Download presentation
1
第4章 回帰分析の諸問題(1) ー 計量経済学 ー
 ー 計量経済学 ー")
2
第1節 多重共線性 第2節 系列相関 第3節 不均一分散 1 多重共線性 1 系列相関 2 系列相関の判定 -ダービン・ワトソン比-
第1節 多重共線性 1 多重共線性 第2節 系列相関 1 系列相関 2 系列相関の判定 -ダービン・ワトソン比- 5 系列相関への対処法(2) -コクラン・オーカット法- 4 系列相関への対処法(1) -一般化最小2乗法- 3 ダービンのh統計量 第3節 不均一分散 1 不均一分散 2 不均一分散の判定 3 不均一分散の解決法(1) 4 不均一分散の解決法(2) -加重最小2乗法-
 -コクラン・オーカット法- 4 系列相関への対処法(1) -一般化最小2乗法- 3 ダービンのh統計量. 第3節 不均一分散. 1 不均一分散. 2 不均一分散の判定. 3 不均一分散の解決法(1) 4 不均一分散の解決法(2) -加重最小2乗法-")
3
前章までの回帰分析では、パラメータ推定値を求める際に、最小2乗法を用いてきた。しかし、この章で示す
(1) 多重共線性 (2) 系列相関 (3) 不均一分散 といった状況が起こっているときには、最小2乗法によるパラメータ推定値は信頼できない。 そこで、これらの状況が起こっている、[原因][症状][判定法][対処法]について示す。
 多重共線性. (2) 系列相関. (3) 不均一分散. といった状況が起こっているときには、最小2乗法によるパラメータ推定値は信頼できない。 そこで、これらの状況が起こっている、[原因][症状][判定法][対処法]について示す。")
4
たとえば風邪を引いた場合を例に考えてみよう
[原因] 寒い中薄着で人混みに出かけた [症状] 発熱、せき、くしゃみ、鼻水 [判定法] のどを見ると赤くはれている。 体温を測ると、38度ある。 [対処法] ゆっくり休む。(根治療法) ウイルスを殺す薬を飲む(対処療法) 熱を下げる薬を飲む(対処療法)
 ウイルスを殺す薬を飲む(対処療法) 熱を下げる薬を飲む(対処療法)")
5
第1節 多重共線性 1 多重共線性 多重共線性とは、重回帰分析において、説明変数間に強い相関が見られることである。 多重共線性あり Y W
第1節 多重共線性 多重共線性あり 1 多重共線性 多重共線性とは、重回帰分析において、説明変数間に強い相関が見られることである。 Y W 多重共線性なし × × × × 回帰平面 Y=a+bX+cW X

6
[原因] [症状] モデルの中に強い相関関係をもつ複数の説明変数を入れてしまった。 推定値の符号が理論に一致しない。
決定係数R2は大きいのに、個々のt値が小さい。 データの値を少し変えたり、少し追加・削除すると、係数推定値が大きく変化する。 説明変数を増減すると、推定値が大きく変化する。
![[原因] [症状] モデルの中に強い相関関係をもつ複数の説明変数を入れてしまった。 推定値の符号が理論に一致しない。](http://slidesplayer.net/slide/11278008/61/images/6/%EF%BC%BB%E5%8E%9F%E5%9B%A0%EF%BC%BD+%EF%BC%BB%E7%97%87%E7%8A%B6%EF%BC%BD+%E3%83%A2%E3%83%87%E3%83%AB%E3%81%AE%E4%B8%AD%E3%81%AB%E5%BC%B7%E3%81%84%E7%9B%B8%E9%96%A2%E9%96%A2%E4%BF%82%E3%82%92%E3%82%82%E3%81%A4%E8%A4%87%E6%95%B0%E3%81%AE%E8%AA%AC%E6%98%8E%E5%A4%89%E6%95%B0%E3%82%92%E5%85%A5%E3%82%8C%E3%81%A6%E3%81%97%E3%81%BE%E3%81%A3%E3%81%9F%E3%80%82+%E6%8E%A8%E5%AE%9A%E5%80%A4%E3%81%AE%E7%AC%A6%E5%8F%B7%E3%81%8C%E7%90%86%E8%AB%96%E3%81%AB%E4%B8%80%E8%87%B4%E3%81%97%E3%81%AA%E3%81%84%E3%80%82.jpg "決定係数R2は大きいのに、個々のt値が小さい。 データの値を少し変えたり、少し追加・削除すると、係数推定値が大きく変化する。 説明変数を増減すると、推定値が大きく変化する。")
7
<完全な多重共線性> Y=a+bX+cW+u というモデルを考える。このモデルにおいて、W=αXという関係があったとする。 このとき、正規方程式は次のようになる。 3本目の方程式は2本目の方程式をα倍したものとなり、実質的には2本の連立方程式である。 未知数は の3つであるのに対し、方程式は2つであるので、解を一意に決定することはできない。

