Download presentation
2
情報処理課題を実行する機械を 理解するのに必要な3つの水準 計算理論 Computational theory
計算の目標は何か、なぜそれが適切なのか、 そしてその実行可能な方略の理論は何か 表現とアルゴリズム Representation and algorithm この計算理論はどのようにして実現すること ができるか。特に入力と出力の表現は何か、 そして変換のためのアルゴリズムは何か ハードウェアによる実現 Hardware implementation 表現とアルゴリズムがどのようにして物理的 に実現されるか

4
日本の脳研究 脳を守る 脳を知る 脳を創る

5
脳を創ることによって知る ロボットやコンピュータは人にくらべてずっと劣る 本当には脳が分かっていない 創ってみて初めて働きが分かる
脳だけを創っても不十分で、ヒトを創ってみる アトム計画

6
計算論的神経科学 脳の機能を 理解する 脳の機能を、その機能を脳と同じ 方法で実現できる計算機のプログ
脳の機能を 理解する 脳の機能を、その機能を脳と同じ 方法で実現できる計算機のプログ ラムあるいは人工的な機械を作れる程度に、深く本質的に理解する ことを目指すアプローチを計算論 的神経科学と呼ぶ。 脳の機能を 計算機のプログ ラムあるいは人工的な機械で実現する 脳の機能を、その機能を脳と同じ 方法で実現できる計算機のプログ ラムあるいは人工的な機械を作れる程度に、深く本質的に理解する ことを目指すアプローチを計算論 的神経科学と呼ぶ。 Biped 人工知能・ロボティクス 神経科学

7
ヒューマノイドDB (Dynamic Brain)
30 自由度 身長190 cm 体重80 kg 柔らかい 生物に学んだ眼球運動・視覚系 SRCとKDBの共同開発 We have been working on interdisciplinary research issues of humans and humanoids. This shows our humanoid, and was developed to mimick humans and face similar problems as possible as we can. Salient features of this robot is all joints are hydraulically-operated and compliant, and its oculomotor system is also biomimetic. (Movie 11s.) (total 25 s)
 (total 25 s)")
8
生物に学んだ眼球運動・視覚系 それぞれの眼球に2自由度 人工前庭器官:ジャイロセンサー 中心かと周辺視は2台のカメラ DB 26 Arts
And today’s issue is on the biomimetic oculomotor system. It has 2 DOFs for eye. The head carries gyro-sensors to mimick semicircular-canal. Each eye consits of 2 cameras, one is for foveal vision, and the other is for peripheral vision using lenses having different view angles. Now it’s showing the difference in blurring between foveal vision and peripheral vision during I’m perturbing it. You may be suffering from motion sickness by the foveal image Due to the narrow foveal vision, oculomotor control should be very accurate if you would like to inspect a target on the fovea. (movie 30s) (total 45 s) DB 26 Arts
 (total 45 s) DB 26 Arts.")
9
神経科学とロボティックス 小脳内部モデルの教師あり学習 大脳皮質確率的内部モデルの教師なし学習 大脳基底核の強化学習
視覚運動変換、棒立て、見まね学習 眼球運動の学習、視覚追跡ターゲットの内部モデル エアホッケーの見まね学習、起きあがりロボットの強化学習

10
小脳と大脳 外側面 内側面 小脳 大脳 重 さ 130g 1対10 1,300g 表面積 50,000mm2 1対2 80,000mm2
小脳 大脳 重 さ 130g 1対10 1,300g 表面積 50,000mm2 1対2 80,000mm2 ニューロン数 > 1011 霊長類から 〜 3.2 の拡大率 底面

