Download presentation
1
CPUの高速化テクニックから スーパーコンピュータまで
天野

2
VLSI設計論 (MIPSの設計、レイアウト) 4年春
SoC設計論 SoC設計演習 大学院 マイクロプロセッサアーキテクチャ特論 コンピュータアーキテクチャ特論 VLSI設計論 (MIPSの設計、レイアウト) 4年春 情報工学実験第2 (I/Oを含んだマイクロプロセッサ) 3年秋 コンピュータアーキテクチャ 3年春
 4年春. 情報工学実験第2 (I/Oを含んだマイクロプロセッサ) 3年秋. コンピュータアーキテクチャ. 3年春.")
3
高速化の流れ スレッドレベルの 高速化 Simultaneous Multithreading マルチコア化 複数命令の同時発行
(スーパースカラ) 命令レベルの 高速化 パイプラインを細かく (スーパーパイプライン) 周波数の向上 RISCの登場 パイプライン化 命令の動的スケジュール マルチコア 革命 1980 1990 2000
 命令レベルの. 高速化. パイプラインを細かく. (スーパーパイプライン) 周波数の向上. RISCの登場. パイプライン化. 命令の動的スケジュール. マルチコア. 革命")
4
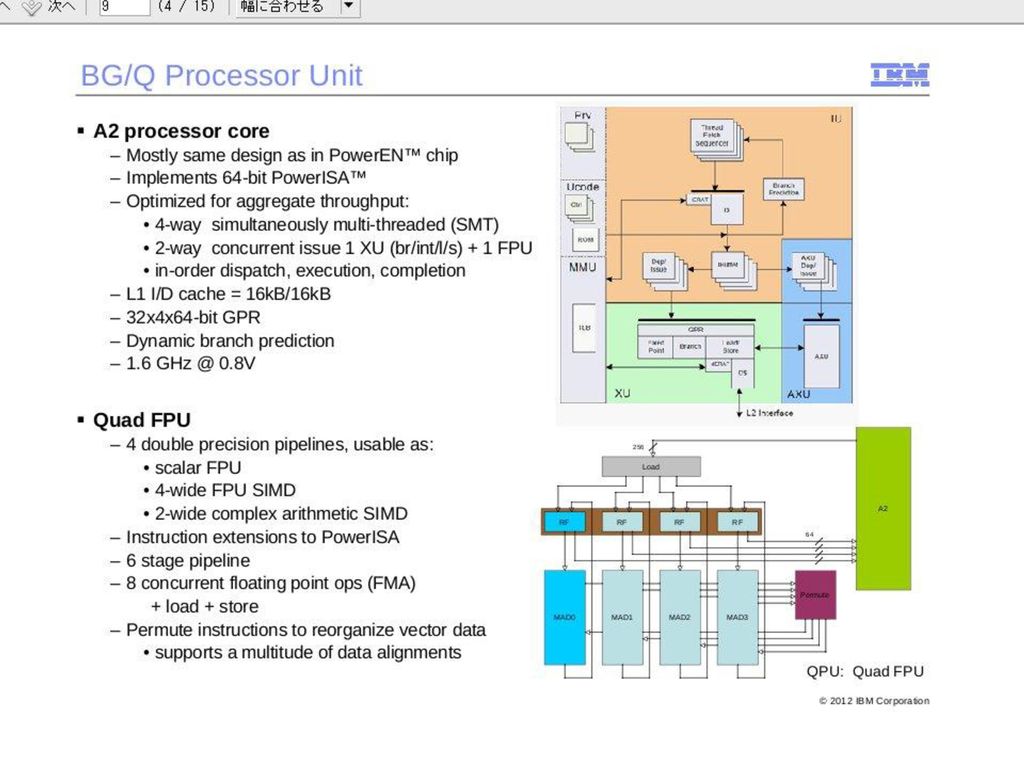
MIPSの命令セット 32ビットレジスタが32個ある 3オペランド方式 LD,STはディスプレースメント付き ADD R3,R1,R2
ADD R3,R1,R2 ADDI R3,R1,#1 LD R3, 10(R1) ST R1, 20(R2) BEQ R1,R2, loop
 ST R1, 20(R2) BEQ R1,R2, loop.")
5
命令フォーマット 3種類の基本フォーマットを持つ R-type I-type J-type opcode rs rt rd shift
amount function immediate target 31 26 25 21 20 16 15 11 10 6 5 op(opcode):命令の種類を表すオペコードフィールド。 FUNC(functional code):opフィールドで表現しきれない場合に補助オペコードとしてopフィールドを拡張する形で用いるフィールド。PICO-16ではopフィールドで2オペランドの算術論理演算命令を示し、ADDやSUBといった演算の種類をFUNCフィールドで特定する。 Rd(destination register):算術論理演算の計算結果やメモリからロードしてきたデータといった処理の結果を格納するレジスタ番号を指定するフィールド。PICO-16の演算ではRdの内容を1つのソースデータとしてRsの内容とADD等の演算を行い、Rdの内容を書きつぶして結果を書き込む。 Rs(source register):算術論理演算のソースデータを格納しているレジスタ番号を指定するフィールド。PICO-16では1つしか指定できないので2オペランド命令であるが、多くの32ビットアーキテクチャではRsを2つとRdを指定できる。 Immediate:命令に直接値を埋め込むのに使用するフィールド。PICO-16では算術論理演算のソースやレジスタに直接immediateの値をロードする際と、条件分岐命令の相対分岐オフセットに用いる。 Offset:immediateと同様に命令に直接値を埋め込むが、offsetフィールドはPC(プログラムカウンタ)のオフセットを指定するのに用いる。相対分岐命令で大きなプログラムの範囲を指定できるように、多くの命令セットにおいてoffsetフィールドができるだけ長くとれるように工夫してある。
:命令の種類を表すオペコードフィールド。 FUNC(functional code):opフィールドで表現しきれない場合に補助オペコードとしてopフィールドを拡張する形で用いるフィールド。PICO-16ではopフィールドで2オペランドの算術論理演算命令を示し、ADDやSUBといった演算の種類をFUNCフィールドで特定する。 Rd(destination register):算術論理演算の計算結果やメモリからロードしてきたデータといった処理の結果を格納するレジスタ番号を指定するフィールド。PICO-16の演算ではRdの内容を1つのソースデータとしてRsの内容とADD等の演算を行い、Rdの内容を書きつぶして結果を書き込む。 Rs(source register):算術論理演算のソースデータを格納しているレジスタ番号を指定するフィールド。PICO-16では1つしか指定できないので2オペランド命令であるが、多くの32ビットアーキテクチャではRsを2つとRdを指定できる。 Immediate:命令に直接値を埋め込むのに使用するフィールド。PICO-16では算術論理演算のソースやレジスタに直接immediateの値をロードする際と、条件分岐命令の相対分岐オフセットに用いる。 Offset:immediateと同様に命令に直接値を埋め込むが、offsetフィールドはPC(プログラムカウンタ)のオフセットを指定するのに用いる。相対分岐命令で大きなプログラムの範囲を指定できるように、多くの命令セットにおいてoffsetフィールドができるだけ長くとれるように工夫してある。")
