Download presentation
Presentation is loading. Please wait.

1
大規模収集データに基づいた ソフトウェアエンジニアリング
SPES2003ソフトウェアプロセスエンジニアリングシンポジウム 大規模収集データに基づいた ソフトウェアエンジニアリング 井上克郎 大阪大学大学院情報科学研究科

2
ソフトウェア開発は工学?

3
ソフトウェア開発の現状と問題点 ソフトウェアの信頼性 ソフトウェアの生産性 経験的なノウハウや非科学的な手法,ツールを使う場合が多い
多数のバグを含んだソフトの流通 一度ダウンすると多大な社会的損失 ソフトウェアの生産性 開発期間の短縮要請 人海戦術による限界 経験的なノウハウや非科学的な手法,ツールを使う場合が多い

4
科学的手法に基づくソフトウェア開発 多くの他の科学、工学分野では、計測して定量化し、評価を行い、それをフィードバックして改善を行うのが普通(フィードバックループ) ソフトウェア開発の分野では?
 ソフトウェア開発の分野では?")
5
Zelkowitz-Wallaceによる評価法分類
観測型(Observational) 実際に行われているプロジェクトを横から観測して評価 履歴型(Historical) 過去に行われたプロジェクトのデータや発表された論文に基づいて評価 制御型(Controlled) 目的とするデータを得るために環境を整えてプロジェクトを行い評価する V. Zelkowitz, D. R.Wallace, "Experimental Models for Validating Technology", IEEE Computer, pp.23-31, May 1998.
 実際に行われているプロジェクトを横から観測して評価. 履歴型(Historical) 過去に行われたプロジェクトのデータや発表された論文に基づいて評価. 制御型(Controlled) 目的とするデータを得るために環境を整えてプロジェクトを行い評価する. V. Zelkowitz, D. R.Wallace, Experimental Models for Validating Technology , IEEE Computer, pp.23-31, May")
6
観測型評価 プロジェクトモニタ 事例研究 アサーション 野外調査(Field Study) 対象を漠然と観察。目標不明確な場合も。簡単
対象をより深く解析。まだ、変動要素の制御が不十分だが、比較的簡便 アサーション 主張がなりたつことを簡単なプロジェクトで実証。厳密な評価としては不十分。 野外調査(Field Study) いろいろなプロジェクトを見て回る。条件を揃えるのが困難だが追証しやすい。
 いろいろなプロジェクトを見て回る。条件を揃えるのが困難だが追証しやすい。")
7
履歴型 文献調査 事例調査 経験 (静的解析) 過去発表された論文を探す。条件や視点の統一不可能。簡単
過去のプロジェクトデータをひっくりかえす。条件不統一でデータ限られている 経験 過去のプロジェクトの定性的なデータを調べる。定性的な議論できない。やりやすくて簡単に傾向がわかる (静的解析) 作ったプロダクトの解析をする。方法には適用できない。評価の自動化できるかもしれない。
 作ったプロダクトの解析をする。方法には適用できない。評価の自動化できるかもしれない。")
8
制御型 繰返し 実験室 (動的解析) (シミュレーション) 条件を揃えていくつものプロジェクトで繰り返す。高価。
条件を揃えて実験室で繰り返す。スケーラビリティ。条件を制御しやすく比較的安価。 (動的解析) プロダクトの効率を実行させて計測。方法には適用できない。 (シミュレーション) 仮想データで実行。
 プロダクトの効率を実行させて計測。方法には適用できない。 (シミュレーション) 仮想データで実行。")
9
発表された論文の分類(他の科学) 方法\論文種類 デバイス 物理 臨床医学 人類学 評価なし 16% 58% 6% 31%
方法\論文種類 デバイス 物理 臨床医学 人類学 評価なし 16% 58% 6% 31% プロジェクトモニタ 事例評価 40% 16% 6% 8% アサーション 8% 4% 8% 野外調査 % 文献調査 4% 11% 24% 23% 事例調査 6% 23% 経験 5% 8% 静的解析 繰返し 5% 12% 実験室 % 動的解析 32% 5% シミュレーション