11
小脳各部への主要な入力と出力 機能部位 解剖学的 主入力 出力核 出力最終目標 機能 部位
機能部位 解剖学的 主入力 出力核 出力最終目標 機能 部位 前庭小脳 片葉 前庭器官 前庭核 動眼運動 前庭動眼反射 ニューロン 脊髄小脳 虫部 脊髄 室頂核 脳幹 体幹運動制御 視聴覚 運動野 前庭 脊髄小脳 中間部 脊髄 中位核 大細胞性赤核 末梢部運動制御 運動野 大脳小脳 外側部 大脳 歯状核 小細胞性赤核 運動開始 運動野 計画 運動前野 タイミング

12
小脳皮質の神経回路・可塑性・理論 Marr-Albus-Ito理論 (〜1970) ・登上線維が教師(誤差信号)
・平行線維-プルキンエ細胞の シナプス効率が可塑性により変化 星状細胞 平行線維 バスケット 細胞 プルキンエ 細胞 苔状線維 平行線維 ゴルジ 細胞 プルキンエ細胞 プルキンエ 細胞 登上線維 顆粒細胞 グロメルルス 顆粒細胞 下オリーブ核 ニューロン 登上線維 長期抑圧・長期増強・RP (1982〜) 小脳内部モデル理論 (1984〜) ・小脳皮質は内部モデルを獲得 ・登上線維は運動指令誤差 プルキンエ 細胞軸策 苔状線維
 小脳内部モデル理論 (1984〜) ・小脳皮質は内部モデルを獲得. ・登上線維は運動指令誤差. プルキンエ. 細胞軸策. 苔状線維.")
13
A フィードバック制御 B 逆モデルによる前向き制御 制御対象 時間遅れ 剛性、粘性 運動指令 目標軌道 実現された軌道 ゲイン

