Download presentation
1
複数の言語情報を用いたCRFによる音声認識誤りの検出
神戸大学工学研究科情報知能学専攻 CS17 有木研究室 松本智彦

2
研究の背景 音声認識結果を用いたサービスを行う場合,音声認識誤りが性能に悪影響を与える 例:音声検索
発話文書A:民主党 は 野球 に 解散 する よう ・・・ 認識誤り Hit 検索結果 野球 ・・・

3
研究の目的 入力音声:”民主党 は 早急 に 解散 する よう ・・・” 認識結果:民主党 は 野球 に 解散 する よう ・・・
誤り検出: 正 正 誤 正 正 正 正 ・・・ 誤り検出ができると 誤り部分を除外⇒音声検索などに利用 誤り訂正へ 音声認識 各単語が正解か誤りかラベリング

4
誤り検出に関する従来研究 音声認識スコアを用いた手法 誤り傾向を示す言語情報の学習 意味情報を用いた手法 音声認識器の出力する情報
誤り部分で出現しやすい言語特徴 意味情報を用いた手法 周辺単語との類似度

5
誤り検出に関する従来研究 音声認識スコアを用いた手法 誤り傾向を示す言語情報の学習 意味情報を用いた手法 音声認識器の出力する情報
誤り部分で出現しやすい言語特徴 意味情報を用いた手法 周辺単語との類似度

6
音声認識スコアを用いた誤り検出 音声認識器の出力する などから各単語の信頼度を算出 ⇒信頼度が閾値以下のものを誤りとする
音響スコア:はっきりと発話されているかなど 言語スコア:出現しやすいn-gramかどうか 競合情報:競合候補単語の数など 周辺のスコア:誤りの伝搬 などから各単語の信頼度を算出 ⇒信頼度が閾値以下のものを誤りとする

7
誤り検出に関する従来研究 音声認識スコアを用いた手法 誤り傾向を示す言語情報の学習 意味情報を用いた手法 音声認識器の出力する情報
誤り部分で出現しやすい言語特徴 意味情報を用いた手法 周辺単語との類似度

8
誤り傾向を示す言語情報の学習 正解部分,誤り部分で出現しやすい特徴を学習する 例 学習には音声認識結果と対応する正解文書が必要
不自然なn-gram :「と-いう-ます」「し-き-まし」 不自然な接続 :「未然形-名詞」 音素数の多い単語は正解の可能性が高い 学習には音声認識結果と対応する正解文書が必要 ⇒出現頻度の低いn-gramについては適切に学習されない

9
誤り検出に関する従来研究 音声認識スコアを用いた手法 誤り傾向を示す言語情報の学習 意味情報を用いた手法 音声認識器の出力する情報
誤り部分で出現しやすい言語特徴 意味情報を用いた手法 周辺単語との類似度

10
意味情報を用いた誤り検出 周辺の認識結果を参照したときに,識別対象単語の出現が自然かどうか 例:
周辺の認識結果に「裁判」に関する単語が多い中で 「大根」の出現は不自然⇒誤りである可能性が高い 自然さを意味スコアとして算出する 犯罪 大根 弁護士 裁判 無罪

11
意味スコアの算出(1/2) wi w 周辺の内容語との類似度の平均: SC(w) 文脈窓:N単語 犯罪 裁判 大根 無罪 弁護士
単語共起を用いた類似度(LSA)
")
12
意味スコアの算出(2/2) wi w SC(w)を窓内のSC(wi)の平均で正規化:SS(w) 犯罪 裁判 大根 無罪 弁護士 ・ ・ ・
・ ・ ・ ・ ・ ・

13
意味スコア LSA:正しく書かれた文書のみから学習 どの単語と共起しても不自然でない「は」「です」のような機能語に対しては効果がない
⇒内容語として,名詞,動詞,形容詞のみを対象

14
従来手法 CRFに よる検出 閾値に よる検出 音声認識スコアを用いた手法 誤り傾向を示す言語情報の学習 意味情報を用いた手法
音声認識器の出力する情報 誤り傾向を示す言語情報の学習 誤り部分で出現しやすい言語特徴 意味情報を用いた手法 周辺単語との類似度 CRFに よる検出 閾値に よる検出

15
提案手法 CRFに よる検出 音声認識スコアを用いた手法 誤り傾向を示す言語情報の学習 意味情報を用いた手法
音声認識器の出力する情報 誤り傾向を示す言語情報の学習 誤り部分で出現しやすい言語特徴 意味情報を用いた手法 周辺単語との類似度+単語重み 内容語に対する誤り検出性能を向上させることはできないか CRFに よる検出

