データ構造と アルゴリズム 第十一回 理工学部 情報システム工学科 新田直也
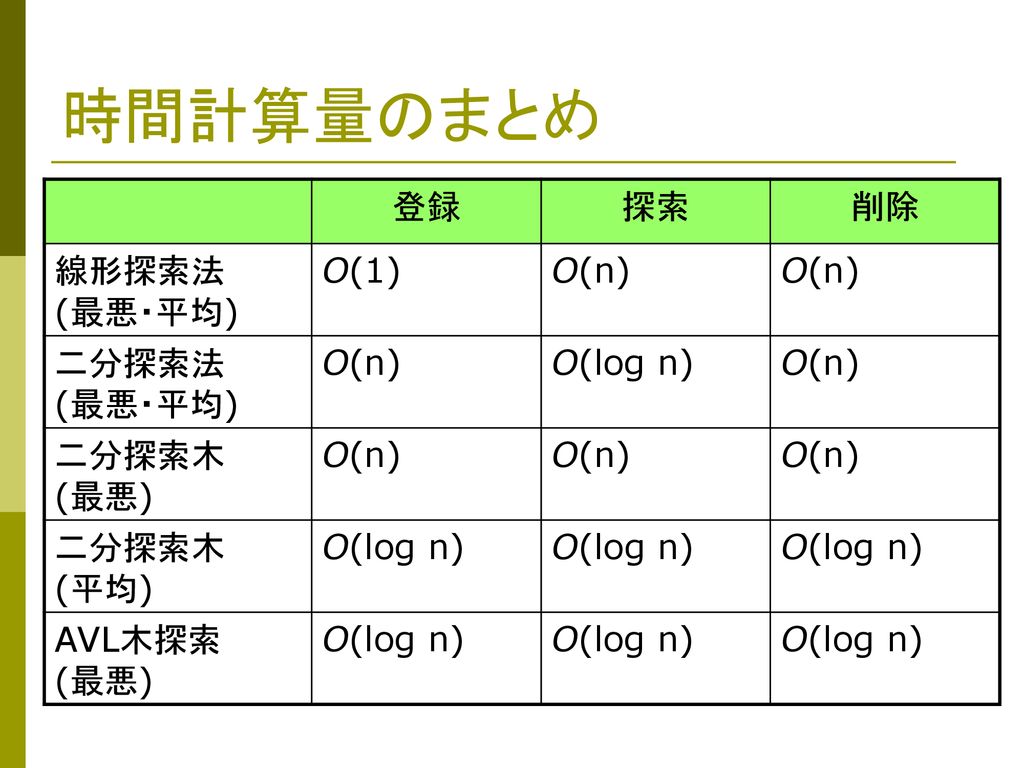
時間計算量のまとめ 登録 探索 削除 線形探索法 (最悪・平均) O(1) O(n) 二分探索法 (最悪・平均) O(log n) 二分探索木 (最悪) 二分探索木 (平均) AVL木探索 (最悪) 時間計算量のまとめ
探索 探索: 表からデータを探し出す. Key Data 1 90 5 50 6 80 8 95 10 35
ハッシュ法の考え方(1) Key値の取りうる範囲が,予めわかっている場合. Key Data 1 90 5 50 6 80 8 95 10 2 なし 3 4 5 50 6 80 7 8 95 9 10 35 Key Data 1 90 5 50 6 80 8 95 10 35 配列など →O(1)で探索できる.