16
PFMによるヒト腕剛性の測定

19
A フィードバック制御 B 逆モデルによる前向き制御 制御対象 時間遅れ 剛性、粘性 運動指令 目標軌道 実現された軌道 ゲイン

20
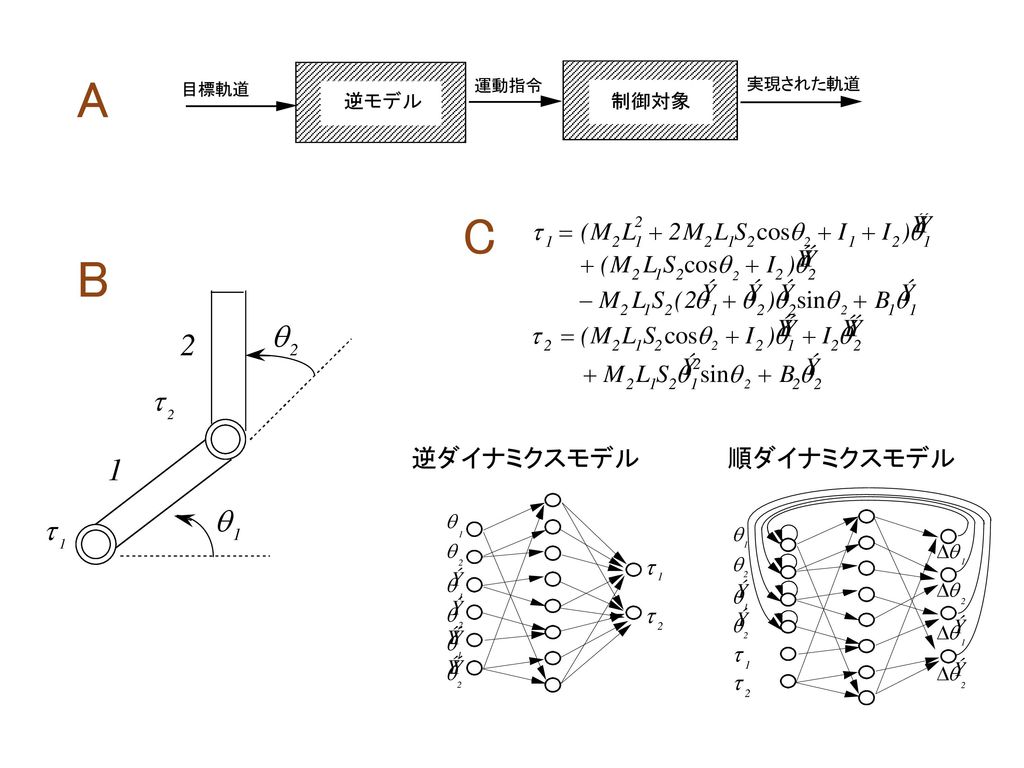
A C B 逆ダイナミクスモデル 順ダイナミクスモデル

21
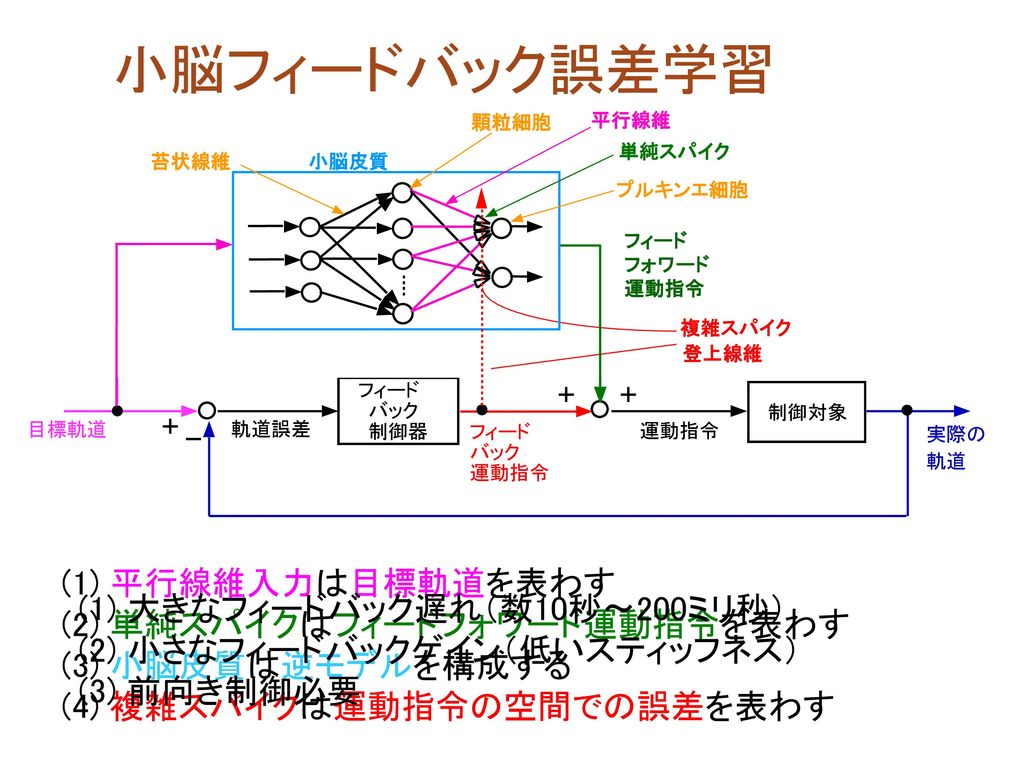
小脳フィードバック誤差学習 (1) 平行線維入力は目標軌道を表わす (2) 単純スパイクはフィードフォワード運動指令を表わす
小脳皮質 単純スパイク 複雑スパイク 苔状線維 顆粒細胞 プルキンエ細胞 平行線維 登上線維 フィード フォワード 運動指令 逆モデル 運動指令 誤差 フィード フォワード (1) 平行線維入力は目標軌道を表わす (2) 単純スパイクはフィードフォワード運動指令を表わす (3) 小脳皮質は逆モデルを構成する (4) 複雑スパイクは運動指令の空間での誤差を表わす (1) 大きなフィードバック遅れ(数10秒〜200ミリ秒) (2) 小さなフィードバックゲイン(低いスティッフネス) (3) 前向き制御必要
 平行線維入力は目標軌道を表わす. (2) 単純スパイクはフィードフォワード運動指令を表わす. (3) 小脳皮質は逆モデルを構成する. (4) 複雑スパイクは運動指令の空間での誤差を表わす. (1) 大きなフィードバック遅れ(数10秒〜200ミリ秒) (2) 小さなフィードバックゲイン(低いスティッフネス) (3) 前向き制御必要.")
22
運動指令に関しての教師あり学習との比較 フィードバック誤差学習則 教師あり学習 (1) 運動指令の教師信号が と与えられていて、2乗誤差
運動指令の教師信号が と与えられていて、2乗誤差 を の最急降下方向に 減少させる(Widrow-Hoff 則) (2) が を近似している。つまり、フィードバック 運動指令が、逆モデルを学習するための運動指令の誤差信号と して働いている と が同じ座標系で表現されている 2つの信号の時間経過はある程度似ている
