き木という(アルゴリズムやプログラミングでは、これを木という) ・ 根付き木の頂点 x に対して、 - x に隣接し、 より根に近い頂点を(上の頂点)を親という - それ以外の隣接する頂点を子という - 頂点 x と根を結ぶ線上にある頂点を x の先祖という - x が先祖である頂点を x の子孫という - x の子孫からなる木を x の部分木という ・ 子どもを持たない頂点を 葉 という ・ 子どもを持つ頂点を 内点 という ・ 根から最も遠い葉までの距離を木の高さ(深さ)という ・ 子どもの数が2以下である木を2分木という ・ 子どもの数が0か2である木を完全2分木という (ヒープは完全2分木)
が指定されている木は根付き木という(アルゴリズムやプログラミングでは、これを木という) ・ 根付き木の頂点 x に対して、 - x に隣接し、 より根に近い頂点を(上の頂点)を親という. - それ以外の隣接する頂点を子という. - 頂点 x と根を結ぶ線上にある頂点を x の先祖という. - x が先祖である頂点を x の子孫という. - x の子孫からなる木を x の部分木という. ・ 子どもを持たない頂点を 葉 という. ・ 子どもを持つ頂点を 内点 という. ・ 根から最も遠い葉までの距離を木の高さ(深さ)という. ・ 子どもの数が2以下である木を2分木という. ・ 子どもの数が0か2である木を完全2分木という. (ヒープは完全2分木)")
36
任意の値を見つけたい ・ ヒープはシンプルで良いのだが、やはり、任意の値を短時間で見つけられるようにしたい ・ ヒープのように、トーナメント表のような構造を使うのはいいが、挿入の位置が固定されているので、順番を保持することができない(削除もそう) ・ 順番を保持できるようにする ためには、任意の場所に挿入 できないといけない 1 2 3 4 5 6 7 8 9 10 11 12

37
順番がそろっていると ・ 数値が順番どおりに入っていると、2分探索を、頂上から下にたどることで実現できる
・ 各ノードには、その子孫の最大の値を書くようにする 見つけたい数値がどちらにあるか、子どもを見ればわかる ・ では、順番を守ったまま、 挿入&削除をすることにしよう ・ 木の形はゆがんでもいいことにしよう ・ 前の数値があるノード(葉という) の下に子を2つ作り、挿入 ・ 葉を消して隣の葉の数値を 親にコピー
 の下に子を2つ作り、挿入. ・ 葉を消して隣の葉の数値を. 親にコピー.")
38
ゆがみをゆるすと ・ 検索の時間は、見つける葉までの深さ、ない場合は、隣合う葉の深いほうの葉の深さに比例
・ 木の形がきれい(バランスが取れている)なうちは、検索が速いが、やたら深いところが出てくると、遅くなる 同じところに挿入が続いた場合 ・ 検索の高速性を実現する ためには、何か工夫をしないと
なうちは、検索が速いが、やたら深いところが出てくると、遅くなる. 同じところに挿入が続いた場合. ・ 検索の高速性を実現する. ためには、何か工夫をしないと.")
39
ゆがみを矯正 ・ 検索の時間、最適なものは O(log n ) ・ では、定数 c に対して、c log n を超えないように調整しよう
・ 木に深いところがあるならば、必ずどこかに、浅い場所がある 浅い場所を深くして、深い場所を浅くできればいい その際、順番を変えないように ・浅いところを下げ、 深いところを上げ、 親を付け替えて、 バランスをとろう