8
(数値例について) 数値例について次のようなことがいえる。 これらが多重共線性の[症状]である。 R2は大きいのに、t値は有意ではない。
数値例について次のようなことがいえる。 R2は大きいのに、t値は有意ではない。 データを少し変化させたときに、係数推定値は大きく変化する。 Wの係数の符号は負となるので、分析結果からはWが大きくなるとき、Yは小さくなるという結論が導き出されるが、データをみるとその逆である。(YとWには正の相関がある。R=0.7) これらが多重共線性の[症状]である。 多重共線性を幾何的に考えると、1枚の平面を1本の直線で支えることによっておきる不安定性である。(右図)
![(数値例について) 数値例について次のようなことがいえる。 これらが多重共線性の[症状]である。 R2は大きいのに、t値は有意ではない。](http://slidesplayer.net/slide/11278008/61/images/8/%EF%BC%88%E6%95%B0%E5%80%A4%E4%BE%8B%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%EF%BC%89+%E6%95%B0%E5%80%A4%E4%BE%8B%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%E6%AC%A1%E3%81%AE%E3%82%88%E3%81%86%E3%81%AA%E3%81%93%E3%81%A8%E3%81%8C%E3%81%84%E3%81%88%E3%82%8B%E3%80%82+%E3%81%93%E3%82%8C%E3%82%89%E3%81%8C%E5%A4%9A%E9%87%8D%E5%85%B1%E7%B7%9A%E6%80%A7%E3%81%AE%5B%E7%97%87%E7%8A%B6%5D%E3%81%A7%E3%81%82%E3%82%8B%E3%80%82+R2%E3%81%AF%E5%A4%A7%E3%81%8D%E3%81%84%E3%81%AE%E3%81%AB%E3%80%81t%E5%80%A4%E3%81%AF%E6%9C%89%E6%84%8F%E3%81%A7%E3%81%AF%E3%81%AA%E3%81%84%E3%80%82.jpg "数値例について次のようなことがいえる。 R2は大きいのに、t値は有意ではない。 データを少し変化させたときに、係数推定値は大きく変化する。 Wの係数の符号は負となるので、分析結果からはWが大きくなるとき、Yは小さくなるという結論が導き出されるが、データをみるとその逆である。(YとWには正の相関がある。R=0.7) これらが多重共線性の[症状]である。 多重共線性を幾何的に考えると、1枚の平面を1本の直線で支えることによっておきる不安定性である。(右図)")
9
※ VIF(Variance Inflation Factor)値について VIF値は個々の説明変数について、次のように定義される。
[判定法] 相関係数行列 VIF値 ※ VIF(Variance Inflation Factor)値について VIF値は個々の説明変数について、次のように定義される。 ここで、R2i はi番目の説明変数を他の説明変数に対して回帰した場合の決定係数であり、説明変数が2つのみの場合には、単相関係数の2乗となる。 このVIFが10を超えるような場合には、多重共線性の疑いがあるという判断をする。
値について. VIF値は個々の説明変数について、次のように定義される。 ここで、R2i はi番目の説明変数を他の説明変数に対して回帰した場合の決定係数であり、説明変数が2つのみの場合には、単相関係数の2乗となる。 このVIFが10を超えるような場合には、多重共線性の疑いがあるという判断をする。")
10
多重共線性が起こっている場合、相関の高い複数(ここでは2つとする)の変数のうち、1つをとり除くことが根本的な解決法である。
[対処法] 相関の高い説明変数のいずれかを除去する。(根治療法) データの期間を延長する、あるいは年次データでだめなら四半期データや月次データなどを用いて、データの数を増やす。 説明変数や被説明変数を階差あるいは比率の形にする。 相関の高い説明変数を合成し、新しい説明変数を作る。 主成分回帰やリッジ回帰などの方法を用いる。(非常手段) 多重共線性が起こっている場合、相関の高い複数(ここでは2つとする)の変数のうち、1つをとり除くことが根本的な解決法である。 しかし、経済理論から考えて、1つをとり除くことが不可能なこともあり、その場合には下のいくつかの対処法をとることになる。
 データの期間を延長する、あるいは年次データでだめなら四半期データや月次データなどを用いて、データの数を増やす。 説明変数や被説明変数を階差あるいは比率の形にする。 相関の高い説明変数を合成し、新しい説明変数を作る。 主成分回帰やリッジ回帰などの方法を用いる。(非常手段) 多重共線性が起こっている場合、相関の高い複数(ここでは2つとする)の変数のうち、1つをとり除くことが根本的な解決法である。 しかし、経済理論から考えて、1つをとり除くことが不可能なこともあり、その場合には下のいくつかの対処法をとることになる。")
11
第2節 系列相関 1 系列相関 撹乱項utには次のような仮定をおいてきた。 ① utは正規分布にしたがう。 ② utの平均は0である。
第2節 系列相関 1 系列相関 撹乱項utには次のような仮定をおいてきた。 ① utは正規分布にしたがう。 ② utの平均は0である。 ③ utの分散は一定値σ2である。 ④ 撹乱項utは相互に独立である。 このうちの④の仮定が満たされないことが系列相関である。 すなわち、時系列データにおいて、異なる2時点の撹乱項utとusの間に相関があるということである。