6
パイプラインの概観 IF ID EX MEM WB ir + pc Decoder rwadr Register File dout0
control signals Decoder ir rwadr Register File MUX rs dout0 ALU aluout dout1 rd MUX MUX rt MUX imm 4 分岐(Branch)命令の処理はIFステージとRFステージで行う。条件分岐命令では条件の判別をどこで行うかによって分岐先のアドレスをフェッチするか続くアドレスをフェッチするかが決定するまでのクロックサイクル数が変化する。 分岐命令によって分岐先に飛ぶ前に、分岐命令の次の命令を必ず実行すると定める方法がある。この方法を用いると分岐先が決定するまで待たねばならないクロックサイクルに分岐命令の次の命令を実行して無駄をなくすことができる。その続く命令を実行するスロットをDelay Slotと呼ぶ。 今回のパイプラインではRFステージで条件を読み出すのと並列に分岐先を計算してIFステージに送り、IFステージでは条件の真偽が判別されしだいそれに従って続きのpcと計算された分岐先のpcを選択して命令フェッチを行う。この構造をとるとDelay Slotを1クロックサイクル必要とするが、構造は単純となる。Delay Slotが存在するとプログラムのコード自体をそのDelay Slot数に対応させて書き換える必要がある。 pcset hazard + MUX pc exfdata ALU badr ifpc memfdata idata iaddr ddataout daddr ddatain Instruction Memory Data Memory
命令の処理はIFステージとRFステージで行う。条件分岐命令では条件の判別をどこで行うかによって分岐先のアドレスをフェッチするか続くアドレスをフェッチするかが決定するまでのクロックサイクル数が変化する。 分岐命令によって分岐先に飛ぶ前に、分岐命令の次の命令を必ず実行すると定める方法がある。この方法を用いると分岐先が決定するまで待たねばならないクロックサイクルに分岐命令の次の命令を実行して無駄をなくすことができる。その続く命令を実行するスロットをDelay Slotと呼ぶ。 今回のパイプラインではRFステージで条件を読み出すのと並列に分岐先を計算してIFステージに送り、IFステージでは条件の真偽が判別されしだいそれに従って続きのpcと計算された分岐先のpcを選択して命令フェッチを行う。この構造をとるとDelay Slotを1クロックサイクル必要とするが、構造は単純となる。Delay Slotが存在するとプログラムのコード自体をそのDelay Slot数に対応させて書き換える必要がある。 pcset. hazard. + MUX. pc. exfdata. ALU. badr. ifpc. memfdata. idata. iaddr. ddataout. daddr. ddatain. Instruction. Memory. Data. Memory.")
7
パイプライン処理の問題点と その解決法 うまく動けば1クロックに1命令終わる
うまく動けば1クロックに1命令終わる CPI=1でクリティカルパスは1/(ステージ数) ステージ数分高速化、周波数向上のためにもステージ数を増やす スーパーパイプライン 命令間に依存性があると継続する命令が実行できずストール(失速)する データハザード できる命令から実行する 命令の動的スケジューリング:アウトオブオーダ実行 飛び先と飛ぶかどうかが分からないとストールする コントロールハザード 分岐予測 投機的実行:実行してしまって後で取り消す
 ステージ数分高速化、周波数向上のためにもステージ数を増やす. スーパーパイプライン. 命令間に依存性があると継続する命令が実行できずストール(失速)する. データハザード. できる命令から実行する. 命令の動的スケジューリング:アウトオブオーダ実行. 飛び先と飛ぶかどうかが分からないとストールする. コントロールハザード. 分岐予測. 投機的実行:実行してしまって後で取り消す.")
8
命令のアウトオブオーダ実行 トーマスローのアルゴリズム Hennessy & Patterson Computer Architecture より