10
ソフトウェア工学の現状 30年に亘って,いろいろな技法,システム,ツールなどの提案がされてきた. あまりにも,言いっぱなしの提案が多い
評価するために手間暇かかる -> 歴史で評価 (ICSE n-10)
")
11
ソフトウェア工学の論文が使っている評価法
実験なし プロジェクトモニタ 事例研究 アサーション 野外調査 文献調査 評価法 1985 事例調査 1990 -ICSE -TSE -IEEE Software 1995 経験 静的解析 繰返し 実験室 動的解析 シミュレーション 0% 5% 10% 15% 20% 25% 30% 35% 40% 45% 論文の割合

12
Empirical Software Engineering

13
エンピリカルソフトウェア工学 定量的なデータに基づいてソフトウェア工学におけるいろいろな手法、技術、ツールなどの評価を行う
データの収集が必須 実際の開発現場のデータ オープンソース開発プロジェクトのデータ エンピリカルソフトウェア工学に関する雑誌、国際会議、研究機関ができつつある

14
Journal by Kluwer Empirical Software Engineering

15
2002 International Symposium on Empirical Software Engineering

16
Fraunhofer IESE Model Fraunhofer財団(政府系研究支援)
Institute for Experimental Software Engineering 大学工房モデル Kaiserslautern大学を基礎 大学から車で10分 仕事内容 ソフトウェア開発に関わる技術評価 ソフトウェア品質向上システムの設計 品質規格認証への支援 ソフトウェア技術者教育の支援 ソフトウェア購入・発注・開発管理の支援

17
Fraunhofer Institute for Experimental Software Engineering

18
これからの ソフトウェアエンジニアリング

19
データの粒度による分類 計測・検索 評価・分析 フィードバック 粒度 細 粗 目的 形態 対象 ユーザビリティ・問題把握
ヘルプ、ツール・ガイドライン 対象 各開発者の作業や生産物 プロジェクト群(企業内全資産、全オープンソース等) パターンや部品、知見の抽出、 利益予測 部品共通化、リファレンスモデル・標準化 単一プロジェクト 進捗把握、コスト管理 プロセス改善、資産再利用 既存のソフトウェア工学技術
 パターンや部品、知見の抽出、 利益予測. 部品共通化、リファレンスモデル・標準化. 単一プロジェクト. 進捗把握、コスト管理. プロセス改善、資産再利用. 既存のソフトウェア工学技術.")
20
粗粒度データを対象としたSE * (実用化はまだまだだが)ソフトウェア工学として細・中粒度はかなり研究されている
→ Local Software Engineering *粗粒度を陽に意識したソフトウェア工学まだない → Global Software Engineering * 組織の利益に直結する結果が得やすい * 基礎となる技術の種はいろいろある * 計算機のパワーアップ、ネットワークの高速化によって、実現できそうな気配

21
ターゲットとなる研究・開発 プロジェクトにまたがった大規模データの収集,蓄積技術(Inter-project Data Collection) 得られたデータを大域的に解析・評価技術(Global Analysis) 評価結果に基づいて経験や知識を資産化する技術(Software Asset Management) 粒度間の情報交換技術(Knowledge Circulation)
 粒度間の情報交換技術(Knowledge Circulation)")
22
目指すシステム

23
システム使用イメージ プログラムの生産性が、社内的な再利用やオープンソースの利用で劇的に上がる
管理しきれなかった膨大な社内資産が、見通しよく整理できた 過去の同類のプロジェクト情報を有効利用して、コスト管理が厳密になった 蓄積した欠陥情報を利用して、信頼性を大幅に改善された

24
関連基礎技術(1) コードクローン検出
 コードクローン検出")
25
コードクローン ソースコード中に類似したコード片があるとき、 それらをコードクローンという コードクローンはソフトウェア保守を困難にする
コードクローンはソフトウェア保守を困難にする クローンクラス クローンペア