16
意味スコアとidfとの組み合わせ(1/2) 内容語の中にも「こと」「する」のような頻出単語が含まれる ⇒意味スコアがあまり意味をなさない
特定の文書でのみ出現する単語⇒大

17
意味スコアとidfとの組み合わせ(2/2) 意味スコアと誤り単語の割合(誤り率)の関係 idfが大きな単語ほど意味スコアの効果が大きい
全体の誤り率

18
Conditional Random Fieldによる誤り検出
素性関数:素性が存在するかしないか 素性:特徴とラベルのペア (信頼度0=“0.1”,”誤”) (表層-1=“基本” && 表層0=“周波” ,”正”) (SS0=“-0.1” && idf0=“8”,”誤”) 各素性の重みを学習 ⇒ 0.315 ⇒ 0.119 ⇒ 0.359 表層単語 所望 の 基本 周波 で おば ラッパー ・・・ 信頼度 0.7 0.2 0.8 0.0 0.1 品詞 名詞 助詞 SS * 0.05 -0.1 idf 9 3 6 8 正解ラベル 正 誤
 (表層-1= 基本 && 表層0= 周波 , 正 ) (SS0= -0.1 && idf0= 8 , 誤 ) 各素性の重みを学習. ⇒ ⇒ ⇒ 表層単語. 所望. の. 基本. 周波. で. おば. ラッパー. ・・・ 信頼度 品詞. 名詞. 助詞. SS. * idf 正解ラベル. 正. 誤.")
19
実験条件(1/2) コーパス:日本語話し言葉コーパス(CSJ) LSA 意味スコアの算出
2,672講演の書き起こし文書(評価データを含まない) 文書:内容語が30語程度出現するごとに区切ったもの 文書数:76,767 語彙数:48,371 次元数:100 意味スコアの算出 文脈窓:前10個,後ろ10個,対象単語の21個
 文書:内容語が30語程度出現するごとに区切ったもの. 文書数:76,767 語彙数:48,371 次元数:100. 意味スコアの算出. 文脈窓:前10個,後ろ10個,対象単語の21個.")
20
実験条件(2/2) 音声認識器:Julius(HMM+trigram) 誤り検出モデル:CRF++ 学習 評価 講演数 150 10 発話数
52,692 2,667 単語数 484,405 22,522 語彙数 10,418 2,348 内容語数 187,154 8,782 機能語数 297,251 13,740 誤り率 23.6% 25.8%

