Download presentation
1
データマイニング 湯山 悠司

2
いろんな論文を読んでみよう! キーワードとしてデータマイニング、エージェントの2つで検索

3
データマイニング手法を用いたモバイル エージェント分散データ検索システム
現在、周囲に多くのコンピュータデバイスがある PC、PDA、携帯電話など 将来、ユビキタス社会になるにつれて、冷蔵庫や電子レンジなども情報機能がつけられるのではないか

4
コンピュータデバイスはパーソナルなデータだけでなく、情報端末のある場所のあらゆる情報まで提供することができる
この分散された情報の中から自分の欲しいものだけを検索するために分散データの検索システムの構築が必要

5
検索対象が分散していて、検索のリアルタイム性が重要であるようなオープンな検索を行いたい場合、よく使われるのがバケツリレー方式
検索ターゲット候補にリクエストをマルチキャストして、さらにそれぞれの行き先に候補をリレーする 実際にGnutella(グヌーテラ)で採用 されている
で採用. されている.")
6
しかし、この方式ではネットワークに負担もかかり、検索の効率も悪い
そこでモバイルエージェントを用いた分散データ検索システム

7
特徴 複数のエージェントがシステム上で生きている 他のエージェントから情報を求め、自分の利用価値のある情報を吸収すればよい
同種のエージェント同士だけだと、単純に数が多くなって有用な情報を得られやすくなる 異種の場合はデータマイニングでプランニングを考案

8
評価の定義 ホストの履歴 エージェントの履歴
エージェントが様々なホストを歩き回り、そのホストで計算を行い、ホストに対して満足or不満足の評価をする ホストの履歴 ホストにはいろいろなエージェントが訪れるのでエージェントがホストに対しての評価した値をホストのログとして保存 エージェントの履歴 エージェントがホストを通過したときにホストの履歴を取って自分の分析対象として格納する 格納場所はモバイル性を考慮してホストに転送も考える

9
支持度計算 候補履歴の取得 確信度の計算 履歴を分析対象のトランザクションとして、ある支持度の範囲でバスケット分析を行う
エージェントの次の移動先を計算する時に、候補となるホストのリストをあげ、それらのホストに対して、ホストの履歴を問い合わせる 確信度の計算 ホストの履歴リストと支持度リストで各々ホストの確信度を計算する

10
候補選出 移動 計算の場所 確信度の計算で得られた確信度のうち、一番高い値のホストに移動先として決定
移動後は支持度計算に戻り、移動、分析の操作を繰り返す。満足できる値が取れれば終了 計算の場所 バスケット分析は大きな計算量が前提で正確結果を出すことが可能であるため、必ずしもユーザコンピュータで実行することはなく、場合によっては計算サーバが請け負う

11
まとめ 履歴の量が多くなるほど、正確な予想を出すことが可能になるが、計算量も多くなっていく
履歴のサイズは予測の結果とは無関係でありながら、計算速度を通す悪影響を与える この論文は予測の的中率だけしか出していないのでネットワーク上をいきわたる能力についても考察したい。

12
複数のデータベースからの エージェントデータベースマイニング
テキストDBを対象としたマイニングにおいて、マルチエージェント技術を用いる エージェントにDBへのアクセス、マイニングアルゴリズムの適用、結果の整理を行わせる。

13
分散データベースを用いる利点 単独のDBをマイニングするのとは違った見方になる可能性がある 分散してDBを管理したほうが管理しやすい
分析する目的、対象に応じて目的に沿ったマイニングがしやすい

14
複数のデータベースを扱うにあたって 同じ属性で記述されているとは限らない。 そのため、データの統一、変換が重要。

15
マルチエージェント データマイニング マルチエージェント技術を複数の独立したプログラムを強調動作させることにより、情報処理していく
この論文では1:1での通信モデルを使用 -black board