26
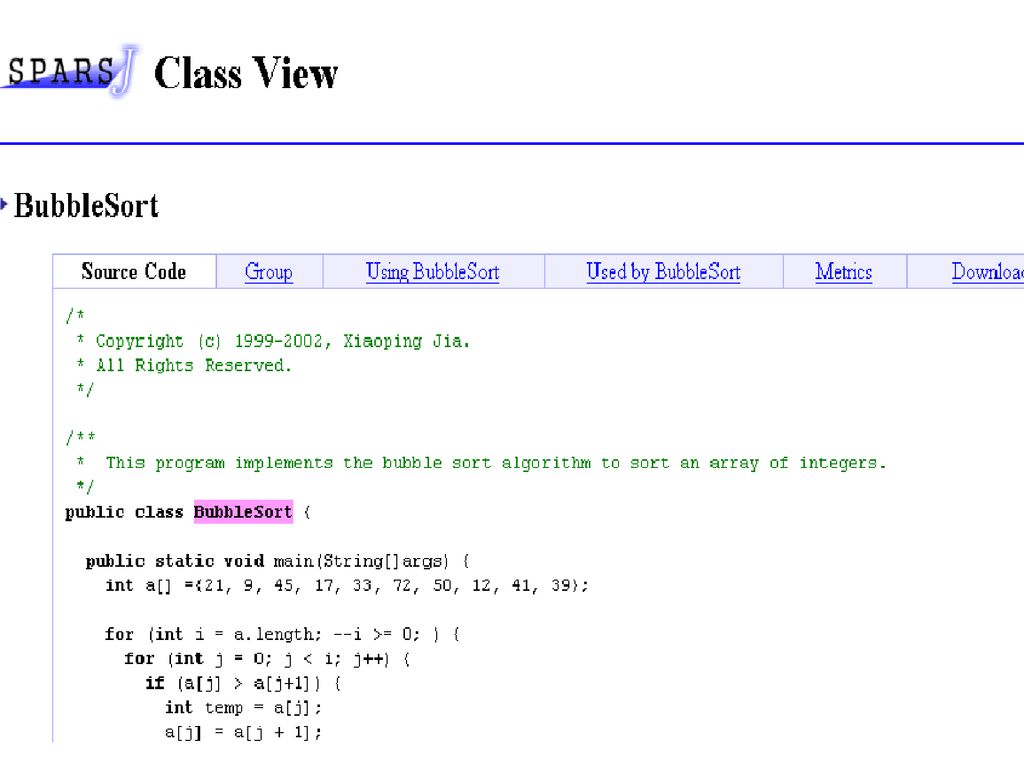
コードクローン検出ツーCCFinder ソースコードをトークン単位で直接比較することによりクローンを検出
数百万行規模のシステムにも実用時間で解析可能 実用的に意味のあるクローンのみを検出 名前空間の正規化(ユーザー定義名の置き換えに対処) テーブル初期化部分を取り除く モジュールの区切りを認識する
 テーブル初期化部分を取り除く. モジュールの区切りを認識する.")
27
CCFinderの処理概要(1) ソースコード CCfinder 字句解析 トークン列 変換処理 変換後トークン列 検出処理 クローン情報
出力整形処理 クローンペア位置情報

28
CCFinderの処理概要(2) 1. static void foo() throws RESyntaxException {
ソースコード 字句解析 1. static void foo() throws RESyntaxException { String a[] = new String [] { "123,400", "abc", "orange 100" }; org.apache.regexp.RE pat = new org.apache.regexp.RE("[0-9,]+"); int sum = 0; for (int i = 0; i < a.length; ++i) if (pat.match(a[i])) sum += Sample.parseNumber(pat.getParen(0)); System.out.println("sum = " + sum); 9. } 10. static void goo(String [] a) throws RESyntaxException { RE exp = new RE("[0-9,]+"); int sum = 0; for (int i = 0; i < a.length; ++i) if (exp.match(a[i])) sum += parseNumber(exp.getParen(0)); System.out.println("sum = " + sum); 17. } トークン列 変換処理 変換後トークン列 検出処理 クローン情報 出力整形処理 クローンペア位置情報
 throws RESyntaxException { 2. String a[] = new String [] { 123,400 , abc , orange 100 }; 3. org.apache.regexp.RE pat = new org.apache.regexp.RE( [0-9,]+ ); 4. int sum = 0; 5. for (int i = 0; i < a.length; ++i) 6. if (pat.match(a[i])) 7. sum += Sample.parseNumber(pat.getParen(0)); 8. System.out.println( sum = + sum); 9. } 10. static void goo(String [] a) throws RESyntaxException { 11. RE exp = new RE( [0-9,]+ ); 12. int sum = 0; 13. for (int i = 0; i < a.length; ++i) 14. if (exp.match(a[i])) 15. sum += parseNumber(exp.getParen(0)); 16. System.out.println( sum = + sum); 17. } トークン列. 変換処理. 変換後トークン列. 検出処理. クローン情報. 出力整形処理. クローンペア位置情報.")
29
CCFinderの処理概要(3) ソースコード 字句解析 トークン列 変換処理 変換後トークン列 検出処理 クローン情報 出力整形処理
クローンペア位置情報

