Download presentation
1
もう少し高い位置から 統計応用のひとつの風景

2
Advanced Data Mining 高度データマイニング 東京工科大学大学院 バイオニクス・情報メディア学専 攻科

3
Data Mining とは

4
大量のデータから 規則性を発見するための データ解析処理のこと。

5
Data Mining とは 大量のデータから => 少なくとも 1,000 個 規則性を発見するための データ解析処理のこと。

6
Data Mining とは 大量のデータから => 少なくとも 1,000 個 規則性を発見するための => どんな ? データ解析処理のこと。 => どうやっ て?

7
大量のデータ (1) Digital library Image archive Bioinformatics Medical imagery Health care Finance and investment Manufacturing and production
 Digital library Image archive Bioinformatics Medical imagery Health care Finance and investment Manufacturing and production")
8
大量のデータ (2) Business and marketing Telecommunication network Scientific domain The World Wide Web (WWW) Biometrics etc.
 Business and marketing Telecommunication network Scientific domain The World Wide Web (WWW) Biometrics etc.")
9
具体例 もう少しイメージを持ってもらうために、 テキストデータ関連の実例を見てみよう。 – 方丈記 – 徒然草 – 広辞苑 –Bacon エッセイ集 (Gutenberg Project) –BNC (British National Corpus) => Data Warehouse
 –BNC (British National Corpus) => Data Warehouse")
10
規則性 雨が降れば桶屋が儲かる。 アメリカがくしゃみをすれば、 日本は風邪をひく。 世帯主の年齢が 30 歳~35歳ならば、 マンションを購入する。 自動車が写っている写真の 80 %には、 青空も写っている。 文は主語と述語とからなる。 etc.