9
スーパスカラ方式 2命令同時発行の例 (3,4命令同時発行も実現されている) 命令コードの互換性がある 命令実行制御がたいへん WB WB
EX EX 通常の命令 パイプライン RF RF IF IF 浮動小数点演算 パイプライン キャッシュ 通常の命令 浮動小数点演算命令 メモリシステム

10
VLIW(Very Long Instruction Word)方式
WB EX EX EX EX RF IF 4つの命令分の長い命令 実行の制御はコンパイラがあらかじめ行うので制御は簡単 コードの互換性がない

11
マルチスレッドとSMT(Simultaneous Multi-Threading)
Issue Slots Issue Slots Issue Slots Clock Cycles fine-grained multithreaded superscalar superscalar SMT

12
マルチコア、メニーコア 動作周波数の向上が限界に達する 命令レベル並列処理が限界に達する メモリのスピードとのギャップが埋まらない
消費電力の増大、発熱の限界 半導体プロセスの速度向上が配線遅延により限界に達する 命令レベル並列処理が限界に達する メモリのスピードとのギャップが埋まらない → マルチコア、メニーコアの急速な発達 マルチコア革命 年 プログラマが並列化しないと単一プログラムの性能が上がらない

13
プロセッサの動作周波数は2003年で限界に達した
クロック周波数の向上 Pentium4 3.2GHz Nehalem 3.3GHz 高速プロセッサのクロック周波数 周波数 1GHz 年間40% プロセッサの動作周波数は2003年で限界に達した 消費電力、発熱が限界に Alpha21064 150MHz 100MHz 1992 2008 2000 年

14
Flynnの分類 命令流(Instruction Stream)の数: M(Multiple)/S(Single)
データ流(Data Stream)の数:M/S SISD ユニプロセッサ(スーパスカラ、VLIWも入る) MISD:存在しない(Analog Computer) SIMD MIMD
の数:M/S. SISD. ユニプロセッサ(スーパスカラ、VLIWも入る) MISD:存在しない(Analog Computer) SIMD. MIMD.")
15
一人の命令で皆同じことをする SIMD 命令メモリ 半導体チップ内でたくさんの 演算装置を動かすには良い 方法 アクセラレータ(普通のCPU
にくっつけて計算能力を加速 する加速装置)の多くは この方式 安くて高いピーク性能が 得られる →パソコン、ゲーム機と 共用 命令 演算装置 Data memory
の多くは. この方式. 安くて高いピーク性能が. 得られる. →パソコン、ゲーム機と. 共用. 命令. 演算装置. Data memory.")
16
GPGPU:PC用 グラフィックプロセッサ
TSUBAME2.0(Xeon+Tesla,Top /11 4th ) 天河一号(Xeon+FireStream,2009/11 5th ) 近年、CPUとGPUやCELLといったマルチコアアクセラレータを組み合わせて使うハイブリッドの計算環境が普及しています。 例えばTOP500を見ると、TSUBAMEのNVIDIA GPUはもちろんですが、↑こういったATIのGPUを使ったスパコンも存在します。 またCell B.E.を搭載したアクセラレータもあります。 これらのアクセラレータを使って高い性能が得られるのですが、アクセラレータごとに異なる環境を用いなければなりませんでした。 そこで、Open CLという開発環境が登場しました。 OpenCLは、マルチコアプロセッサ向けの共通プログラミング環境で、Open CLにより、 異なるアーキテクチャでもCライクの同一ソースコードで開発が可能になりました。 ※()内は開発環境 16
 天河一号(Xeon+FireStream,2009/11 5th ) 近年、CPUとGPUやCELLといったマルチコアアクセラレータを組み合わせて使うハイブリッドの計算環境が普及しています。 例えばTOP500を見ると、TSUBAMEのNVIDIA GPUはもちろんですが、↑こういったATIのGPUを使ったスパコンも存在します。 またCell B.E.を搭載したアクセラレータもあります。 これらのアクセラレータを使って高い性能が得られるのですが、アクセラレータごとに異なる環境を用いなければなりませんでした。 そこで、Open CLという開発環境が登場しました。 OpenCLは、マルチコアプロセッサ向けの共通プログラミング環境で、Open CLにより、 異なるアーキテクチャでもCライクの同一ソースコードで開発が可能になりました。 ※()内は開発環境. 16.")
17
Thread Execution Manager
GeForce GTX280 240 cores Host Input Assembler Thread Execution Manager Thread Processors Thread Processors Thread Processors Thread Processors Thread Processors … PBSM PBSM PBSM PBSM PBSM PBSM PBSM PBSM PBSM PBSM Load/Store Global Memory