12
[原因] [症状] [判定法] 重要な説明変数の欠落 経済行動における習慣性やショックの影響の継続 データの加工時
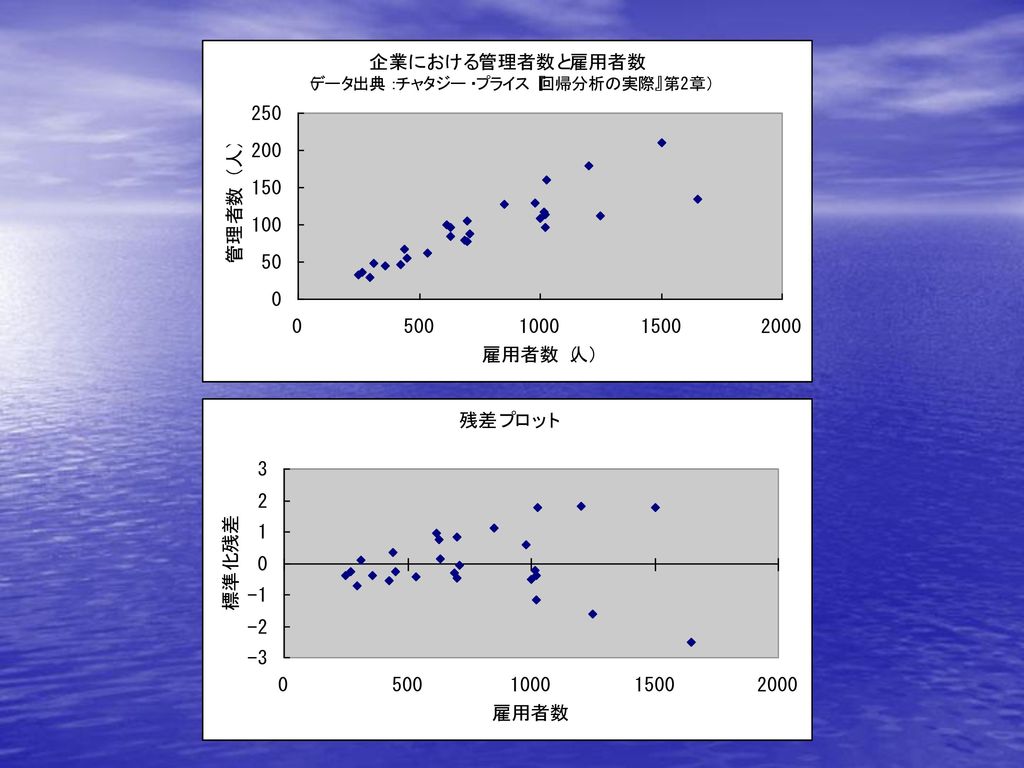
回帰係数の推定値はBLUEではなく、標準誤差を過小推定してしまう。 ⇒ t値、F値、R2などを大きめに計算してしまい、本当は有意でないものを誤って有意とみなす。 ⇒ 本当は妥当でないモデルを、誤って妥当であると結論づけてしまう危険がある。 [判定法] 残差プロット ダービン・ワトソン比(利用できない場合もある)
![[原因] [症状] [判定法] 重要な説明変数の欠落 経済行動における習慣性やショックの影響の継続 データの加工時](http://slidesplayer.net/slide/11278008/61/images/12/%EF%BC%BB%E5%8E%9F%E5%9B%A0%EF%BC%BD+%EF%BC%BB%E7%97%87%E7%8A%B6%EF%BC%BD+%EF%BC%BB%E5%88%A4%E5%AE%9A%E6%B3%95%EF%BC%BD+%E9%87%8D%E8%A6%81%E3%81%AA%E8%AA%AC%E6%98%8E%E5%A4%89%E6%95%B0%E3%81%AE%E6%AC%A0%E8%90%BD+%E7%B5%8C%E6%B8%88%E8%A1%8C%E5%8B%95%E3%81%AB%E3%81%8A%E3%81%91%E3%82%8B%E7%BF%92%E6%85%A3%E6%80%A7%E3%82%84%E3%82%B7%E3%83%A7%E3%83%83%E3%82%AF%E3%81%AE%E5%BD%B1%E9%9F%BF%E3%81%AE%E7%B6%99%E7%B6%9A+%E3%83%87%E3%83%BC%E3%82%BF%E3%81%AE%E5%8A%A0%E5%B7%A5%E6%99%82.jpg "回帰係数の推定値はBLUEではなく、標準誤差を過小推定してしまう。 ⇒ t値、F値、R2などを大きめに計算してしまい、本当は有意でないものを誤って有意とみなす。 ⇒ 本当は妥当でないモデルを、誤って妥当であると結論づけてしまう危険がある。 [判定法] 残差プロット. ダービン・ワトソン比(利用できない場合もある)")
13
2 系列相関の判定 -ダービン・ワトソン比- Yt=a+bXt+ut というモデルを考える。このモデルの誤差項に ut= ρut-1 +εt という系列相関が存在していたとする。(これを1階の自己相関という) このとき H0: ρ= 0 (系列相関なし) H1: ρ≠ 0 (系列相関あり) という検定が考えられる。このH0: ρ= 0を検定する代わりに用いられるのがダービン・ワトソン(DW)比である。
 H1: ρ≠ 0 (系列相関あり) という検定が考えられる。このH0: ρ= 0を検定する代わりに用いられるのがダービン・ワトソン(DW)比である。")
14
ダービン・ワトソン比は残差e1,e2,…,enを用いて次のように表すことができる。
この統計量は ut= ρut-1 +εt のutをetでおきかえて最小2乗法を適用した推定値を とすると、nが十分に大きいとき、 DW≒2(1- ) という関係が成り立つ。 のとき、DW=2であることから、DWの値が2に近ければ系列相関が存在しないという判断をする。 正の 系列相関 判定不能 系列相関なし 判定不能 負の 系列相関 dL dU 2 4-dU 4-dL 4
 という関係が成り立つ。 のとき、DW=2であることから、DWの値が2に近ければ系列相関が存在しないという判断をする。 正の. 系列相関. 判定不能. 系列相関なし. 判定不能. 負の. 系列相関. dL. dU dU. 4-dL. 4.")
15
<正の系列相関の例> ρ>0 ⇔ DW<2 正の系列相関がある場合は、残差が同じ符号のまま、ある程度の期間続く。