 (2) が を近似している。つまり、フィードバック. 運動指令が、逆モデルを学習するための運動指令の誤差信号と. して働いている. と が同じ座標系で表現されている. 2つの信号の時間経過はある程度似ている.")
23
フィードバック誤差学習としてみたLTD, LTP
プルキンエ細胞の入出力モデル プルキンエ細胞の出力 は 本の平行線維入力 のシナプス荷重 による線形和 (1) LTDとLTPのモデル (2) フィードバック誤差学習による解釈 登上線維の発火頻度の自発放電からの がフィードバック制御器 の運動指令に対応 (3)
 LTDとLTPのモデル. (2) フィードバック誤差学習による解釈. 登上線維の発火頻度の自発放電からの がフィードバック制御器. の運動指令に対応. (3)")
24
複雑スパイクと単純スパイクの 近似的鏡像の相関 予測 フィードバック(学習後) : 鏡像 フィードバック(学習前) : 相関なし
フィードバック(学習後) : 鏡像 フィードバック(学習前) : 相関なし フィードフォワード(時間遅れ、学習後) : 複雑スパイク 運動開始時 フィードフォワード(時間遅れなし、学習後) : 複雑スパイク 消失
 : 鏡像. フィードバック(学習前) : 相関なし. フィードフォワード(時間遅れ、学習後) : 複雑スパイク 運動開始時. フィードフォワード(時間遅れなし、学習後) : 複雑スパイク 消失.")
25
追従眼球運動の神経生理学的研究 (電総研 河野、設楽、竹村、小林らによる実験) 背外側橋核 MST野 広い視野の動きにつられて
(電総研 河野、設楽、竹村、小林らによる実験) 背外側橋核 MST野 広い視野の動きにつられて 眼球が動く反射運動 小脳VPFL
 背外側橋核. MST野. 広い視野の動きにつられて. 眼球が動く反射運動. 小脳VPFL.")
26
+ - + - - + 小 脳 皮 質 顆 粒 プ ル キ ン エ 細 胞 細 胞 苔 状 大 脳 皮 質 線 M T M S T 維 上
側 頭 溝 壁 橋 核 視 覚 領 野 外 側 膝 状 体 平 行 線 維 登 上 線 維 + - 運 動 指 令 誤 差 視 覚 + 眼 球 副 視 索 系 外 眼 筋 運 動 網 膜 下 オ リ ー ブ 核 脳 幹 刺 激 - - 運 動 P T N O T ニ ュ ー ロ ン +