18
GPU (NVIDIA’s GTX580) L2 Cache 512 GPU cores ( 128 X 4 )
128個のコアは SIMD動作をする 4つのグループは 独立動作をする もちろん、このチップを たくさん使う 512 GPU cores ( 128 X 4 ) 768 KB L2 cache 40nm CMOS mm^2
 768 KB L2 cache. 40nm CMOS 550 mm^2.")
19
MIMD(Multipe-Instruction Streams/ Multiple-Data Streams)
Node 0 0 Node 1 1 2 Interconnection Network Node 2 3 メモリ空間 Node 3 独立して動けるプロセッサ を複数使う

20
MIMD(Multipe-Instruction Streams/ Multiple-Data Streams)の特徴
自分のプログラムで動けるプロセッサ(コア)を多数使う 同期:足並みを揃える データ交信:共通に使うメモリを持つなど 最近のPC用のプロセッサは全部この形を取っている 最近はスマートフォン用のCPUもマルチコア化
を多数使う. 同期:足並みを揃える. データ交信:共通に使うメモリを持つなど. 最近のPC用のプロセッサは全部この形を取っている. 最近はスマートフォン用のCPUもマルチコア化.")
21
Multi-Core (Intel’s Nehalem-EX)
CPU L3 Cache 8 CPU cores 24MB L3 cache 45nm CMOS 600 mm^2

22
Intel 80-Core Chip Intel 80-core chip [Vangal,ISSCC’07]
![Intel 80-Core Chip Intel 80-core chip [Vangal,ISSCC’07]](http://slidesplayer.net/slide/11382473/61/images/22/Intel+80-Core+Chip+Intel+80-core+chip+%5BVangal%2CISSCC%E2%80%9907%5D.jpg "Intel 80-Core Chip Intel 80-core chip [Vangal,ISSCC’07]")
23
まとめ 汎用プロセッサのマルチコア化は現在絶好調進行中 メニーコア 世代が進む毎に2ずつ増えている
しかし、コア数をこれ以上増やしても良いことがないかも、、、 メニーコア GPUなどのアクセラレータの性能向上は進む メニーコアによるクラウドコンピューティング

24
スーパーコンピュータ 特に科学技術計算が非常に速い計算機 医療、物理、天体、気象などの研究用の膨大な計算をする
非常に高価なため主として国の研究機関に設置 開発、運用のためには総合的な技術が必要 世界一高速なスーパーコンピュータはアメリカ、日本、中国で争ってきた 巨額の国家予算がつぎ込まれるため、政治的な関心が高い→2009年12月 事業仕分けの対象になる 「一番じゃなきゃいけないんですか?」 昨年、「京」が世界一を奪取、10PFLOPSを達成 今、最もマスコミが取り上げてくれるコンピュータ

