階層線形モデル(Hierarchical Linear Modeling, HLM)の概要と適用例 東京大学大学院教育学研究科 日本学術振興会 村山 航
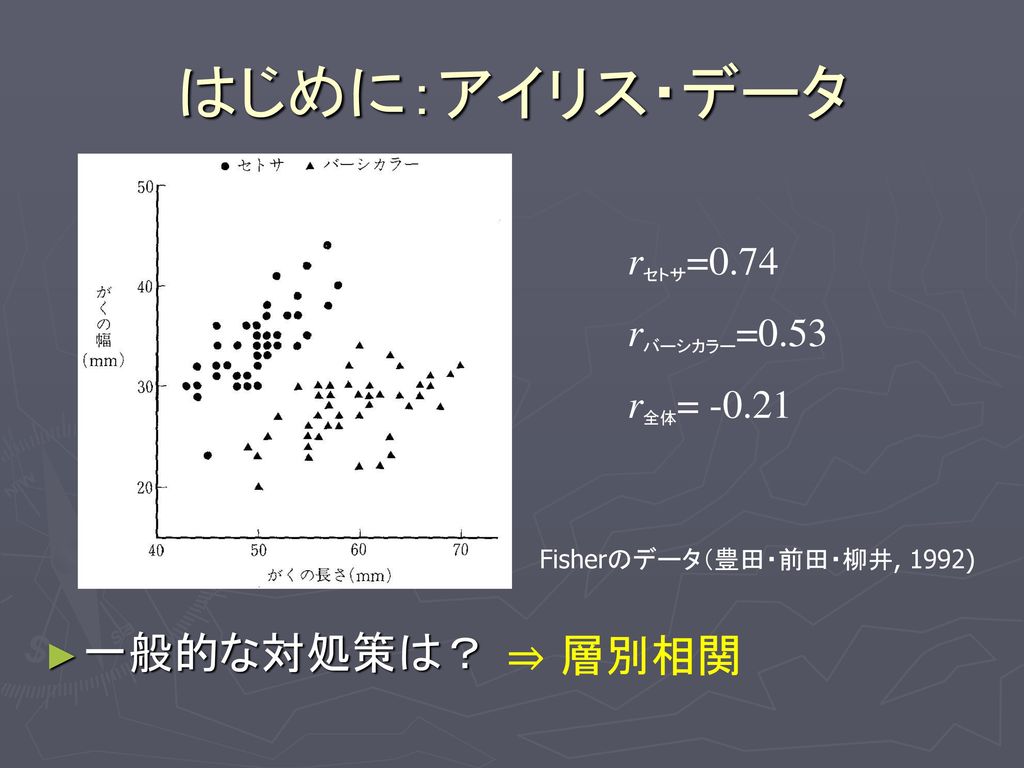
はじめに:アイリス・データ 一般的な対処策は? ⇒ 層別相関 rセトサ=0.74 rバーシカラー=0.53 r全体= -0.21 Fisherのデータ(豊田・前田・柳井, 1992) rセトサ=0.74 rバーシカラー=0.53 r全体= -0.21 一般的な対処策は? ⇒ 層別相関
よくあるデータ例:複数学校のデータ よくある分析 ⇒ 全体をプールした回帰分析 全体どころか,どの単一の学校も反映していない結果になる可能性 遂行目標 総合模試の成績 学校1 全体 学校2 学校3 よくある分析 ⇒ 全体をプールした回帰分析 全体どころか,どの単一の学校も反映していない結果になる可能性
どうすればいいのか 素朴なアイディア 各学校ごとに回帰係数を求め,切片と回帰係数の平均値や分散を求める a の平均と分散 b の平均と分散 が求められる
階層線形モデルの基本的な式 一般化して数式にすると(確率変数導入・notation変更) レベル1のモデル式 レベル2のモデル式 学校 j の i 番目の人の値 レベル1のモデル式 各学校ごとの切片と傾き 傾きの各学校特有の値 レベル2のモデル式 傾きの(学校間の)平均値 切片の学校間分散 傾きの学校間分散 上記の効果をすべて除いたときの誤差分散
結果の解釈 独立変数をSES,従属変数を成績とした上で先ほどのモデルを適用した例(Raudenbush & Bryk, 2002より改変) 解釈してみよう!