16
<負の系列相関の例> ρ<0 ⇔ DW>2
負の系列相関がある場合は、残差の符号が+,-, +,-, ・・・とある程度交互に続く。

17
<系列相関のない例> ρ≒0 ⇔ DW≒2 系列相関がない場合は、正の系列相関と負の系列相関のちょうど中間になる。

18
[対処法] 重要な説明変数を追加する(根治療法) 関数形が正しいか確認する
ショックの影響がないか確認する(影響がある場合にはダミー変数を用いる) 以上のようなモデルの妥当性を検証した後で、モデルが妥当であるにもかかわらず、系列相関が存在する場合には、通常の最小2乗法の代わりに次のような推定法を用いて、係数の推定を行う。 コクラン・オーカット法 一般化最小2乗法 最尤法
![[対処法] 重要な説明変数を追加する(根治療法) 関数形が正しいか確認する](http://slidesplayer.net/slide/11278008/61/images/18/%EF%BC%BB%E5%AF%BE%E5%87%A6%E6%B3%95%EF%BC%BD+%E9%87%8D%E8%A6%81%E3%81%AA%E8%AA%AC%E6%98%8E%E5%A4%89%E6%95%B0%E3%82%92%E8%BF%BD%E5%8A%A0%E3%81%99%E3%82%8B%EF%BC%88%E6%A0%B9%E6%B2%BB%E7%99%82%E6%B3%95%EF%BC%89+%E9%96%A2%E6%95%B0%E5%BD%A2%E3%81%8C%E6%AD%A3%E3%81%97%E3%81%84%E3%81%8B%E7%A2%BA%E8%AA%8D%E3%81%99%E3%82%8B.jpg "ショックの影響がないか確認する(影響がある場合にはダミー変数を用いる) 以上のようなモデルの妥当性を検証した後で、モデルが妥当であるにもかかわらず、系列相関が存在する場合には、通常の最小2乗法の代わりに次のような推定法を用いて、係数の推定を行う。 コクラン・オーカット法. 一般化最小2乗法. 最尤法.")
19
5 系列相関への対処法(2) -コクラン・オーカット法-
Yt=a+bXt+ut ut= ρut-1 +εt, という誤差項に1階の自己相関を持つモデルを考える。 (主要参考書のαは、ここでのρに対応します) ここで、Yt - ρYt-1を考えると とおき、Yt*をXt*に対して回帰すれば、 誤差項から系列相関の影響が取り除かれる。
 ここで、Yt - ρYt-1を考えると. とおき、Yt*をXt*に対して回帰すれば、 誤差項から系列相関の影響が取り除かれる。")
20
<手順1> YtをXtに回帰し、推定値 を求める。 <手順2> を計算し、 を求める。 etをutの代わりに用い、 とし、 を求める。 <手順3、4> とし、Yt*をXt*に対して回帰すれば、 誤差項から系列相関の影響が取り除かれる。 ※ 問題点 最初の期のデータは取り除かれてしまう。

21
4 系列相関への対処法(1) -一般化最小2乗法-
4 系列相関への対処法(1) -一般化最小2乗法- (ここではプレイス・ウインステン変換による一般化最小2乗法を取り上げる) <コクラン・オーカット法との相違> 1期目のデータを作成する 定数項を変数とみなし、定数項なしの回帰分析を適用する。 とおき、Yt*をXt*とZt*に対して回帰すれば、 誤差項から系列相関の影響が取り除かれる。
 -一般化最小2乗法- (ここではプレイス・ウインステン変換による一般化最小2乗法を取り上げる) <コクラン・オーカット法との相違> 1期目のデータを作成する. 定数項を変数とみなし、定数項なしの回帰分析を適用する。 とおき、Yt*をXt*とZt*に対して回帰すれば、 誤差項から系列相関の影響が取り除かれる。")
22
コクラン・オーカット法 一般化最小2乗法

23
3 ダービンのh統計量 系列相関があるかないかの判定基準として、ダービン・ワトソン比が用いられるが、DW比では正確な判定ができないケースがある。 それは、 というように、説明変数として被説明変数の過去の値(ラグつき内生変数という)を含む場合である。 この場合、DW比は2に偏りを持つ(本当は系列相関のあるモデルを、誤って「系列相関なし」と判断してしまう)ので、代わりにダービンのh統計量を用いる。
ので、代わりにダービンのh統計量を用いる。")
24
hは標準正規分布にしたがうので、有意水準5%で次のようになる。
n: 標本数 :パラメータ の分散の推定値 hは標準正規分布にしたがうので、有意水準5%で次のようになる。 負の 系列相関 系列相関なし 正の 系列相関 -1.96 1.96