25
FLOPSって何? Floating Point Operation Per Second:一秒間に実行できる浮動小数点演算の数
浮動小数とは? (仮数) × 2 (指数乗) で表す数 倍精度(64ビット)、単精度(32ビット)があり世界標準(IEEE標準)が決まっている 符号 指数 仮数 単精度 8ビット 23ビット 倍精度 11ビット 52ビット
 × 2 (指数乗) で表す数. 倍精度(64ビット)、単精度(32ビット)があり世界標準(IEEE標準)が決まっている. 符号. 指数. 仮数. 単精度. 8ビット. 23ビット. 倍精度. 11ビット. 52ビット.")
26
ペタフロップスって何? 10PFLOPS = 1秒に1京回浮動小数点演算を行う → 「京」の名前の由来 10の6乗 10の9乗 10の12乗
10の15乗 10の18乗 100万 M(メガ) 10億 G(ギガ) 1兆 T(テラ) 1000兆 P(ペタ) 100京 E(エクサ) スーパーコンピュータ 数10TFLOPS-10PFLOPS iPhone4S 140MFLOPS ハイスペックなPC 50-80GFLOPS アクセラレータ 数TFLOPS 注意! スーパーコンピュータの 性能向上率は1.9倍/年 10PFLOPS = 1秒に1京回浮動小数点演算を行う → 「京」の名前の由来
 10億. G(ギガ) 1兆. T(テラ) 1000兆. P(ペタ) 100京. E(エクサ) スーパーコンピュータ. 数10TFLOPS-10PFLOPS. iPhone4S. 140MFLOPS. ハイスペックなPC GFLOPS. アクセラレータ. 数TFLOPS. 注意! スーパーコンピュータの. 性能向上率は1.9倍/年. 10PFLOPS = 1秒に1京回浮動小数点演算を行う. → 「京」の名前の由来.")
27
世界一はどのように決まる? Top500/Green500 Linpackという行列計算プログラムを動かした場合の性能、性能/電力をランキング 演算性能重視 ゴードンベル賞 もっとも演算性能が高いマシン、値段が安くて性能の高いマシン、特徴のあるマシンを表彰 HPC Challenge Global HPL 行列演算: 演算性能 Global Random Access: メモリのランダムアクセス: 通信性能 EP stream per system: 多重負荷時のメモリアクセス: メモリ性能 Global FFT:演算性能と通信性能が共に要求されるやっかいな問題 11月 ACM/IEEE Supercomputing Conference Top500、ゴードンベル賞、HPC Challenge、Green500 6月 International Supercomputing Conference Top500、Green500

28
Top 5 Rmax: Peta FLOPS Sequoia USA 16PFLOPS 10 K Japan 9 8 3
Tianhe(天河) China 2 Jaguar USA Nebulae China 1 Kraken USA Roadrunner USA Tsubame Japan Jugene Germany 2010.6 2011.6
 China. 2. Jaguar USA. Nebulae. China. 1. Kraken USA. Roadrunner USA. Tsubame Japan. Jugene Germany")
29
SACSIS2012招待講演より

30
Top 500 2011 11月 ハードウェア コア数 名称 開発、設置場所 性能(ピーク)TFLOPS 電力(KW) K (京)
(Japan) RIKEN AICS SPARC VIIIfx 2.0GHz Tofu Interconnect Fujitsu 705024 10510 (11280) Tianhe-1A( 天河) (China) National Supercomputer Center Tenjien NUDT YH MPPXeon X5670 6C 2.93GHz,NVIDIA 2050 NUDT 186368 2566 (4701) 4040 Jaguar (USA) DOE/SC/Oak Ridge National Lab. Cray XT5-HE Opteron 6-Core 2.6GHz, Cray Inc. 224162 1759 (2331) 6950 Nebulae(China) National Supercomputing Centre in Shenzhen Dawning TC3600 Blade, Xeon X5650 6C 2.66GHz, Infiniband QDR, NVIDIA 2050,Dawing 120640 1271 (2974) 2580 TSUBAME2.0(Japan) GSIC,Tokyo Inst. of Technology HP ProLiant SL390s G7 Xeon 6C X5670, NVIDIA GPU,NEC/HP 73238 1192 (2287) 1398.6
 RIKEN AICS. SPARC VIIIfx 2.0GHz Tofu Interconnect. Fujitsu (11280) Tianhe-1A( 天河) (China) National Supercomputer Center Tenjien. NUDT YH MPPXeon X5670 6C 2.93GHz,NVIDIA 2050 NUDT (4701) Jaguar. (USA) DOE/SC/Oak Ridge. National Lab. Cray XT5-HE Opteron 6-Core 2.6GHz, Cray Inc (2331) Nebulae(China) National Supercomputing Centre in Shenzhen. Dawning TC3600 Blade, Xeon X5650 6C 2.66GHz, Infiniband QDR, NVIDIA 2050,Dawing (2974) TSUBAME2.0(Japan) GSIC,Tokyo Inst. of Technology. HP ProLiant SL390s G7 Xeon 6C X5670, NVIDIA GPU,NEC/HP (2287)")
31
Green 500 2011 11月 1-5位はIBM Blue Gene/Q 10位はTsubame-2.0(東工大) マシン 設置場所
FLOPS/W Total kW 1 BlueGene/Q, Power BQC 16C 1.60 GHz, Custom IBM - Rochester 85.12 2-5 BlueGene/Q Prototype IBM – Thomas J. Watson Research Center /Rochester 6 DEGIMA Cluster, Intel i5, ATI Radeon GPU, Infiniband QDR Nagasaki Univ. 47.05 7 Bullx B505, Xeon E5649 6C 2.53GHz, Infiniband QDR, NVIDIA 2090 Barcelona Supercomputing Center 81.50 8 Curie Hybrid Nodes - Bullx B505, Nvidia M2090, Xeon E GHz, Infiniband QDR TGCC / GENCI 108.80 1-5位はIBM Blue Gene/Q 10位はTsubame-2.0(東工大)
")
32
一番じゃなきゃいけないんですか? Top500の一位に固執する必要はない 差が少しならばこだわっても意味がない
→ オリンピックではないので、、 Green500、ゴードンベル賞コスト対性能部門、HPC Challengeの各プログラム それぞれの上位のマシンはそれぞれの利用価値がある マスコミはあまり取り上げてくれないが、、 今までの歴史を見ると、一位は他を圧倒して登場する Top500の一位はゴードンベル賞、HPC Challengeも受賞する場合が多い 京は、Top500 1位、ゴードンベル賞性能部門、HPC Challenge4つすべてで受賞している 一位の宣伝効果は大きい 一定の間隔で一位を取れる技術を保持することは重要