11
解析法 従来の統計解析手法との共通点が多い。 (探索的データ解析, Exploratory Data Analysis; EDA ) 現在、多様な手法が提案されている。 =>本講義で紹介する。
 現在、多様な手法が提案されている。 =>本講義で紹介する。")
12
DM に関連する諸手法 マルチメディアデータ圧縮 (Multimedia Data Compression) 文字列照合 (string Matching) 分類手法 (Classification) クラスタリング (Clustering) 統計的手法(予測・検定 etc. )
.")
13
統計的手法 基本統計量(平均・分散・標準偏差・中 央値・最頻値・最大値・最小値 etc. ) 度数分布表 ヒストグラム 散布図、相関図 etc. (統計の基本的知識は不可欠!)
 度数分布表 ヒストグラム 散布図、相関図 etc. (統計の基本的知識は不可欠!)")
14
統計基礎復習 データ解析の演習 1. 度数分布表の作成 2. ヒストグラムの作成 3. グラフの分析 (データの)代表値 (データの)散らばり
代表値 (データの)散らばり")
15
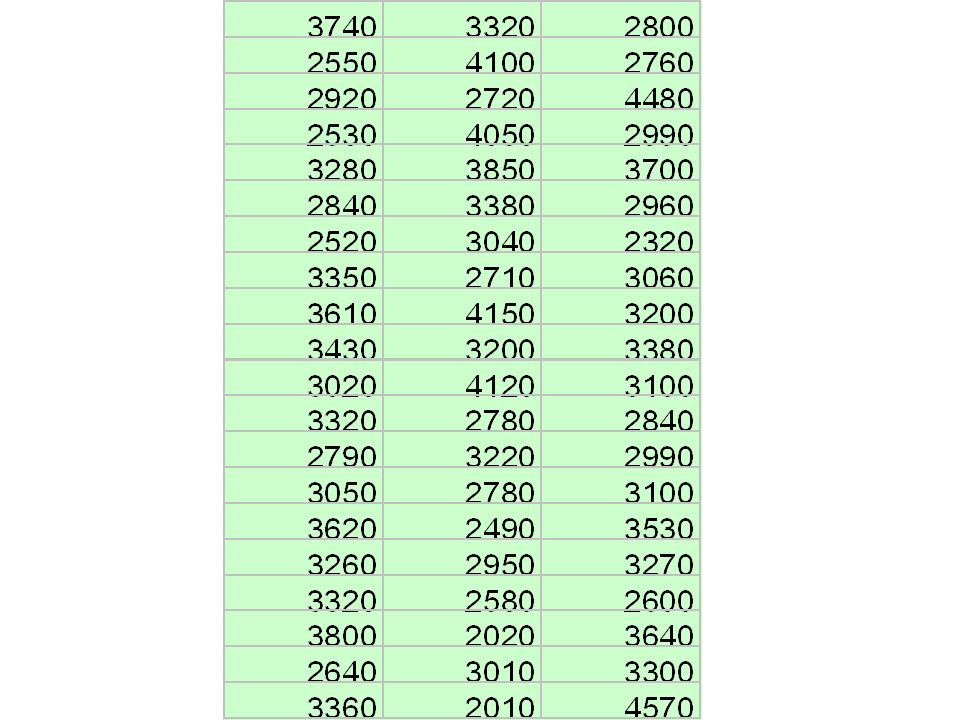
新生児60人の体重(199 8) 単位はグラム 表. 新生児の体重 (1998 年 )
 単位はグラム 表. 新生児の体重 (1998 年 )")
16
手順1: EXCEL の起動 [ スタート ]-[ すべてのプログラム ]- [Microsoft Excel] 手順2:データの入力
![手順1: EXCEL の起動 [ スタート ]-[ すべてのプログラム ]- [Microsoft Excel] 手順2:データの入力](http://images.slidesplayer.net/39/11033497/slides/slide_16.jpg "手順1: EXCEL の起動 [ スタート ]-[ すべてのプログラム ]- [Microsoft Excel] 手順2:データの入力")
18
手順1: EXCEL の起動 [ スタート ]-[ すべてのプログラム ]- [Microsoft Excel] 手順2: データの入力 手順3: 度数分布表の作成
![手順1: EXCEL の起動 [ スタート ]-[ すべてのプログラム ]- [Microsoft Excel] 手順2: データの入力 手順3: 度数分布表の作成](http://images.slidesplayer.net/39/11033497/slides/slide_18.jpg "手順1: EXCEL の起動 [ スタート ]-[ すべてのプログラム ]- [Microsoft Excel] 手順2: データの入力 手順3: 度数分布表の作成")
19
度数分布表の作成

20
度数分布表とは データをいくつかのグループに分類し、 各グループに属するデータ数を添えた表。

21
度数分布表とは イメージとしては右 図のようなもの。 キャプション・ 表頭・表側・ 区間(階級)・ 区間幅(階級幅) 区 間度 数 0-9 9 20 100-1 99 50 200-2 99 120 300-3 99 65 表.度数分布表の 例
・ 区間幅(階級幅) 区 間度 数 0-9 9 20 100-1 99 50 200-2 99 120 300-3 99 65 表.度数分布表の 例")
22
度数分布表の作成 1. 最大値と最小値を求める。 2. 最大値と最小値の差 R (範囲)を求める。 3. 区間の個数(棒グラフの棒の本数) k を決める。 k=√n k=1 + 3.32 log 10 (n) 簡単に、 k=7 ~ 10 ぐらいにする。 4. 区間幅 h を求める。 1.h=R÷k 2.h の値を見て、きりのいい数字に設定する。
 k を決める。 k=√n k= log 10 (n) 簡単に、 k=7 ~ 10 ぐらいにする。 4. 区間幅 h を求める。 1.h=R÷k 2.h の値を見て、きりのいい数字に設定する。.")
23
度数分布表の作成 1. 最大値 =____ , 最小値 =___ 2. 範囲 R= 最大値-最小値 3. 区間数 k=____ 4. 区間幅 h=____ 5. 最小値と最大値とを勘案して、区間の両 端を決める。