30
CCFinderの処理概要(4) ソースコード 字句解析 トークン列 変換処理 変換後トークン列 検出処理 クローン情報 出力整形処理
クローンペア位置情報

31
CCFinderの処理概要(5) 1. static void foo() throws RESyntaxException {
ソースコード 1. static void foo() throws RESyntaxException { String a[] = new String [] { "123,400", "abc", "orange 100" }; org.apache.regexp.RE pat = new org.apache.regexp.RE("[0-9,]+"); int sum = 0; for (int i = 0; i < a.length; ++i) if (pat.match(a[i])) sum += Sample.parseNumber(pat.getParen(0)); System.out.println("sum = " + sum); 9. } 10. static void goo(String [] a) throws RESyntaxException { RE exp = new RE("[0-9,]+"); int sum = 0; for (int i = 0; i < a.length; ++i) if (exp.match(a[i])) sum += parseNumber(exp.getParen(0)); System.out.println("sum = " + sum); 17. } 字句解析 トークン列 変換処理 変換後トークン列 検出処理 クローン情報 出力整形処理 クローンペア位置情報
 throws RESyntaxException { 2. String a[] = new String [] { 123,400 , abc , orange 100 }; 3. org.apache.regexp.RE pat = new org.apache.regexp.RE( [0-9,]+ ); 4. int sum = 0; 5. for (int i = 0; i < a.length; ++i) 6. if (pat.match(a[i])) 7. sum += Sample.parseNumber(pat.getParen(0)); 8. System.out.println( sum = + sum); 9. } 10. static void goo(String [] a) throws RESyntaxException { 11. RE exp = new RE( [0-9,]+ ); 12. int sum = 0; 13. for (int i = 0; i < a.length; ++i) 14. if (exp.match(a[i])) 15. sum += parseNumber(exp.getParen(0)); 16. System.out.println( sum = + sum); 17. } 字句解析. トークン列. 変換処理. 変換後トークン列. 検出処理. クローン情報. 出力整形処理. クローンペア位置情報.")
32
適用例#1 JDKのライブラリ JDK(Java Development Kit) 1.2.2(サンプルとデモプログラムを除く)
入力ファイルは1648個,約50万行 ツールの実行には,Pentium III 650MHzおよび1GBのRAMを持つPCで約3分を要した

33
JDKのコードクローン散布図 両軸はソースファイルを辞書順に並べたもの 20行以上のコードクローンを図示
多くのコードクローンが密集している(A) 最長のコードクローン(B) B A
 最長のコードクローン(B) B. A.")
34
コードクローンが密集している部分(A) src/javax/swing/plaf/multi/*.java(29個)
クラス名を除いてまったく同じクラスの定義 コード生成ツールによって生成された 31| */ 32| public class MultiButtonUI extends ButtonUI { 33| 160| public static ComponentUI createUI(JComponent a) { 161| ComponentUI mui = new MultiButtonUI(); 162| return MultiLookAndFeel.createUIs(mui, 163| ((MultiButtonUI) mui).uis, 164| a); 165| }
 { 161| ComponentUI mui = new MultiButtonUI(); 162| return MultiLookAndFeel.createUIs(mui, 163| ((MultiButtonUI) mui).uis, 164| a); 165| }")
35
最長のコードクローン(B) 最長のコードクローン(349行) src/java/util/Arrays.javaの18の“sort”メソッド
シグネチャ(引数の型と数)が異なる アルゴリズムは同一
が異なる. アルゴリズムは同一.")
36
FreeBSD, Linux, NetBSDの比較
3つのOSの比較 FreeBSD 4.0 (C 220万行) Linux (C 240万行) NetBSD 1.5 (C 260万行) FreeBSDとNetBSDは同じソースコードから,Linuxは異なるソースコード 実行には108分を要した
 Linux (C 240万行) NetBSD 1.5 (C 260万行) FreeBSDとNetBSDは同じソースコードから,Linuxは異なるソースコード. 実行には108分を要した.")
37
UNIXカーネル間のコードクローン