モデルの拡張 モデルは柔軟に構成可能 特に有用な拡張:切片や傾きの学校間分散を予測する変数を投入することができる レベル1は同じ 切片や傾きの学校間の違いを予測しようとする変数(例: 学校の平均クラスサイズ) ここで なら?(仮想例) このとき,予測力のあるWを投入すると学校間分散は減少する:Wによる分散説明率を算出可能 例) (前頁参照)が に変化したとき,分散説明率は
留意点1: 学校ごとの回帰分析との違い HLMによって推定される学校ごとの切片・回帰係数(Empirical Bayes)は,次の3つの要素で構造化される 学校ごとに回帰分析をして推定した切片・回帰係数(OLS) 全体(他校)の情報を使って推定した切片・回帰係数( ) 学校ごとに推定した切片・回帰係数の信頼性 一種の信頼性係数 全体の情報をもとに算出した切片・回帰係数の推定値 HLMによる学校ごとの切片・回帰係数の推定値(Empirical Bayes) 学校ごとに回帰分析をしたときの推定値(OLS)
全体平均に収縮し,分散が小さくなっている(特に信頼性の低い“傾き”が) Raudenbush & Bryk(2002)より 全体平均に収縮し,分散が小さくなっている(特に信頼性の低い“傾き”が)
留意点2: センタリングについて HLMでは独立変数をセンタリングすることが多い 切片に意味を持たせるため:通常の回帰分析にも当該 場合によっては多重共線性の回避にも寄与(Cronbach, 1987) 2種類のセンタリング方法が存在:切片( )に影響 Grand Mean Centering 全学校の平均値を用いて独立変数をセンタリング Group Mean Centering 各学校ごとに,その学校の平均値を用いてセンタリング
Grand Mean Centering: は独立変数が全学校の平均値のときの, の期待値.一種の調整平均. Group Mean Centering: は独立変数が各学校の平均値のときの, の期待値.各学校での の期待値. 学校1 学校2 学校1の 学校2の 学校1の 学校2の 全体 平均 学校1 平均 学校2 平均 Group Mean Centering Grand Mean Centering 共分散分析のように独立変数を調整した平均値差に興味があるとき以外は,Group Mean Centeringが無難 共分散分析のように独立変数を調整した群間の平均値差に 興味があるとき以外は,Group Mean Centeringが無難
HLMを適用した論文を読んでみる ※ 従属変数は援助要請行動の回避(avoidance of help-seeking) Ryan, Gheen, & Midgley (1998). Journal of Educational Psychology
HLMを自分で実行してみる HLM(Bryk, Raudenbush & Congton, 1996; 現在はver6まで) 長所:モデルの組み立て・センタリングが簡単で初心者向け.アドバンスドなモデルも扱える. 短所:データの変換ができない.HLMに特化しているので他の分析への移行ができない. SAS(proc mixedプロシジャを用いて分析) 長所:SASによるデータ加工・他分析とあわせて使える.SASユーザにとってはかなり使いやすい. 短所:もともとHLMに特化したプロシジャではないため,アドバンスドなモデルは扱えないのも多い.モデルの式をプログラムするときも,やや慣れがいる.
HLMの使い方(概要) データの準備 1レベル1ファイル:どのレベルもカラム指定になる 最初のカラムは必ずID(必ず昇順で入力)
HLMの使い方(概要) SSMファイル(十分統計量のファイル)の作成 あとのモデル作成は比較的簡単にできる File→SSM→New→ASCII input レベルごとにData Formatや変数の数などを入力 Data Formatの入力が少しややこしい:Fortran形式. (A3, 4X, 5F6.1)など “Make SSM”でファイルを作成.“Check Stats”で基本統計量を確認し,読み込みミスがないかを確認. あとのモデル作成は比較的簡単にできる IDが3桁 スペースが4桁 6桁(うち1桁が小数点以下)の変数が5回繰り返される(スペース・小数点も1桁に数えられる)
←SSMファイルの作成 モデルの作成→
SASによるHLMプロシジャ(概要) 詳しくはSinger(1998)を参照のこと データファイル http://gseweb.harvard.edu/~faculty/singer/ に論文あり データファイル レベル1のオブザベーションごとに打ち込む.レベル2の変数もここに組み込まれる. school size motive score sex … 232 16 3 11 1 … 232 16 4 16 1 … 232 16 4 13 2 … … 193 38 1 13 1 … 193 38 5 20 1 … 193 38 4 18 2 … 193 38 4 17 2 … 313 26 3 16 1 … …
SASによるHLMプロシジャ(概要) 事前準備:分析する2レベルのモデルを結合しておく 例 固定効果と変量効果に分けて結合 固定効果
SASによるHLMプロシジャ(概要) proc mixedプロシジャを用いて表現 以下大文字はデータセットにおける変数名 固定効果 変量効果 固定効果の独立変数を指定.ただし切片(γ00は指定しなくてよい) proc mixed noclprint covtest noitprint; class SCHOOL; model SCORE = MOTIVE/solution ddfm=bw notest; random intercept MOTIVE/sub=SCHOOL type=un; レベル2の単位となる変数を指定 変量効果の独立変数を指定.切片(u0j)は“intercept”と記す.rijは指定しなくてよい.
参考文献など ・Raudenbush, S. W. & Bryk, A. S. (2002). Hierarchical linear models: Applications and data analysis methods (2nd ed.). Newbury Park, CA: Sage. ・Singer, J. D. (1998). Using SAS PROC MIXED to fit multivariate models, hierarchical models, and individual growth models. Journal of Educational and Behavioral Statistics, 24, 323-355. ・2003年度夏学期南風原朝和先生の授業 ・2000・2003年度杉澤武俊さんのレジュメ(HLM・SASによる分析の方法について) ・村山航 (2005). 主体的・内発的な意欲は必ず望ましい結果をもたらすのか 東京大学大学院教育学研究科比較教育社会学コース(編) 「首都圏の私立中学生の生活・意識・行動に関する調査」研究報告書, pp78-88. ・Ryan, A. M., Gheen, M. H., & Midgley, C. (1998). Why do some students avoid asking for help? An examination of the interplay among students’ academic efficacy, teachers’ social-emotional role, and the classroom goal structure. Journal of Educational Psychology, 90, 528-535.
ご清聴ありがとうございました 分かりにくかったと思いますので,何かご質問などありましたら,murakou@orion.ocn.ne.jp まで連絡をお願いします.