24
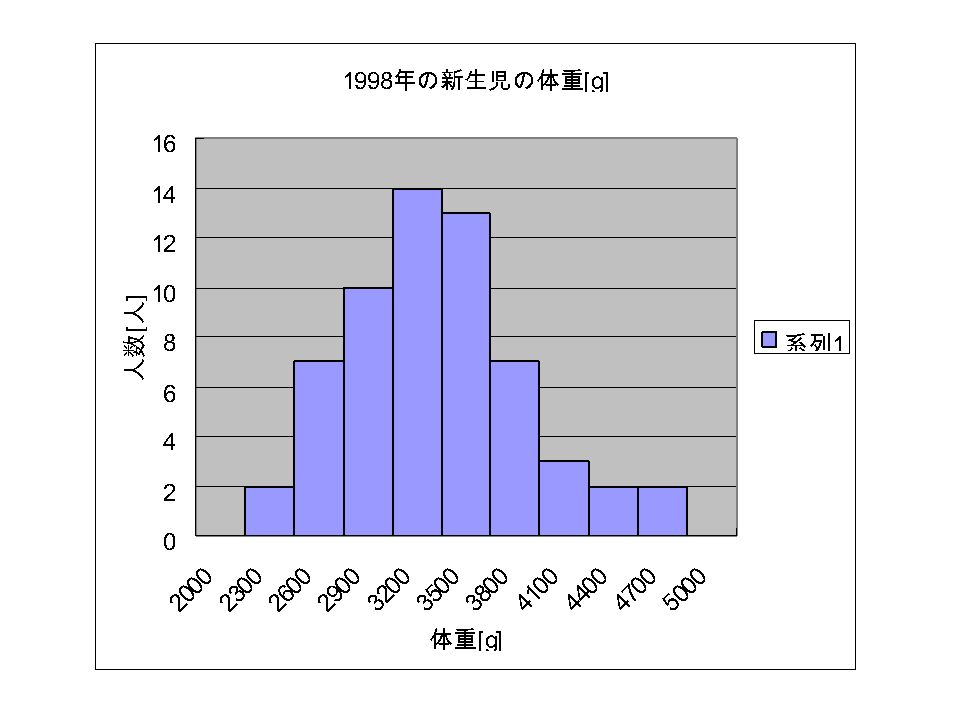
体重 (g) 人数 ~ 2000 0 2000 ~ 2400 3 2400 ~ 2800 14 2800 ~ 3200 16 3200 ~ 3600 14 3600 ~ 4000 7 4000 ~ 4400 4 4400 ~ 4800 2 新生児の体重(
 人数 ~ ~ ~ ~ ~ ~ ~ ~ 新生児の体重(")
26
今日の話 例題

27
例題1:ある高校での学生 20 名の成績。 65 41 55 38 42 39 46 40 49 49 93 63 55 46 57 64 57 47 62 55