38
FreeBSDとLinuxのコードクローン
ドライバ部分に多くのクローン「ファイル」が存在する 共通のソースから分岐したソースファイル 名前が付け替えられたソースファイル あるソースファイルを複数のファイルに分割している →

39
関連基礎技術(2) ソフトウェアシステムの類似度
 ソフトウェアシステムの類似度")
40
類似度の定義 二つのプロダクトP={p1,…,pm},Q={q1,…,qm}に対し、等価な要素の対応R⊆P×Qが得られるとする
PとQのRに対する類似度S(0≦S≦1)を以下のように定義する P Q ≡
を以下のように定義する. P. Q. ≡")
41
CCFinderを利用したシステム間類似度
SMMT 前処理後のP P Step1 Step2 Step3 前処理 CCFinder の実行 CCFinder の実行結果 diff の実行 Q diff の実行結果 前処理後のQ Step4 対応の 抽出 抽出結果 Step5 類似度の 計算 類似度

42
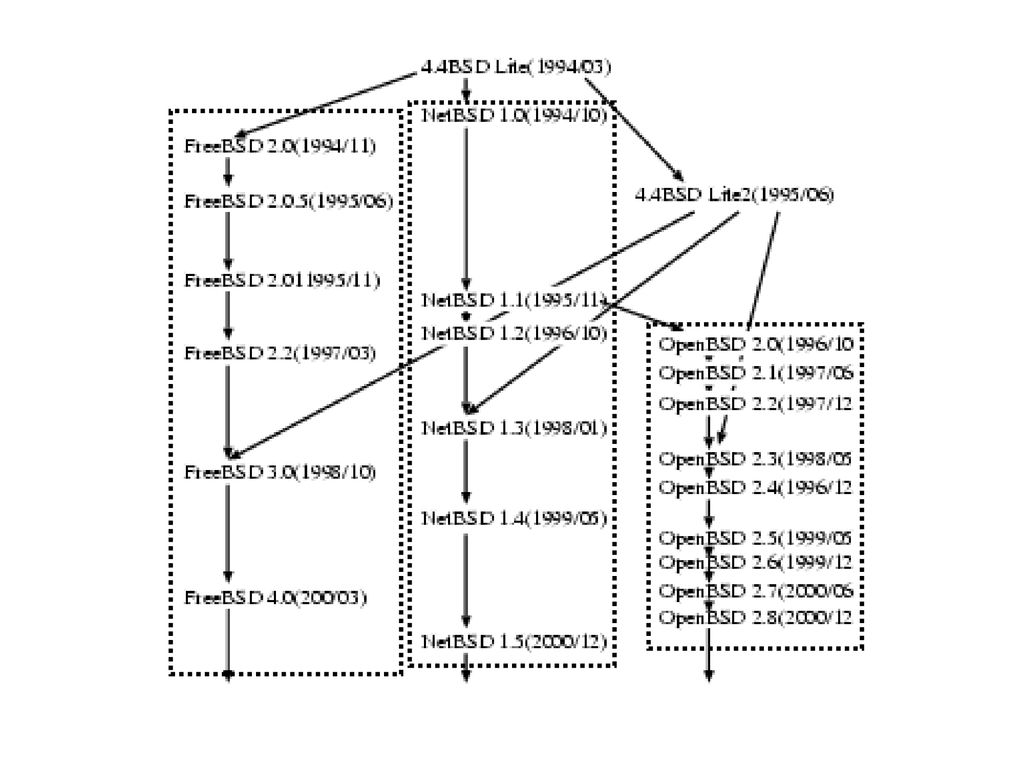
実験 UNIX系OSを用いて類似度を計算した 23個のOSのすべての組み合わせで類似度を求めた カーネル部分のC言語のソースのみ
4.4BSDLite, 4.4BSDLite2 FreeBSD2.0, 2.0.5, 2.1, 2.2, 3.0, 4.0 NetBSD1.0, 1.1, 1.2, 1.3, 1.4, 1.5 OpenBSD2.0, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8 23個のOSのすべての組み合わせで類似度を求めた カーネル部分のC言語のソースのみ