25
第3節 不均一分散 1 不均一分散 撹乱項utには次のような仮定をおいてきた。 ① utは正規分布にしたがう。 ② utの平均は0である。
第3節 不均一分散 1 不均一分散 撹乱項utには次のような仮定をおいてきた。 ① utは正規分布にしたがう。 ② utの平均は0である。 ③ utの分散は一定値σ2である。 ④ 撹乱項utは相互に独立である。 このうちの③の仮定が満たされないことが不均一分散である。

26
[原因] [症状] [判定法] 変数のレベルが上昇することに伴って、分散が増大することが多い。
(例) 平均が10倍になれば、それにともなって分散も増える。 [症状] 回帰係数の標準誤差を過小推定してしまう。 ⇒ t値、F値、R2などを大きめに計算してしまい、本当は有意でないものを誤って有意とみなす。 ⇒ 本当は妥当でないモデルを、誤って妥当であると結論づけてしまう危険がある。 [判定法] 残差プロット 各種検定 ゴールドフェルド・クォントの検定 ブローシュ・ペーガンの検定 ホワイトの検定 ラグランジュ乗数(LM)検定
![[原因] [症状] [判定法] 変数のレベルが上昇することに伴って、分散が増大することが多い。](http://slidesplayer.net/slide/11278008/61/images/26/%EF%BC%BB%E5%8E%9F%E5%9B%A0%EF%BC%BD+%EF%BC%BB%E7%97%87%E7%8A%B6%EF%BC%BD+%EF%BC%BB%E5%88%A4%E5%AE%9A%E6%B3%95%EF%BC%BD+%E5%A4%89%E6%95%B0%E3%81%AE%E3%83%AC%E3%83%99%E3%83%AB%E3%81%8C%E4%B8%8A%E6%98%87%E3%81%99%E3%82%8B%E3%81%93%E3%81%A8%E3%81%AB%E4%BC%B4%E3%81%A3%E3%81%A6%E3%80%81%E5%88%86%E6%95%A3%E3%81%8C%E5%A2%97%E5%A4%A7%E3%81%99%E3%82%8B%E3%81%93%E3%81%A8%E3%81%8C%E5%A4%9A%E3%81%84%E3%80%82.jpg "(例) 平均が10倍になれば、それにともなって分散も増える。 [症状] 回帰係数の標準誤差を過小推定してしまう。 ⇒ t値、F値、R2などを大きめに計算してしまい、本当は有意でないものを誤って有意とみなす。 ⇒ 本当は妥当でないモデルを、誤って妥当であると結論づけてしまう危険がある。 [判定法] 残差プロット. 各種検定. ゴールドフェルド・クォントの検定. ブローシュ・ペーガンの検定. ホワイトの検定. ラグランジュ乗数(LM)検定.")
28
不均一分散の判定は、残差プロットを見ることや、さまざまな検定をおこなうことによる。
2 不均一分散の判定 不均一分散の判定は、残差プロットを見ることや、さまざまな検定をおこなうことによる。 不均一分散の検定の1つにゴールドフェルド・クォントの検定がある。この検定はデータの期間をいくつかに分割し、それぞれの期間ごとの誤差項の分散が均一かどうかを検定するものである。 ※ 不均一分散の検定は一般に を考える。すなわち、「誤差項の分散が均一である」ということが帰無仮説であり、「均一分散の検定」といったほうが適切である。