28
データのクリーニングと外れ値 外れ値:異常に飛び離れた値 クリーニング:外れ値に対応すること

29
外れ値の判断基準 平均値 ± 3 × 標準偏差 から外れている

30
平均 平均 (mean) とは、「データの中心」、ある いは、「データの代表値」を表す。 数学的定義: – データ: – 定義:
 とは、「データの中心」、ある いは、「データの代表値」を表す。 数学的定義: – データ: – 定義:")
31
データの散らばり 平均が同じでも、データの様子が異なる ことがある。 例: – データ1: {-0.2, 0, 0.2} – データ 2 : {-20, 0,20} ( どちらも平均 m=0 だけど、データの散らばり は 違う。このことをどのように表現したらい いのだ ろうか? )
")
32
データの散らばりの尺度(1) (Idea 1) データの散らばりは、平均を基準として 測る。 (妥当性) 次の関数の最小値は、平均m。
 (Idea 1) データの散らばりは、平均を基準として 測る。 (妥当性) 次の関数の最小値は、平均m。")
33
データの散らばりの尺度(2) (Idea 2) データの散らばりを以下の式で表現する。 この式は常にゼロになってしまうので意味がな い!
 (Idea 2) データの散らばりを以下の式で表現する。 この式は常にゼロになってしまうので意味がな い!")
34
データの散らばりの尺度(3) (Idea 3 ) データの散らばりを以下の式で表現する。 この式には、絶対値が含まれており、解析学的に (美積分学的に)取り扱いにくい。アイデアはい いけれど、数学的にはチョットねぇ。
 (Idea 3 ) データの散らばりを以下の式で表現する。 この式には、絶対値が含まれており、解析学的に (美積分学的に)取り扱いにくい。アイデアはい いけれど、数学的にはチョットねぇ。")
35
データの散らばりの尺度(4) (Idea 4 ) データの散らばりを以下の式で表現する。 これを分散 (variance) といい、データの散らばり の程度を表現している。元のデータとの次元 (dimension) をそろえるためにルートを取ったもの が標準偏差である。
 (Idea 4 ) データの散らばりを以下の式で表現する。 これを分散 (variance) といい、データの散らばり の程度を表現している。元のデータとの次元 (dimension) をそろえるためにルートを取ったもの が標準偏差である。")
36
データの散らばりの尺度(5) (Idea 5 ) データの散らばりを以下の式で表現する。 これを標準偏差 (standard deviation) と呼ぶ。
 (Idea 5 ) データの散らばりを以下の式で表現する。 これを標準偏差 (standard deviation) と呼ぶ。")
37
(注意!) 分散・標準偏差の定義式には、分母が n のものと (n-1) のものとがある。 この辺りは、後日改めて説明する。
 分散・標準偏差の定義式には、分母が n のものと (n-1) のものとがある。 この辺りは、後日改めて説明する。")
38
例題1についての解析 例題1のデータの平均と標準偏差をもと めると、 93 が外れ値(異常値)であるこ とが分かる。 (各自確認してみること)
であるこ とが分かる。 (各自確認してみること)")
39
例題2:(練習問題として各自分析せ よ。) 52 75 49 82 87 49 93 69 38 55 41 62 57 71 67 82 78 43 65 60
")
40
範囲・中央値・最頻値 範囲( range, レンジ) = 最大値ー最小値 中央値:データを大きさの順番に並べて とき、真ん中に来るデータ値。データが 偶数のときは、真ん中に来る2つのデー タの平均を中央値とする。 最頻値:最も出現回数の多いデータ。
 = 最大値ー最小値 中央値:データを大きさの順番に並べて とき、真ん中に来るデータ値。データが 偶数のときは、真ん中に来る2つのデー タの平均を中央値とする。 最頻値:最も出現回数の多いデータ。")
41
例: データ: {2,5,-4,-2,3,1,1,-6} – 平均 m=(2+5-4-2+3+1+1-6) / 8 = 0 – 最大値 max=5 – 最小値 min=-6 – 範囲 r=max-min=11 – 中央値( Median ) Med=1 なぜなら、 {-6,-4,-2, 1, 1,2,5} 最頻値(モード,mode)mode=1
 / 8 = 0 – 最大値 max=5 – 最小値 min=-6 – 範囲 r=max-min=11 – 中央値( Median ) Med=1 なぜなら、 {-6,-4,-2, 1, 1,2,5} 最頻値(モード,mode)mode=1")
42
ここまでは復習 Let’s go farther!

43
Advanced Data Mining 高度データマイニング( 3 ) 東京工科大学大学院 バイオニクス・情報メディア学専 攻科
 東京工科大学大学院 バイオニクス・情報メディア学専 攻科")
44
階級度数 0-92 10-190 20-292 30-391 40-491 50-591 1 2 25 41 20 32 57 38 データ群 度数分布表 Histogram