27
追従眼球運動と単純・複雑スパイク 眼球運動速度 50度/秒 下方向80度/秒 上方向80度/秒 複雑スパイク 単純スパイク 時間(ミリ秒)
")
28
同じ条件(1つのP-cell, 一定の視覚刺激速度)
のデータをアンサンブル平均した結果 stim. vel. [deg/sec] -20 視覚刺激速度 -40 0.30 VPFL発火頻度 [spike/msec] 0.20 0.10 0.00 2 眼球加速度 eye acc. [deg/sec ] -2500 眼球速度 eye vel. [deg/sec] -20 -40 眼球位置 eye pos.[deg] -4 200 250 300 350 400 450 time [msec]

29
プルキンエ細胞発火頻度の逆ダイナミクスモデル
5種類の刺激速度、6種類の刺激時間のデータから1組の係数を推定 Coeff.det 0.78 ・

30
SS one cell E 0.15 Instantaneous firing frequency is information carrier for complex spikes (CS) and simple spikes (SS). 0.1 50 0.05 100 200 CS one cell F 20 0.02 10 velocity 100 200 D 30 20 10 40 Time(ms) #Trials Firing frequency (degz/s) Probability 100 200 SS 9 cells G acceleration 0.1 50 (deg2/s) 0.05 100 200 CS 9 cells H position 0.01 5 (deg) Spikes/s Time(ms) 100 200 Time (ms)
 #Trials. Firing frequency. (degz/s) Probability SS 9 cells. G. acceleration (deg2/s) CS 9 cells. H. position (deg) Spikes/s. Time(ms) Time (ms)")
31
+ - + - - + 複 雑 ス パ イ ク 単 純 小 脳 皮 質 顆 粒 プ ル キ ン エ 細 胞 細 胞 苔 状 大 脳 皮 質
VPFLプルキンエ細胞 MST 野 背外側橋核 垂直細胞 水平細胞 100 200 0.05 0.1 50 0.01 5 複 雑 ス パ イ ク 時間 (ミリ秒) 単 純 発 火 確 率 数 / 秒 頻 度 C D I U C D I U U U C I C I D D 小 脳 皮 質 顆 粒 プ ル キ ン エ 細 胞 細 胞 苔 状 大 脳 皮 質 線 M T M S T 維 上 側 頭 溝 壁 橋 核 視 覚 領 野 外 側 膝 状 体 平 行 線 維 登 上 線 維 + - 運 動 指 令 誤 差 視 覚 + 眼 球 副 視 索 系 脳 幹 外 眼 筋 運 動 網 膜 下 オ リ ー ブ 核 刺 激 - - P T N O T ニ ュ ー ロ ン 運 動 +
 単. 純. 発. 火. 確. 率. 数. / 秒. 頻. 度. C. D. I. U. C. D. I. U. U. U. C. I. C. I. D. D. 小. 脳. 皮. 質. 顆. 粒. プ. ル. キ. ン. エ. 細. 胞. 細. 胞. 苔. 状. 大. 脳. 皮. 質. 線. M. T. M. S. T. 維. 上. 側. 頭. 溝. 壁. 橋. 核. 視. 覚. 領. 野. 外. 側. 膝. 状. 体. 平. 行. 線. 維. 登. 上. 線. 維. + - 運. 動. 指. 令. 誤. 差. 視. 覚. + 眼. 球. 副. 視. 索. 系. 脳. 幹. 外. 眼. 筋. 運. 動. 網. 膜. 下. オ. リ. ー. ブ. 核. 刺. 激. - - P. T. N. O. T. ニ. ュ. ー. ロ. ン. 運. 動. +")
32
A C B + - + - - + 単純スパイク 発火確率 発火頻度 複雑スパイク スパイク数 秒 時間(ミリ秒)