33
プロセッサの動作周波数は2003年で限界に達した 京の動作周波数はその辺のパソコンのCPUよりも低い
スーパーコンピュータはなぜ速い ×凄く速いクロック(時間刻み)で動くから Pentium4 3.2GHz Nehalem 3.3GHz 高速プロセッサのクロック周波数 周波数 京2GHz 1GHz 年間40% プロセッサの動作周波数は2003年で限界に達した 消費電力、発熱が限界に Alpha21064 150MHz 京の動作周波数はその辺のパソコンのCPUよりも低い →発熱を抑えるため 100MHz 1992 2008 2000 年
で動くから. Pentium4. 3.2GHz. Nehalem. 3.3GHz. 高速プロセッサのクロック周波数. 周波数. 京2GHz. 1GHz. 年間40% プロセッサの動作周波数は2003年で限界に達した. 消費電力、発熱が限界に. Alpha MHz. 京の動作周波数はその辺のパソコンのCPUよりも低い. →発熱を抑えるため. 100MHz 年.")
34
並列処理の3つの方法 並列処理→ 皆で働けば速くなる:プロセッサコア(処理装置)をたくさんもつ 一人の命令で皆が同じことをやる 流れ作業
並列処理→ 皆で働けば速くなる:プロセッサコア(処理装置)をたくさんもつ 一人の命令で皆が同じことをやる SIMD (Single Instruction Stream Multiple Data Streams): シムディー 流れ作業 パイプライン処理、ベクトル計算機 皆でてんでんばらばらに計算するが、どこかで歩調を合わせる MIMD(Multiple Instruction Streams Multiple Data Streams): ミムディー、マルチコア、メニーコア、スカラー計算機 どのマシンも3つの方法を色々なレベルで使っている しかし、使い方によっていくつかの種類に分けることができる たくさんのプロセッサをちゃんと動かすために 巨大、高速なメモリ、ディスク 高速な結合網
をたくさんもつ. 一人の命令で皆が同じことをやる. SIMD (Single Instruction Stream Multiple Data Streams): シムディー. 流れ作業. パイプライン処理、ベクトル計算機. 皆でてんでんばらばらに計算するが、どこかで歩調を合わせる. MIMD(Multiple Instruction Streams Multiple Data Streams): ミムディー、マルチコア、メニーコア、スカラー計算機. どのマシンも3つの方法を色々なレベルで使っている. しかし、使い方によっていくつかの種類に分けることができる. たくさんのプロセッサをちゃんと動かすために. 巨大、高速なメモリ、ディスク. 高速な結合網.")
35
ピーク(最大)性能と Linpack性能 Peta FLOPS 11 K Japan 10 5 4 Tianhe(天河) China 3
アクセラレータタイプは ピークとLinpack性能の 差が大きい 4 Tianhe(天河) China ホモジーニアス アクセラレータ GPU利用 3 Nebulae China 2 Tsubame Japan Jaguar USA 1 アクセラレータタイプは エネルギー効率が良い
 China. ホモジーニアス. アクセラレータ. GPU利用. 3. Nebulae. China. 2. Tsubame Japan. Jaguar USA. 1. アクセラレータタイプは. エネルギー効率が良い.")
36
パイプライン処理 それぞれのステージは自分の仕事が終わったら結果を次に渡す ステージの実行時間が同じならば、6倍に性能が上がる
1 2 3 4 5 6 ステージ それぞれのステージは自分の仕事が終わったら結果を次に渡す ステージの実行時間が同じならば、6倍に性能が上がる 要するに流れ作業 結果が出るまで次の作業ができない場合は、パイプラインに泡が入ってしまう → しかし行列計算など独立に計算ができれば有利!