ハッシュ法の考え方(2) 前頁のようなデータ構造の問題点 Key値のとりうる範囲が広いと,データサイズは膨大に. メモリ領域に収まるよう圧縮しよう.(ハッシュ関数) a ab aa : 100種類の値 1208925819614629174706176種類の値
ハッシュ関数の例 すべての文字コードを加算し,100で割った余りを求める. int hash(char s[]) { int i = 0; 文字列 ハッシュ値 one 22 two 46 three 36 four 44 five 26 six 40 seven 45 eight 29 nine ten 27 int hash(char s[]) { int i = 0; int n; for (n = 0; s[n] != 0; n++) { i = i + s[n]; } return i % 100;
ハッシュ関数を用いた登録,探索 ハッシュ値の取りうる範囲と 同じサイズの配列を用意. (前頁の例では,100個) Key のハッシュ値を求める. (”two”の場合,46) ハッシュ値が指す配列要素 にデータを登録する. (46番目の要素に登録) 文字列 ハッシュ値 one 22 two 46 three 36 four 44 five 26 six 40 seven 45 eight 29 nine ten 27
ハッシュ値の衝突 ハッシュ値の取りうる範囲と 同じサイズの配列を用意. (前頁の例では,100個) Key のハッシュ値を求める. (”two”の場合,46) ハッシュ値が指す配列要素 にデータを登録する. (46番目の要素に登録) 文字列 ハッシュ値 one 22 two 46 three 36 four 44 five 26 six 40 seven 45 eight 29 nine ten 27 → ”five” と ”nine” のデータが ぶつかる.(衝突)
チェイン法(1) ハッシュ値が衝突すると,データが上書きされる. →同じ場所にデータを任意個記憶できるようにすればよい. key ハッシュ値 ハッシュ値が衝突すると,データが上書きされる. →同じ場所にデータを任意個記憶できるようにすればよい. key ハッシュ値 Data なし 1 : 26 92? 17? 204? 39? 99 “five” 92 17 “nine” 204 “zh” 39 “yi”
チェイン法(2) 同じハッシュ値を持つデータを連結リストでつなぐ. key ハッシュ表 ハッシュ値 Data NULL 1 : 26 99 NULL 1 : 26 99 “five” 92 17 “nine” … “five” 92 “nine” 17 204 “zh” 39 “yi” バケット
チェイン法(3) チェイン法のデータ構造. #define BUCKET_SIZE 100 struct CELL { int key; int data; strucr CELL *next; }; struct CELL *table[BUCKET_SIZE];
チェイン法の計算量 データ数をN,バケット数をBとする. 平均時間計算量について 平均時間計算量: O(1 + N/B)
オープンアドレス法 ハッシュして同じ場所を指した場合,別の場所を探す. 別の場所を探す手続きを再ハッシュと呼ぶ. 再ハッシュは繰り返し実行できる. key ハッシュ値 Data 1 : 26 53 99 “five” 204 “nine” 92 “zh” 17
オープンアドレス法の登録 オープンアドレス法の登録手続き: x: キー, hk(x): 再ハッシュをk回繰り返して得られる値 k := 0 k = B ならエラー終了,そうでなければ 2. へ hk(x)番目のバケットにデータを書き込む
再ハッシュの例 最も単純な例: 適当なハッシュ関数 h に対して hk(x) = (h(x) + k) mod B とする. これは連続するバケットを順に調べていくことに対応.
オープンアドレス法の削除(1) 単純に削除を行うと問題が発生. key ハッシュ表 ハッシュ値 Data 1 : 26 92 27 17 1 : 26 92 27 17 28 204 29 39 99 “five” 92 17 “nine” 204 “zh” “nine”のデータを 「空き」にすると, 続きが探索できな くなる. 39 “yi” 孤立してしまう!!
オープンアドレス法の削除(2) 「削除済」という特別な値を用意し,続きがあることを示す. key ハッシュ表 ハッシュ値 Data 1 : 1 : 26 92 27 削除済 28 204 29 39 99 “five” 92 17 “nine” 204 “zh” “nine”のデータを 「削除済」に設定 する. 39 “yi”
良い再ハッシュ法(1) 先に示した単純な再ハッシュ法は次のような問題を持つ. ハッシュ値 Data : 26 27 28 29 30 99 : 26 27 28 29 30 99 ハッシュ値26を持つ データの系列 ハッシュ値28を持つ データの系列 一度重なると その後ずっと 重なってしまう
良い再ハッシュ法(2) 単純な再ハッシュ法では,以下の関係が成り立ってしまう. hk1(x1) = hk2(x2) ⇒ hk1+1(x1) = hk2+1(x2) hk(x) = (h(x) + k) mod B ランダム置換(並べ替え) k nk hk(x) = (h(x) + nk) mod B
オープンアドレス法の計算量 α = 登録バケット数 / 全バケット数 探索の平均時間計算量 連続領域で再ハッシュ: 成功: O((1-α/2)/(1-α)) 失敗: O(1/2+1/(2(1-α)2)) ランダムに再ハッシュ: 成功: O(1/α・loge(1/(1-α))) 失敗: O(1/(1-α))