0.1 50 0.05 発火確率 0 100 200 発火頻度 複雑スパイク 0.01 5 MST野 背外側橋核 垂直細胞 水平細胞 スパイク数 秒 VPFLプルキンエ細胞 B 小脳皮質 顆粒 細胞 プルキンエ 細胞 0 100 200 時間(ミリ秒) 苔状線維 大脳皮質 Shidara M, Kawano K, Gomi H, Kawato M: Inverse-dynamics model eye movement control by Purkinje cells in the cerebellum. Nature, 365, (1993). MT MST 上側頭溝壁 橋核 視覚領野 Kawato M: Internal models for motor control and trajectory planning. Current Opinion in Neurobiology, 9, (1999). 外側膝状体 平行線維 登上線維 + 運動指令誤差 - 視覚 刺激 + 副視索系 網膜 下オリーブ核 脳幹 外眼筋運動 ニューロン 眼球運動 - - PT NOT +
 苔状線維. 大脳皮質. Shidara M, Kawano K, Gomi H, Kawato M: Inverse-dynamics model. eye movement control by Purkinje cells in the cerebellum. Nature, 365, (1993). MT. MST. 上側頭溝壁. 橋核. 視覚領野. Kawato M: Internal models for motor control and trajectory planning. Current Opinion in Neurobiology, 9, (1999). 外側膝状体. 平行線維. 登上線維. + 運動指令誤差. - 視覚. 刺激. + 副視索系. 網膜. 下オリーブ核. 脳幹. 外眼筋運動. ニューロン. 眼球運動. - - PT NOT. +")
33
大脳皮質高次視覚野MST 小脳皮質 脳幹を介する経路 平行線維 プルキンエ細胞 登上線維 平行線維 プルキンエ細胞 登上線維 視覚 刺激
網膜像 の動き 単純スパイク 登上線維の発火(複雑スパイク) 一般化線形 モデル 眼球運動 2次 フィルター 16000 脳幹を介する経路 平行線維 プルキンエ細胞 登上線維 平行線維 プルキンエ細胞 登上線維
 一般化線形. モデル. 眼球運動. 2次. フィルター 脳幹を介する経路. 平行線維. プルキンエ細胞. 登上線維. 平行線維. プルキンエ細胞. 登上線維.")
34
追従眼球運動を制御する小脳に逆モデルが存在することを示唆するデータと理論
(1) 単純スパイクの発火頻度時間波形が眼球の逆ダイナミクスモデルで再構成される (Shidara et al, 1993; Gomi et al., 1998). (2) 小脳への視覚入力は (MST, DLPN) 逆ダイナミクスモデルではなく網膜滑りでよく再構成される (Takemura et al., 2001). (3) 低い発火周波数の登上線維入力も逆ダイナミクスモデルで発火頻度が再構成され、単純スパイクとニューロンごとに鏡像関係にある (Kobayashi et al., 1998). (4) 追従眼球運動制御の神経回路のシミュレーション: 神経符号の変換が学習と適応で説明される (Yamamoto et al., 2002). (5) 前庭動眼反射の並列制御仮説に基づくシミュレーション (Tabata et al., 2002).
 単純スパイクの発火頻度時間波形が眼球の逆ダイナミクスモデルで再構成される (Shidara et al, 1993; Gomi et al., 1998). (2) 小脳への視覚入力は (MST, DLPN) 逆ダイナミクスモデルではなく網膜滑りでよく再構成される (Takemura et al., 2001). (3) 低い発火周波数の登上線維入力も逆ダイナミクスモデルで発火頻度が再構成され、単純スパイクとニューロンごとに鏡像関係にある (Kobayashi et al., 1998). (4) 追従眼球運動制御の神経回路のシミュレーション: 神経符号の変換が学習と適応で説明される (Yamamoto et al., 2002). (5) 前庭動眼反射の並列制御仮説に基づくシミュレーション (Tabata et al., 2002).")
35
大脳皮質 小脳皮質 ポピュレーション符号化 発火率符号化 確率的内部モデル 決定論的内部モデル 皮質ダイナミクス 入出力変換 確率分布 確率分布のモーメント 多重ピーク 競合するモジュール 教師なし学習 教師あり学習