44
同一種類のOS間での類似度 FreeBSD 2.2との間の類似度

45
異なる種類のOS間での類似度 FreeBSD3.0とNetBSD1.3で4.4BSDLite2が取り込まれている

46
類似度を距離とした系統樹

47
関連基礎技術(3) ソフトウェア部品検索
 ソフトウェア部品検索")
48
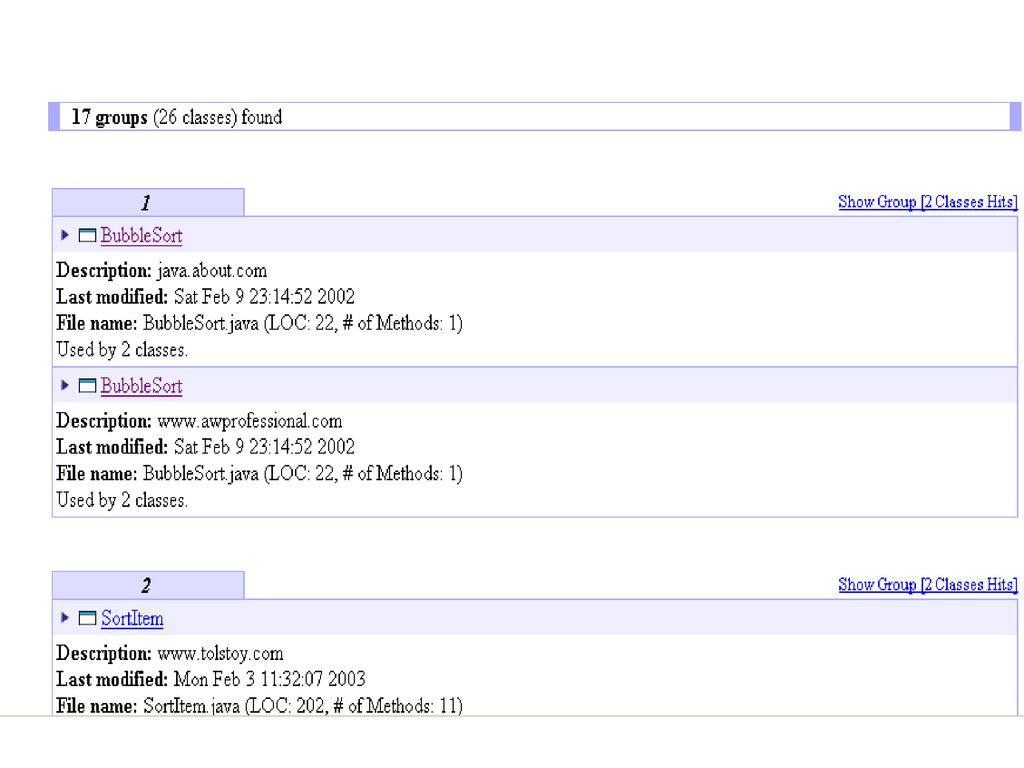
ソフトウェア部品の再利用 人手を介さない、自動的に保存、検索ができる部品ライブラリが必須 膨大なソフトウェアが毎日開発され続けている
同様なソフトウェア部品 (ライブラリやコード片、抽象的なアルゴリズム ...) が異なるところで独立に開発されているかもしれない 高信頼性、高生産性の鍵 再利用 ソフトウェアライブラリを探し回るのは大変 サーチ機能が貧弱 整合性を保った管理は困難 人手を介さない、自動的に保存、検索ができる部品ライブラリが必須 As you can see the case of SourceForge case, numerous ... In such a situation, similar components, which mean libraries,
 が異なるところで独立に開発されているかもしれない. 高信頼性、高生産性の鍵. 再利用. ソフトウェアライブラリを探し回るのは大変. サーチ機能が貧弱. 整合性を保った管理は困難. 人手を介さない、自動的に保存、検索ができる部品ライブラリが必須. As you can see the case of SourceForge case, numerous ... In such a situation, similar components, which mean libraries,")
49
部品ランクモデル 検索結果の表示順を決めるためのモデル プログラム部品(component)群をグラフ化 部品の重み計算
重みの順序:部品ランクComponent Rank (CR) As you can see the case of SourceForge case, numerous ... In such a situation, similar components, which mean libraries,
 As you can see the case of SourceForge case, numerous ... In such a situation, similar components, which mean libraries,")
50
部品グラフ 部品 利用 システム X システム Y A B F C G D E H I
We are going to introduce component rank model. First, we define a component graph. This is a directed graph, whose nodes are software components, and whose edges are use relations on component. 部品 利用