40
バランスをとる 2以上 ・ 左右の子どもの部分木の高さが2以上異なる頂点が親子で続いているところを、構造を変えて高さをそろえる
(このような局所的な変更をオレンジ色の頂点に対する ローテート という) ・ ローテートすると高さがそろう(高さの差が2減る) 2以上
 ・ ローテートすると高さがそろう(高さの差が2減る) 2以上.")
41
このようにバランスの取れた木構造を、バランス木 とよぶ
木の高さは抑えられるか? ・ 「左右の子どもの部分木の高さが2以上異なる頂点が親子で続いているところ」がないようにする(ある限りローテートする) ・ 木の高さ k に関して、何かいえるか??? - 深さ k-1 の頂点(葉)が 1つある (根、あるいは根の子どもで分岐) - 深さ k-2 の頂点が 2つある (深さ 2,3 の頂点で分岐) - 深さ k-h の頂点が 2h-1 個ある (深さ2h,2h+1の頂点で分岐) 木の頂点数は、少なくとも 2k/3 ・ 葉の数が n なら、高さは 3log2 n = O(log n) このようにバランスの取れた木構造を、バランス木 とよぶ
 ・ 木の高さ k に関して、何かいえるか??? - 深さ k-1 の頂点(葉)が 1つある. (根、あるいは根の子どもで分岐) - 深さ k-2 の頂点が 2つある. (深さ 2,3 の頂点で分岐) - 深さ k-h の頂点が 2h-1 個ある. (深さ2h,2h+1の頂点で分岐) 木の頂点数は、少なくとも 2k/3. ・ 葉の数が n なら、高さは 3log2 n = O(log n) このようにバランスの取れた木構造を、バランス木 とよぶ.")
42
このようにバランスの取れた木構造を、バランス木 とよぶ
検索の時間 ・ 「ある数値があるか」を調べるには木を根から葉までたどる必要がある ・ 計算時間は、葉までの距離に比例。最悪でも木の高さ ・ 葉の数が n なら、高さは 3log2 n = O(log n) つまり、検索の時間は O(log n) このようにバランスの取れた木構造を、バランス木 とよぶ
 つまり、検索の時間は O(log n) このようにバランスの取れた木構造を、バランス木 とよぶ.")
43
ローテートの影響 ・ 頂点 x をローテートをした結果、ローテートする必要がなかったのに、ローテートする必要が出てくる頂点があるか?
・ つまり、条件を満たした木の構造に局所的な変化があったら、条件を守るようにするためには、その先祖に対してローテートしなければいけない

44
頂点の挿入と削除 ・ 木から頂点を削除/木に頂点を挿入すると、一部の頂点がローテートの条件を満たさなくなる
そのような頂点は、挿入/削除した場所の先祖 ・ 高さは高々1しか変わらないので、一回ローテートすれば条件を満たすようになる ・ 先祖に対して、山登り的にローテートを、不要になるまですればよい(一回不要になったら、それより上は必ず不要である) ・ 木の高さは O(log n)、ローテートは 定数時間でできるので、挿入/削除 してバランスをとる作業は O(log n) でできる
 ・ 木の高さは O(log n)、ローテートは. 定数時間でできるので、挿入/削除. してバランスをとる作業は. O(log n) でできる.")
45
他の基準によるローテート ・ 2つ下のレベルの部分木の大きさが、元の部分木の大きさの半分以上であるときに、ローテートする ・ ローテートすると大きさが(1以上)減る 2つ下がると大きさが半分以下になるまでローテートする 20 50% 30 30 20

46
木の高さ 20 30 50% ・ 2つ下がると大きさが半分以下、なので、 2log2 n 回以上下がれない
葉の数が n なら、高さは 4log2 n = O(log n) 20 50% 30
 % 30.")
47
頂点の挿入と削除 ・ このローテートは、先祖に対しても影響しない (ローテートしても子孫数に変化はない)
(ローテートしても子孫数に変化はない) ・ 挿入/削除した頂点の先祖に対して、山登り的にローテートをする ただし、不要になるまですればよい、というわけではない ・ 木の高さは O(log n)、ローテートは 定数時間でできるので、挿入/削除 してバランスをとる作業は O(log n) でできる
 ・ 挿入/削除した頂点の先祖に対して、山登り的にローテートをする. ただし、不要になるまですればよい、というわけではない. ・ 木の高さは O(log n)、ローテートは. 定数時間でできるので、挿入/削除. してバランスをとる作業は. O(log n) でできる.")
48
2分木の構造体 ・ ヒープのようにポインタなしで実現するのは難しいので、リストのように隣を指すポインタを用意しよう
・ バランスを取るため、高さやサイズのデータも保持しよう ・ リストのように、配列で実現しても良い typedef struct { BTREE *p; // -> parent BTREE *l; // -> left child BTREE *r; // -> rigth child int height; // height of subtree int value; // (max) value } BTREE;
 value. } BTREE;")
49
2分木の利用例 ・ 辞書のデータ、IDの管理 ・ 文書データのキーワード検索