16
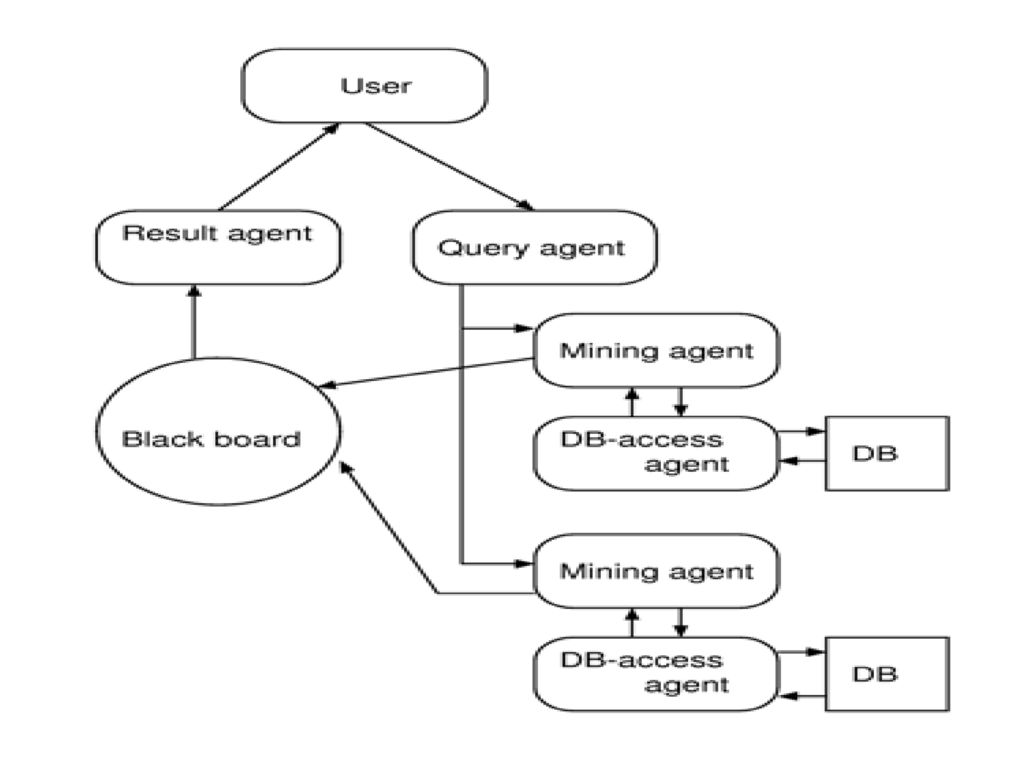
流れ ユーザはQuary Agent を生成し、使用するDB、マイニングアルゴリズムを選択 QAがBlack boardの場所を設定
QAがMining Agentを生成する QAがResult Agentを生成する MAはDB-Access Agentを生成してDBにアクセス DB-Access Agentはデータ取得 MAはDB-access Agent からデータを受け取り、マイニングアルゴリズムを適用する。 MAはデータマイニングの結果をBlack boardに 記入 RAはBlack boardをチェックして 結果がすべて書き込まれたらその結果を整理してユーザに見せる 全てのエージェントを消滅させる

18
結論 使用するDBやマイニングアルゴリズムの切り替えを行うことは可能
ただしこの構築した環境では単独でのデータマイニングと大差ないが、この枠組みを使えばネットワーク上で分散した環境でも構築可能である

19
今後やること 他の論文、特にエージェント関連のをもう少し読む
wekaがpostgreSQLのDBを読み込めることができるとわかったが、設定ができなかったのでその設定を次回までには!

20
参考文献 データマイニング手法を用いたモバイルエージェント分散データ検索システム, 何 斌達、相田 仁,
何 斌達、相田 仁, 東京大学 新領域創成科学研究科 基盤情報学 複数データベースからのエージェントベースデータマイニング、新美礼彦 公立はこだて未来大学システム情報科学部 朱鷺の杜Wiki





 エージェント移動の特徴 システム構成 エージェントプログラム>")


 ウ.ネットワークサービス制御技術>")




 とは、その名が示すとおり、「企業と顧客の双方の長期的な利益のために、見込み客を含む顧客 (カスタマー) との関係 (リレーション) を管理する包括的な方法」です。最近の CRM システムでは、顧客とのやり取りにかかわる情報を収集し、あらゆる顧客管理の機能や他のデータと連携させることができます。>")






>")