37
ベクトル処理 (ベクトル計算機) 行列が長ければ効率が良い 古典的なスーパーコンピュータはベクトル型 (地球シミュレータ) 最近は減っている
ベクトルレジスタ a0a1a2….. 乗算器 加算器 X[i]=A[i]*B[i] Y=Y+X[i] b0b1b2…. 行列が長ければ効率が良い 古典的なスーパーコンピュータはベクトル型 (地球シミュレータ) 最近は減っている
 最近は減っている.")
38
ベクトル処理 (ベクトル計算機) ベクトルレジスタ a1a2….. 乗算器 加算器 a0 b0 X[i]=A[i]*B[i]
Y=Y+X[i] b1b2….
![ベクトル処理 (ベクトル計算機) ベクトルレジスタ a1a2….. 乗算器 加算器 a0 b0 X[i]=A[i]*B[i]](http://slidesplayer.net/slide/11382473/61/images/38/%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E5%87%A6%E7%90%86+%EF%BC%88%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E8%A8%88%E7%AE%97%E6%A9%9F%EF%BC%89+%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF+a1a2%E2%80%A6..+%E4%B9%97%E7%AE%97%E5%99%A8+%E5%8A%A0%E7%AE%97%E5%99%A8+a0+b0+X%5Bi%5D%3DA%5Bi%5D%EF%BC%8AB%5Bi%5D.jpg "Y=Y+X[i] b1b2….")
39
ベクトル処理 (ベクトル計算機) ベクトルレジスタ a2….. 乗算器 加算器 a1 a0 b0 b1 X[i]=A[i]*B[i]
Y=Y+X[i] b2….
![ベクトル処理 (ベクトル計算機) ベクトルレジスタ a2….. 乗算器 加算器 a1 a0 b0 b1 X[i]=A[i]*B[i]](http://slidesplayer.net/slide/11382473/61/images/39/%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E5%87%A6%E7%90%86+%EF%BC%88%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E8%A8%88%E7%AE%97%E6%A9%9F%EF%BC%89+%E3%83%99%E3%82%AF%E3%83%88%E3%83%AB%E3%83%AC%E3%82%B8%E3%82%B9%E3%82%BF+a2%E2%80%A6..+%E4%B9%97%E7%AE%97%E5%99%A8+%E5%8A%A0%E7%AE%97%E5%99%A8+a1+a0+b0+b1+X%5Bi%5D%3DA%5Bi%5D%EF%BC%8AB%5Bi%5D.jpg "Y=Y+X[i] b2….")
40
ベクトル処理 (ベクトル計算機) ベクトルレジスタ a11….. 乗算器 加算器 a10 x1 a9 x0 b9 b10
X[i]=A[i]*B[i] Y=Y+X[i] b11….

41
MIMD(Multipe-Instruction Streams/ Multiple-Data Streams)
Node 0 0 Node 1 1 2 Interconnection Network Node 2 3 メモリ空間 Node 3 独立して動けるプロセッサ を複数使う

42
日本のスーパーコンピュータ紹介 「京」スーパーコンピュータ 地球シミュレータ 東工大 Tsubame 長崎大 DEGIMA
現在の世界一、ホモジーニアスなマルチコア、スカラプロセッサ アクセラレータを用いず久々に一位を奪取、使いやすい 地球シミュレータ ベクトル計算機で世界一を取った最後?のコンピュータ ピーク性能と実効性能の差が小さい 東工大 Tsubame アクセラレータ(GPU)を多数利用、電力比に優れたスーパーコンピュータ 長崎大 DEGIMA アクセラレータを利用、手作り感のあるスーパーコンピュータ、優れたコストパフォーマンス、エネルギー効率、ゴードンベル賞受賞 GRAPEプロジェクト 天体物理学用、専用計算機、SIMD、様々なマシンがゴードンベル賞を何度も受賞しているユニークなスーパーコンピュータ
を多数利用、電力比に優れたスーパーコンピュータ. 長崎大 DEGIMA. アクセラレータを利用、手作り感のあるスーパーコンピュータ、優れたコストパフォーマンス、エネルギー効率、ゴードンベル賞受賞. GRAPEプロジェクト. 天体物理学用、専用計算機、SIMD、様々なマシンがゴードンベル賞を何度も受賞しているユニークなスーパーコンピュータ.")
43
Top1を取った日本製スーパーコンピュータ
一位の時期 マシン名 性能 TFLOPS 製造 方式 2011.6~ K(京) 10510 富士通 スカラ 702024コア、6次元Torus 2002.6~2004.6 地球シミュレータ 35.86 NEC ベクトル CP-PACS 0.3672 日立
 富士通. スカラ. 702024コア、6次元Torus. 2002.6~2004.6. 地球シミュレータ NEC. ベクトル CP-PACS 日立.")
44
SACSIS2012招待講演より