45
データ群 データ全体としての性質を数値化すると – 平均(データの代表値, mean ) – 分散(データの散らばり, variance ) – 標準偏差(データの散らばり, standard deviation ) – 中央値(データの代表値, median ) – 最頻値(データの代表値, mode ) – 最大値&最小値 – 範囲(データの散らばり, range ) etc.
 – 分散(データの散らばり, variance ) – 標準偏差(データの散らばり, standard deviation ) – 中央値(データの代表値, median ) – 最頻値(データの代表値, mode ) – 最大値&最小値 – 範囲(データの散らばり, range ) etc.")
46
データ群 データ全体としての性質を数値化すると – 平均(データの代表値, mean ) – 分散(データの散らばり, variance ) – 標準偏差(データの散らばり, standard deviation ) – 中央値(データの代表値, median ) – 最頻値(データの代表値, mode ) – 最大値&最小値 – 範囲(データの散らばり, range ) etc.
 – 分散(データの散らばり, variance ) – 標準偏差(データの散らばり, standard deviation ) – 中央値(データの代表値, median ) – 最頻値(データの代表値, mode ) – 最大値&最小値 – 範囲(データの散らばり, range ) etc.")
47
これらの改良版 幹葉表示 (stem-leaf-and-forget-display) – 度数分布表 5数表示 (five number display) – 基本統計量 箱ヒゲ図 – 基本統計量の図示
 – 度数分布表 5数表示 (five number display) – 基本統計量 箱ヒゲ図 – 基本統計量の図示")
48
4 2 0 3 1 0 2 3 0 3 2 0 4 3 0 3 1 0 幹葉表示 427 313 232 323 434 317 311 4 2 7 3 1 3 2 3 2 3 2 3 4 3 4 3 1 7 3 1 1 基本的考え方 幹 (stem) Most Significant Digit 葉 (leaf ) 端数 (forget)
 Most Significant Digit 葉 (leaf ) 端数 (forget)")
49
幹葉表示(例)
")
50
5数表示