51
類似部品の集約 集約化した部品グラフ 部品グラフ C G C BF AD E G B F A D E
2nd adjustments is clustering components. This is a component graph. In this graph, component B and F are almost the same. Also, A and D are very similar. We merge these similar components into single components, and draw new edges to or from merged nodes, as shown here. We call this new graph, clustered component graph. This clustering operation is very important, because there are many copied components in software systems. 部品グラフ

52
部品の重み 0.4 0.2 0.2 A B 0.2 0.4 0.2 0.4 C 安定した重み配置は、隣接行列の固有値計算による
部品ランク : 頂点の重みの順 1:A, C 3:B

53
部品ランクモデルの意味 ユーザの視点移動をマルコフモデルで表したもの 単位時間ごとにユーザ視点が利用関係に沿って移動
0.01 0.02 0.03 0.05 0.001 0.1 ユーザの視点移動をマルコフモデルで表したもの 単位時間ごとにユーザ視点が利用関係に沿って移動 頂点の重みはユーザ視点の存在確率

54
部品ランクの適用例 JDK1.3(約1800ファイル)を対象として部品ランクを計算
言語仕様上、直接的、間接的に利用しなければならないクラスが上位を占めている

55
S P A R S-J Software Product Archiving, Analyzing and Retrieving System for Java Component Collector Analyzer and Evaluator インターネット・イントラネット Query Handler Component Archive ソフトウェア検索者 SPARS-J

59
エンピリカルソフトウェア工学 プロジェクトESEP

60
プロジェクト概要 文部科学省リーディングプロジェクト 2003年4月開始で5年計画 奈良先端科学技術大学院大学/大阪大学
e-society基盤ソフトウェア総合開発計画 2003年4月開始で5年計画 奈良先端科学技術大学院大学/大阪大学 産学連携の大学工房モデル

61
実践的ソフトウェア工学のための産学協力方式
大学工房モデル 実践的ソフトウェア工学のための産学協力方式 人材派遣 問題提供 予算提供 人材派遣 新しい技術 問題解決 ノウハウ吸収 人材育成 技術の評価結果 研究資金 新しいテーマの発見 大学 大学工房 産業界

62
エンピリカルソフトウェア工学ラボ 千里中央にオフィス 専任研究員、企業出向者、大学研究者、事務員滞在 研究開発のみならず交流の拠点
多様なソフトウェア工学に関する技術委員会 常に内外の市場調査