21
用いた素性 音声認識スコア 言語情報 意味情報 信頼度(前後2単語のものを含む) 表層単語1-gram,2-gram,3-gram
活用形-表層単語,活用形-品詞 読み 音素数1-gram,2-gram 意味情報 SC(w),SS(w)をidfと組み合わせたもの
,SS(w)をidfと組み合わせたもの.")
22
評価方法 検出の正確性 適合率=(正解誤り検出数)/(全誤り検出数) 検出の網羅性 再現率=(正解誤り検出数)/(全誤り数)
適合率と再現率の調和平均 F値=(2*適合率*再現率)/(適合率+再現率) 全単語,内容語のみ,機能語のみ,それぞれで評価
/(適合率+再現率) 全単語,内容語のみ,機能語のみ,それぞれで評価.")
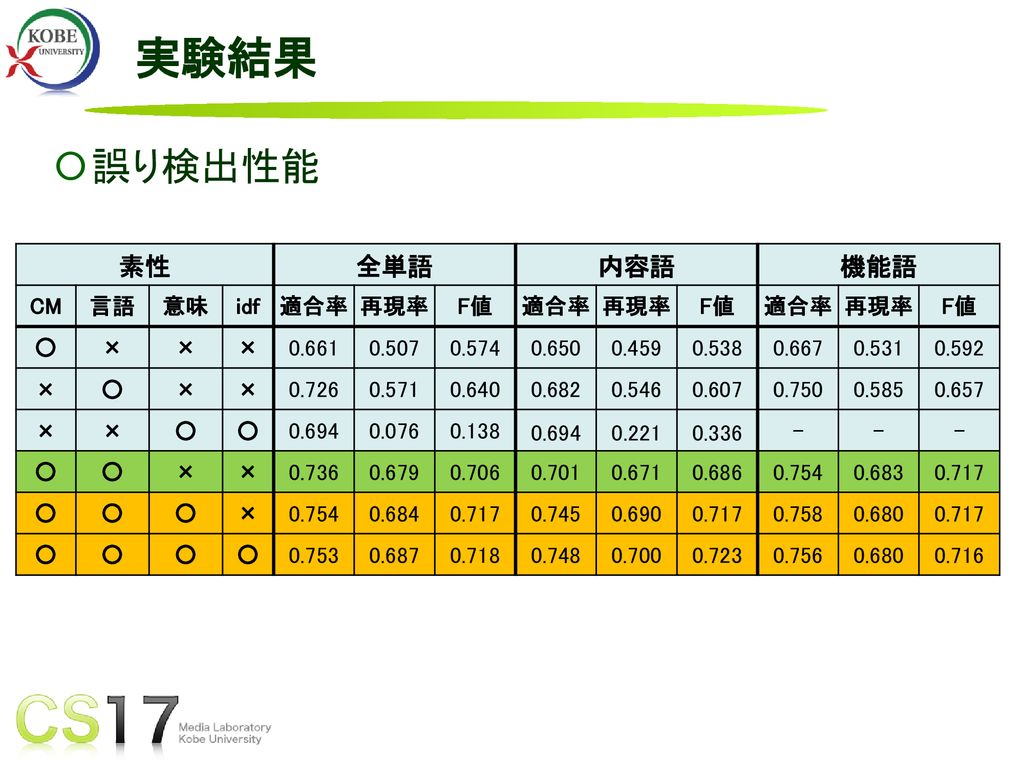
23
実験結果 誤り検出性能 素性 全単語 内容語 機能語 CM 言語 意味 idf 適合率 再現率 F値 ○ × 0.661 0.507
0.574 0.650 0.459 0.538 0.667 0.531 0.592 0.726 0.571 0.640 0.682 0.546 0.607 0.750 0.585 0.657 0.694 0.076 0.138 0.221 0.336 - 0.736 0.679 0.706 0.701 0.671 0.686 0.754 0.683 0.717 0.684 0.745 0.690 0.758 0.680 0.753 0.687 0.718 0.748 0.700 0.723 0.756 0.716
24
改善した具体例 周辺に「接尾」「活用」「語彙」「助詞」 ⇒「丹後(単語)」「イチゴ(一語)」に誤りのラベル 周辺に「対話」「発話」「時間」
⇒「包帯(おー対話)」「冗談(上段)」に誤りのラベル 周辺に「音楽」「歌っ」「弾い」 ⇒「ギター」に正解のラベル
」「冗談(上段)」に誤りのラベル. 周辺に「音楽」「歌っ」「弾い」 ⇒「ギター」に正解のラベル.")
25
考察 意味をもった単語の割合が少ないため,全単語での評価では改善率は低い 周辺に頻出単語や認識誤りが多いと意味スコアの性能が落ちる
⇒参照する単語の単語重みや認識スコアなども考慮

26
まとめと今後の予定 まとめ 今後の予定 従来用いられていた情報に意味スコアを追加することで,特に内容語の誤り検出性能が向上した
単語重みと組み合わせることで,意味スコアを有効に活用できた 今後の予定 他に誤り検出に有効な素性がないか検討 CRF以外の識別器を用いたときとの比較 誤り検出から誤り訂正へ

27
ご清聴ありがとうございました

29
Latent Semantic Analysis (LSA)
単語文書行列を特異値分解 学習データになかった共起関係も予測できる c1・・・ cj・・・ cN v1T・・・ vjT・・・ vNT r1 ・ ri rM W u1 ・ ui uM U S V T = R×R R×N M×N M×R

30
条件付き確率場(Conditional Random Field)
以下の条件付確率の尤度が最大になるように学習 fa:素性関数 λa:重み 時系列を入力 ⇒グローバルな最適解 学習では全てのラベル列を考慮 ⇒精度が安定