51
箱ヒゲ図

52
Advanced Data Mining 高度データマイニング 東京工科大学大学院 バイオニクス・情報メディア学専 攻科 Version 2

53
DM Methodoogy

54
DM Methodology 1.Exploratory data analysis (探索的データ解析) 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)
 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)")
55
DM Methodology 1.Exploratory data analysis (探索的データ解析) 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)
 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)")
56
1. Exploratory data analysis a. 統計的データ解析 (SDA) b. 探索的データ解析 (EDA)
 b. 探索的データ解析 (EDA)")
57
統計的データ解析 (SDA の基礎 ) 1. 視覚的分析 表:度数分布表 (frequency table) 図:ヒストグラム (histogram) 2. 数値的分析 代表値:平均 (mean) 中央値 (median) モード (mode, 最頻値) ばらつき度:分散 (variance) 平均偏差 (mean deviation; MD) 標準偏差 (standard deviation) 範囲 (range = 最大値ー最小値 ) その他四分位数 (quartile, 第一・二・三) 外れ値
 中央値 (median) モード (mode, 最頻値) ばらつき度:分散 (variance) 平均偏差 (mean deviation; MD) 標準偏差 (standard deviation) 範囲 (range = 最大値ー最小値 ) その他四分位数 (quartile, 第一・二・三) 外れ値.")
58
統計的データ解析 (SDA の基礎 ) 1. 視覚的分析 表:度数分布表 (frequency table) 図:ヒストグラム (histogram) 2. 数値的分析 代表値:平均 (mean) 中央値 (median) モード (mode, 最頻値) ばらつき度:分散 (variance) 平均偏差 (mean deviation; MD) 標準偏差 (standard deviation) 範囲 (range = 最大値ー最小値 ) その他四分位数 (quartile, 第一・二・三) 外れ値
 中央値 (median) モード (mode, 最頻値) ばらつき度:分散 (variance) 平均偏差 (mean deviation; MD) 標準偏差 (standard deviation) 範囲 (range = 最大値ー最小値 ) その他四分位数 (quartile, 第一・二・三) 外れ値.")
59
1. 幹葉表示 (stem-and-leaf display) 2. 要約値 (letter value display) 3. 箱ヒゲ図 (box-whisker plots) 4. X-Y表示 (X-Y plotting) 5. 抵抗性のある直線回帰 (registant line) 6. 中央値分散分析 (median polish) 7. 時系列データのならし (smoothing) 探索的データ解析 (EDA)
 4. X-Y表示 (X-Y plotting) 5. 抵抗性のある直線回帰 (registant line) 6. 中央値分散分析 (median polish) 7. 時系列データのならし (smoothing) 探索的データ解析 (EDA).")
60
1. 幹葉表示 (stem-and-leaf display) ヒストグラムに代わる手法 2. 要約値 (letter value display) 平均値・標準偏差に代わるもの 3. 箱ヒゲ図 (box-whisker plots) 分布の形と外れ値の図的表示
 分布の形と外れ値の図的表示.")
61
DM Methodology 1.Exploratory data analysis (探索的データ解析) 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)
 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)")
62
3. Statistical data mining a.Statistic models (統計モデル) b.Statistic inference (統計的推論) c.Non-parametric model d.General linear model e.Log-linear model f.Graphical model etc.
 b.Statistic inference (統計的推論) c.Non-parametric model d.General linear model e.Log-linear model f.Graphical model etc.")
63
DM Methodology 1.Exploratory data analysis (探索的データ解析) 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)
 2.Computational data mining (計算論的データマイニング) 3.Statistical data mining (統計的データマイニング)")
64
2. Computational data mining 1.Cluster analysis (クラスター分析) 2.Tree models (木モデル) 3.Linear regression (線形回帰) 4.Logistic regression (ロジスティック回帰) 5.Neural networks (ニューラルネットワーク) 6.ILP(Inductive Logic Programming; 帰納論理プログラミング) 7.SVM(support vector machines) etc.
 2.Tree models (木モデル) 3.Linear regression (線形回帰) 4.Logistic regression (ロジスティック回帰) 5.Neural networks (ニューラルネットワーク) 6.ILP(Inductive Logic Programming; 帰納論理プログラミング) 7.SVM(support vector machines) etc.")
65
a.Tree models (木モデル) b.Cluster analysis (クラスター分析) c.Linear regression (線形回帰) d.Logistic regression (ロジスティック回 帰) e.Neural networks (ニューラルネットワー ク) f.ILP(Inductive Logic Programming; 帰納論理プログラミング) etc. 2. Computational data mining


、データの関係 統計的方法を用いることにより、統計量から母数について どれほどのことが言えるか、知ることができる。 2.>")


 n が母集団サイズに等しい時 … 全標本 または 全数調査 (census) 母集団 (population) 知りたい全体 標本 (sample) 入手した情報.>")
 2000 年 6 月 29 日、 7 月 6 ・ 13 日 奥西 好夫>")
 経済データ解析 2009 年度後 期. あるクラスのテストの点数が次のように なっていたとする。 このように出席番号と点数が並んでいるものだけでは、 このクラスの特徴がわかりづらい。 → このクラスの特徴がわかるような工夫が必要 → このクラスの特徴がわかるような工夫が必要.>")
 平成 27 年前期第1クウォータ科目 東京工科大学大学院 バイオニクス・情報メディア学専攻科 担当:亀田弘之.>")
 母集団の分散(母分散) 母集団中のある値の比率(母比率) p Sample 標本平均 標本分散(不偏分散) 標本中の比率.>")



で品種の特徴を表したい.>")
 担当:鈴木智也. 2 前回のポイント 「記述統計」と「推測統計」。 データ自体の規則性を記述するのが 「記述統計」、データを生み出した背 景を推測するのが「推測統計」である。 推測統計は記述統計に基づくので、ま ずは記述統計から学ぶ。 以下、データの観測値をX.>")

 2 項分布、ポアソン分布、ガウス分布 ( 1H ) 最小二乗法( 1H )>")

 東京工科大学 亀田弘之. 復習.>")