29
<検定の手順> [対処法] データをXの大きさの順に並べる(重回帰の場合には の大きさの順が適当であろう)。
全体をn個としたとき、(n-m)/2, m, (n-m)/2 個の3つに分割する。ここでmは全体の2割弱程度が適当である。 X1, X2 , ・・・, ・・・ , ・・・, X n-1, Xn Y1, Y2 , ・・・, ・・・ , ・・・, Y n-1, Yn └Ⅰ┘ └Ⅱ┘ └Ⅲ┘ ⅠのグループとⅢのグループで個別に回帰分析をおこない、それぞれの残差分散s2をもとめる。Ⅰのグループの残差分散s12とⅢのグループの残差分散s32の比を考えると、その値は自由度((n - m)/2 - k, (n - m)/2 - k)のF分布にしたがう。 よってこの統計量について仮説検定をおこなえばよい。 [対処法] 説明変数と被説明変数について、対数変換など変換をおこなう。 加重最小2乗法または最尤法を用いる。
![<検定の手順> [対処法] データをXの大きさの順に並べる(重回帰の場合には の大きさの順が適当であろう)。](http://slidesplayer.net/slide/11278008/61/images/29/%EF%BC%9C%E6%A4%9C%E5%AE%9A%E3%81%AE%E6%89%8B%E9%A0%86%EF%BC%9E+%EF%BC%BB%E5%AF%BE%E5%87%A6%E6%B3%95%EF%BC%BD+%E3%83%87%E3%83%BC%E3%82%BF%E3%82%92X%E3%81%AE%E5%A4%A7%E3%81%8D%E3%81%95%E3%81%AE%E9%A0%86%E3%81%AB%E4%B8%A6%E3%81%B9%E3%82%8B%28%E9%87%8D%E5%9B%9E%E5%B8%B0%E3%81%AE%E5%A0%B4%E5%90%88%E3%81%AB%E3%81%AF+%E3%81%AE%E5%A4%A7%E3%81%8D%E3%81%95%E3%81%AE%E9%A0%86%E3%81%8C%E9%81%A9%E5%BD%93%E3%81%A7%E3%81%82%E3%82%8D%E3%81%86%29%E3%80%82.jpg "全体をn個としたとき、(n-m)/2, m, (n-m)/2 個の3つに分割する。ここでmは全体の2割弱程度が適当である。 X1, X2 , ・・・, ・・・ , ・・・, X n-1, Xn. Y1, Y2 , ・・・, ・・・ , ・・・, Y n-1, Yn. └Ⅰ┘ └Ⅱ┘ └Ⅲ┘ ⅠのグループとⅢのグループで個別に回帰分析をおこない、それぞれの残差分散s2をもとめる。Ⅰのグループの残差分散s12とⅢのグループの残差分散s32の比を考えると、その値は自由度((n - m)/2 - k, (n - m)/2 - k)のF分布にしたがう。 よってこの統計量について仮説検定をおこなえばよい。 [対処法] 説明変数と被説明変数について、対数変換など変換をおこなう。 加重最小2乗法または最尤法を用いる。")
30
3 不均一分散の解決法(1) 撹乱項の分散について というように、説明変数の2乗に比例していると仮定する。
3 不均一分散の解決法(1) 撹乱項の分散について というように、説明変数の2乗に比例していると仮定する。 説明変数と被説明変数をそれぞれXiで割ると、このように変形できる。 ここで、 であるので、このモデルの撹乱項の分散はすべてσ2となる。 よって、 を に回帰すればよい。
 撹乱項の分散について. というように、説明変数の2乗に比例していると仮定する。 説明変数と被説明変数をそれぞれXiで割ると、このように変形できる。 ここで、 であるので、このモデルの撹乱項の分散はすべてσ2となる。 よって、 を に回帰すればよい。")
31
4 不均一分散の解決法(2) -加重最小2乗法- を最小とするものである。 このモデルは、変数をすべて で割ったものである。
4 不均一分散の解決法(2) -加重最小2乗法- 撹乱項の分散がすべて既知であったとする。 このとき、加重2乗和 を最小とするものである。 このモデルは、変数をすべて で割ったものである。 このように、 を に回帰すればよい。
 -加重最小2乗法- 撹乱項の分散がすべて既知であったとする。 このとき、加重2乗和. を最小とするものである。 このモデルは、変数をすべて で割ったものである。 このように、 を に回帰すればよい。")



 2 項分布、ポアソン分布、ガウス分布 ( 1H ) 最小二乗法( 1H )>")


 第12章 単回帰分析 廣野元久.>")
 寺尾 敦 青山学院大学社会情報学部 atsushi@si.aoyama.ac.jp.>")

 ー 計量経済学 ー.>")