31
学習 正解文書 ラベリング 素性の生成 音声認識 意味スコア 算出 認識結果 入力音声 誤り検出モデル (CRF)
")
32
検出 検出結果 音声認識 意味スコア 算出 認識結果 入力音声 誤り検出モデル (CRF)
")
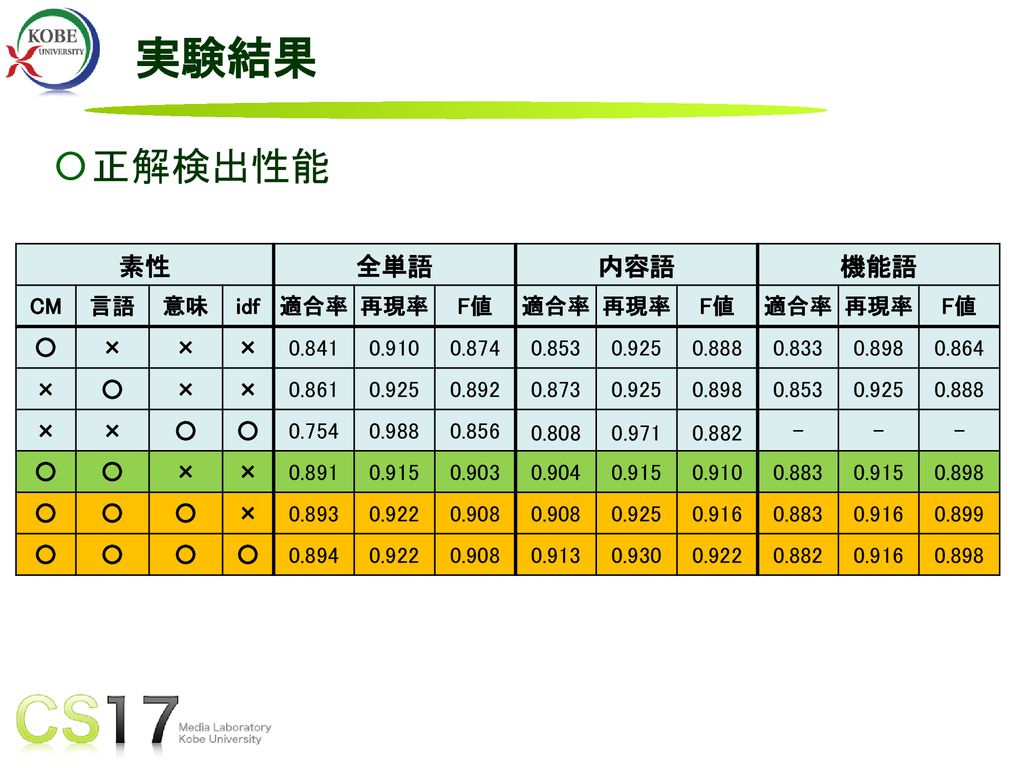
33
実験結果 正解検出性能 素性 全単語 内容語 機能語 CM 言語 意味 idf 適合率 再現率 F値 ○ × 0.841 0.910
0.874 0.853 0.925 0.888 0.833 0.898 0.864 0.861 0.892 0.873 0.754 0.988 0.856 0.808 0.971 0.882 - 0.891 0.915 0.903 0.904 0.883 0.893 0.922 0.908 0.916 0.899 0.894 0.913 0.930
34
誤り訂正へ 誤り情報を音声認識器にフィードバック⇒再認識 複数仮設へのラベリング⇒誤りの少ないパスを選択 正 正 正 正 誤 誤 誤 誤 誤