50
練習問題: 2分木 ・ 以下の2分木をローテートせよ (高さが2以上違う場合、1つの子どもが子孫に葉を50%より真に大きい割合持つ場合)
")
51
たくさんの子ども ・ 2分木の内点は、必ず子どもを2人持っていた ・ 2つである意味は? - 更新の速度が最速 - 検索と更新が同じ速さ
- 更新の速度が最速 - 検索と更新が同じ速さ - 子どもの処理が簡単 ・ 子供2人以上をあり、にするとどうなるだろう ・ 2-3木という、子どもの数が2か3である木がある - 特徴は、どの葉も深さが同じということ - ただし、子どもに関する処理が面倒 (子どもが2人の場合、3人の場合で、 それぞれ最小がどこか、とか) ・ もっと子どもを増やしたら?
 ・ もっと子どもを増やしたら?")
52
B木 ・ 子どもの数が B 以下の木データ構造をB木という ・ わざわざ子どもを増やすのは、それなりの動機がある
・ ハードディスクやテープのような、アクセスに時間がかかるが、そこからある程度まとまったデータを取るのには時間がかからない、というような記憶装置を使う場合、計算時間のボトルネックは、検索/更新する際に、何個のノードを見たか、という点になる ・ それならば、各ノードの子どもの数を 増やせばよい

53
B木の更新 ・ B木を、「全てのノードがB個の子どもを持つ」とすると、効率が良いが、このようにきっちり条件を守るのは大変
・ しかし、どのノードも子どもが2-3人、となると、それはそれで効率が悪い B/2 以上 B 以下にする 親子、あるいは兄弟で、子どもの数が B/2 以下であるようなものがあれば、それらを合併して1つにする ローテートすれば、木の高さが O(logB/2 n) になる
 になる.")
54
まとめ ・ 2分探索: 半分に分割して、log n 回で見つける ・ ヒープ: トーナメント表の構造を保持して、最小値を更新
・ ヒープ: トーナメント表の構造を保持して、最小値を更新 ・ 2分木: 木構造のバランスとって、高さを抑える ・ B木: アクセスするノード数を最小化

Similar presentations



 アルゴリズムとデータ構造1 2008年7月22日 酒居敬一(sakai.keiichi@kochi-tech.ac.jp) http://www.info.kochi-tech.ac.jp/k1sakai/Lecture/ALG/2008/index.html.>")
.>")


 アルゴリズムとデータ構造 2013年6月18日 酒居敬一(sakai.keiichi@kochi-tech.ac.jp) http://www.info.kochi-tech.ac.jp/k1sakai/Lecture/ALG/2013/index.html.>")
 アルゴリズムとデータ構造 2010年7月5日 酒居敬一(sakai.keiichi@kochi-tech.ac.jp) http://www.info.kochi-tech.ac.jp/k1sakai/Lecture/ALG/2010/index.html.>")





:単純なソートアルゴリズム>")
 アルゴリズムとデータ構造 2012年6月14日 酒居敬一(sakai.keiichi@kochi-tech.ac.jp) http://www.info.kochi-tech.ac.jp/k1sakai/Lecture/ALG/2012/index.html.>")