45
スーパーコンピュータ「京」 L2 C Core Core Tofu Interconnect 6-D Torus/Mesh Core
Memory L2 C Core Core Tofu Interconnect 6-D Torus/Mesh Core Core Inter Connect Controller Core Core Core Core SPARC64 VIIIfx Chip RDMA mechanism NUMA or UMA+NORMA 4 nodes/board 96nodes/Lack 24boards/Lack

46
SACSIS2012招待講演より

47
SACSIS2012招待講演より

48
水冷式のボード構成

49
京 のラック構成

50
6次元トーラス Tofu

51
SACSIS2012招待講演より

52
京はなぜ世界一になれたのか? アメリカの国家プロジェクトが中止、遅延した NEC/日立の撤退により複合システムが単一システムに変更された
財政危機の影響 NEC/日立の撤退により複合システムが単一システムに変更された 資金の効率的な利用、ノード数の増大 事業仕分けされかかったことで注目があつまった 理研、文科省が賢明な計画、資金集中を行った 富士通の技術者の設計が優れていた。 実装もがんばって短期間で大規模システムを稼動させた

56
エクサスケールコンピュータ エクサスケールは既に各国の視野に入っている
「京」は先月BlueGene Qで作られたSequoiaに首位を奪回された 次をどうするか? Feasibility Study(可能性の検討作業)が始まっている 今までのように独自LSIチップで首位を取ることができないかも スーパーコンピュータは「持ち出し」でやってきたが、もう日本の半導体企業にはその力がない 多額の国家予算がIntel、NVIDEAに流れることになる 単一のコアの性能向上はとっくの昔に終わっている あとは数を増やすこと、一定の空間にいかに演算能力を詰め込めるかが勝負 エクサスケール実現には7000万コアが必要! 性能向上の限界は? 技術的限界よりは資金的な限界が先に来るだろう
が始まっている. 今までのように独自LSIチップで首位を取ることができないかも. スーパーコンピュータは「持ち出し」でやってきたが、もう日本の半導体企業にはその力がない. 多額の国家予算がIntel、NVIDEAに流れることになる. 単一のコアの性能向上はとっくの昔に終わっている. あとは数を増やすこと、一定の空間にいかに演算能力を詰め込めるかが勝負. エクサスケール実現には7000万コアが必要! 性能向上の限界は? 技術的限界よりは資金的な限界が先に来るだろう.")
57
アムダールの法則 並列処理できない割合が 並列処理できる割合が99% 1% 並列に動いてコア数分の1に
しかし、100倍以上速くなることはない! 100コアで50倍、1000コアで91倍、70万コアで 倍 並列に実行できない部分が少しでもあったら、その割合で速度向上は制限される 京はiPhone3Sの1億倍速い。しかし、iPhone4Sで100時間掛かるアプリが 1ミリ秒で終わるかというと、終わらない可能性が高い

58
エクサスケールスーパーコンピュータは 役にたつのか?
解きたい問題のサイズが大きくなれば大きくなるほど、並列化できない部分は減ってくる。 並列化できない部分1日+並列化できる部分10年 → 1日+1日 で解ければインパクトが大きい 京では歯が立たず、エクサスケールならば解ける問題はどの程度あるのか? コンピュータのコア数が増えれば増えるほど、問題領域は減っていく可能性が高い 新しい領域を見つけることができるか? 今までにできなかったことができる、見えなかったものが見えることは間違いない 性急に成果を求められても多分無理だろう、、、 巨大な処理能力が研究用に開放されていることが重要

59
スーパーコンピュータを 作り続けたい コンピュータのハードウェア技術、ソフトウェア技術、信頼性管理技術、半導体開発技術、アプリケーション技術の結晶だから フラグシップであり、象徴だから 日本のコンピュータには他に何も残っていないから、、 研究用、平和利用に巨大計算能力が開放されているのは素晴らしいことだから それが役に立つかどうかは別として、できないことができ、見えないものが見えるから では無限に計算能力は必要なのか? 使われるプロセッサが全て米国製になっても日本で作り続ける意味があるのか? Linpackなどの数値計算に特化した(いわゆる)スーパーコンピュータを作り続けることに意味があるのか? エクサスケールコンピュータプロジェクトでは、これらの問いに答える必要がある
スーパーコンピュータを作り続けることに意味があるのか? エクサスケールコンピュータプロジェクトでは、これらの問いに答える必要がある.")


 とは? 2. Nvidia CUDA programming model 3. GPU の高速化 4. QCD with CUDA 5. 結果 6. まとめ 2.>")






 埼玉大学 理工学研究科 堀山 貴史>")






と状態で何をするか決める>")

>")