63
データに基づいたソフトウェア開発支援システム
海外との連携 グローバルな エンピリカル ソフトウェア工学研究グループ 各企業 フラウンホッファー 実験的ソフトウェア工学研究所 IESE 共同研究 フラウンホッファー 実験的ソフトウェア工学研究所 (独:Kaiseralautern) 所長:Dr.Dieter Rombach ( Kaiseralautern大学) 技術委員会 エンピリカルソフトウェア工学ラボ (大阪・千里中央) データに基づいたソフトウェア開発支援システム メリーランド、フラウンホッファー 実験的ソフトウェア工学センター FC-MD (米:Maryland) 所長:Dr.Victor Basili ( Maryland大学) 協力 大阪大学 奈良先端科学技術 大学院大学 エンピリカルソフトウェア工学 研究センタ CAESER (豪:シドニー) Dr.Ross Jeffery (ニューサウスウェールズ大学) 文部科学省 e-Society基盤ソフトウェア総合開発計画 IESE : Fraunhofer Institute for Experimental Software Engineering FC-MD: Fraunhofer Center for Experimental Software Engineering, Maryland CAESER: Center for Empirical Software Engineering Research Dr.B.Bohem
 所長:Dr.Dieter Rombach. ( Kaiseralautern大学) 技術委員会. エンピリカルソフトウェア工学ラボ. (大阪・千里中央) データに基づいたソフトウェア開発支援システム. メリーランド、フラウンホッファー. 実験的ソフトウェア工学センター. FC-MD. (米:Maryland) 所長:Dr.Victor Basili. ( Maryland大学) 協力. 大阪大学. 奈良先端科学技術. 大学院大学. エンピリカルソフトウェア工学. 研究センタ. CAESER. (豪:シドニー) Dr.Ross Jeffery. (ニューサウスウェールズ大学) 文部科学省. e-Society基盤ソフトウェア総合開発計画. IESE : Fraunhofer Institute for Experimental Software Engineering. FC-MD: Fraunhofer Center for Experimental Software Engineering, Maryland. CAESER: Center for Empirical Software Engineering Research. Dr.B.Bohem.")
64
ベースとなるシステム オープンソース開発管理システムを基本 既存のWebインターフェースの利用 CVS:レポジトリ構築、バージョン管理
MailMan:メール蓄積、管理 Gnats:バグ追跡 既存のWebインターフェースの利用 Corporate Source (ZeeSource)
")
65
System Architecture

66
グローバルSEのためのデータの標準化 プロダクトデータ プロセスデータ プロセス・プロダクト間関連データ CVSを使った各種プロダクトの履歴
プロダクト間の種々の関係定義をXMLで標準化 プロセスデータ XMLを使った標準形式のイベント系列を蓄積 CVS、MailMan、Gnatsのログなどから自動抽出(粗粒度情報) 各作業者の作業環境からの標準形式での情報提供(細粒度情報も可能) プロセス・プロダクト間関連データ
 各作業者の作業環境からの標準形式での情報提供(細粒度情報も可能) プロセス・プロダクト間関連データ.")
67
プロダクトデータに関して 関連情報の自動抽出 プロダクトの自動分類 再利用部品の抽出 プロダクト情報のインデキシング、蓄積手法
検索、ブラウジング手法

68
プロセスデータに関して プロダクトデータからプロセスデータの抽出法 プロセスデータの自動報告 プロセスデータの正規化手法
組織レベル、プロジェクトレベル、個人レベルそれぞれの解析 プロセス比較、評価手法

69
システムの使用イメージ(プロジェクト内)
予想進捗 投入コスト トータルサイズ 完成モジュール数 成功テストケース ドキュメント章数 バグレポート数 ... t work 平均作業量 開発者Xの作業量 t

70
システムの使用イメージ(プロジェクト比較)
progress Project A Project B Project C 進捗度の比較 バグ、信頼度の予測 t cost コストの比較 1 2 3 4 5 project

71
システムの使用イメージ(プロダクト) ソフトウェア部品、コード片検索 キーワード入力 コード片(クローン) 類似プロダクトの分類、整理
 ソフトウェア部品、コード片検索 キーワード入力 コード片(クローン) 類似プロダクトの分類、整理")
72
今後の計画 11月始めに、連携海外研究者と共同WS WSで本システムの初期バージョンの公開 初期バージョンの利用促進
評価に参加する協力企業の募集 それ以外の一般参加企業の募集

73
受託開発と開発データ この種の開発データの添付がソフトウェア受託開発の契約に重要になってくる
クリティカルシステムのみならず、一般のソフトウェアシステムでも社会的なインパクトが大きくなってきている ちゃんと開発しているかの把握、フェイクしにくい直接データ ちゃんと開発しているところにとっては容易なこと ISO9000やCMMのための基礎データとしても有用

Similar presentations