36
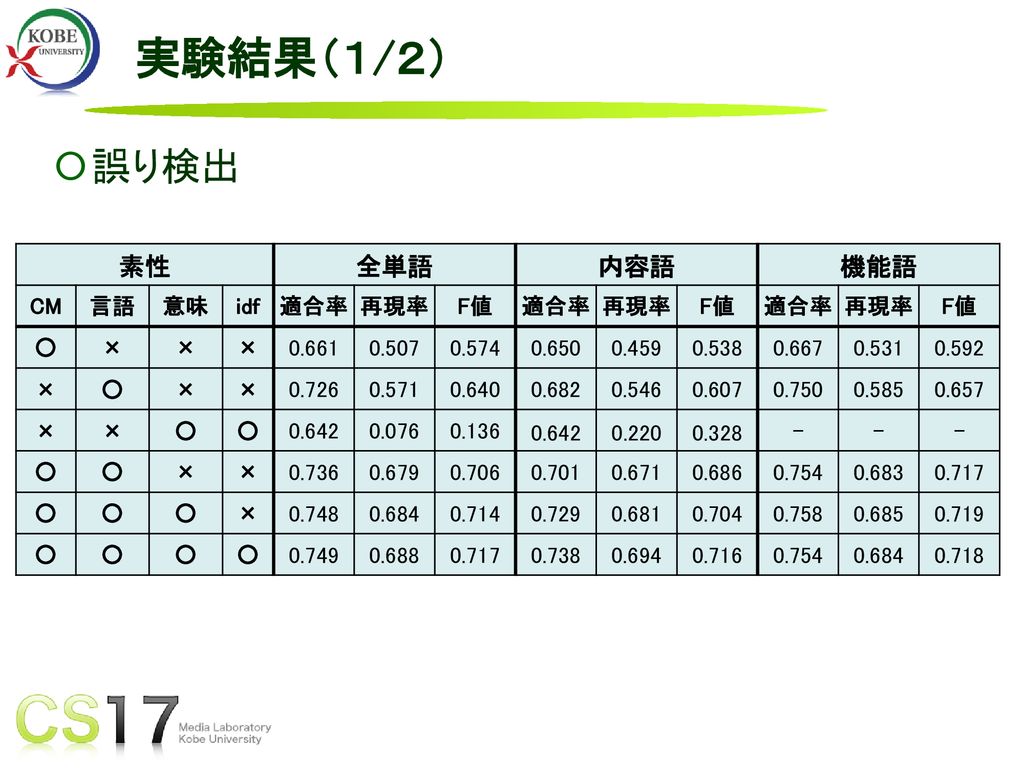
実験結果(1/2) 誤り検出 素性 全単語 内容語 機能語 CM 言語 意味 idf 適合率 再現率 F値 ○ × 0.661 0.507
0.574 0.650 0.459 0.538 0.667 0.531 0.592 0.726 0.571 0.640 0.682 0.546 0.607 0.750 0.585 0.657 0.642 0.076 0.136 0.220 0.328 - 0.736 0.679 0.706 0.701 0.671 0.686 0.754 0.683 0.717 0.748 0.684 0.714 0.729 0.681 0.704 0.758 0.685 0.719 0.749 0.688 0.738 0.694 0.716 0.718
37
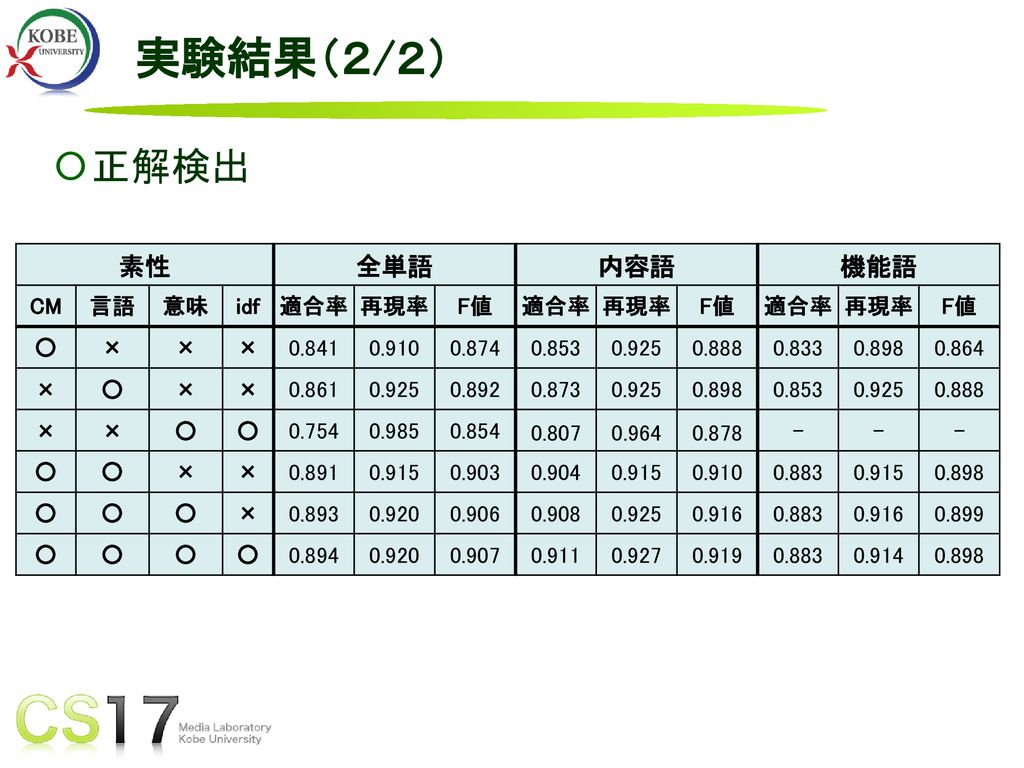
実験結果(2/2) 正解検出 素性 全単語 内容語 機能語 CM 言語 意味 idf 適合率 再現率 F値 ○ × 0.841 0.910
0.874 0.853 0.925 0.888 0.833 0.898 0.864 0.861 0.892 0.873 0.754 0.985 0.854 0.807 0.964 0.878 - 0.891 0.915 0.903 0.904 0.883 0.893 0.920 0.906 0.908 0.916 0.899 0.894 0.907 0.911 0.927 0.919 0.914










 辻 慶太(水) http://slis.sakura.ne.jp/cje3.>")











.>")