36
「強化学習」 reinforcement learning
「報酬」を最大化するような行動を,探索により学習 環境に応じて異なる最適行動を獲得 目標出力がわからない問題に適用可 人間や動物の行動学習のモデル 応用例 ゲームプログラム:バックギャモン,オセロ,.. ロボット制御:移動ロボット,サッカー,... 動的資源配分:携帯電話チャネル割り当て,..

37
報酬が遅れを持って与えられる場合 u3 r3 x4 u4 r4 u1 action x1 x2 state u2 x3 r1 reward
報酬の直前の行動だけを考えたのでは不十分 途中の状態の評価が必要 状態の評価関数

38
単純な強化学習 将来の累積報酬を最大化するようなポリシーを見つける 状態と行動の関数としての価値関数を学習する エージェント (制御器)
クリティック 報酬 r(t) 価値関数 V(t) TDエラー (t) 行動 u(t) アクター 環境 (プラント) ポリシー μ(t) 状態 x(t) 将来の累積報酬を最大化するようなポリシーを見つける 状態と行動の関数としての価値関数を学習する
 価値関数. V(t) TDエラー. (t) 行動. u(t) アクター. 環境. (プラント) ポリシー. μ(t) 状態. x(t) 将来の累積報酬を最大化するようなポリシーを見つける. 状態と行動の関数としての価値関数を学習する.")
39
Basal Ganglia Frontal section Side view

40
ドーパミンニューロンが報酬予測を表現 (Schultz et al. 1993)
予期しない報酬 報酬を予告する刺激 報酬の欠如

41
ドーパミン細胞の報酬予測応答(Schultz et al. 1993)
")
42
計算理論からの拘束と 中心的な疑問 単純な強化学習は現実的な問題ではとても遅いので、内部モデル、モジュール性、階層性などが必要 (例、モデルに基づく階層強化学習、強化学習モザイクなど) 強化学習の行動の変容を引き起こすシナプス可塑性は大脳基底核線状体で起きているのか?
 強化学習の行動の変容を引き起こすシナプス可塑性は大脳基底核線状体で起きているのか?")
43
階層強化学習による ロボットの起きあがり 森本淳、銅谷賢治

44
強化学習モザイク Doya K, Samejima K, Katagiri K, Kawato M: Multiple model-based reinforcement learning. Neural Computation, 14, (2002)
 .")
45
ヒト強化学習は大脳基底核で行われている 新しいマルコフ遷移確率強化学習課題 学習と報酬に関する情報理論的変数 尾状核(比較的前方部)が本質
春野、黒田、銅谷、外山、木村、鮫島、今水、川人 A Neural Correlate of Reward-based Behavioral Leaning in Caudate Nucleus: An fMRI Study of a Stochastic Decision Task. Journal of Neuroscience, in press (2004)
")
46
金銭報酬付きの確率的決定タスク 行動学習と報酬予測を乖離させる

47
First Trial Second Trial Third Trial -5yen 0yen 0yen 5yen TEST

48
確率遷移規則 正しい行動が必ずしも報酬に結びつかない

50
短期報酬 (SR): 6回のボタン押し(1ターム)で得られた報酬の額
Dominant probability=0.8 短期報酬 (SR): 6回のボタン押し(1ターム)で得られた報酬の額 累積報酬 (AR): それぞれの遷移規則に対して学習のはじめから今まで得られた累計の報酬額 学習速度インデックス (LRI): 2つの隣接するターム間での行動変化の指数 学習収束インデックス (LCI): 現在と最後の行動の間の距離から測った、最適な行動にどれほど近いかの指数
: 6回のボタン押し(1ターム)で得られた報酬の額. 累積報酬 (AR): それぞれの遷移規則に対して学習のはじめから今まで得られた累計の報酬額. 学習速度インデックス (LRI): 2つの隣接するターム間での行動変化の指数. 学習収束インデックス (LCI): 現在と最後の行動の間の距離から測った、最適な行動にどれほど近いかの指数.")
51
被験者平均 Short-term reward (yen) Accumulated Reward (yen)
P= P= P= P=0.5 Short-term reward (yen) the amount of money obtained in 6 button pushes (one term) Accumulated Reward (yen) the amount of money accumulated from the start of each transition rule to the current term Learning rate index the amount of behavioral changes between two adjacent terms Learning convergence index the degree of learning convergence measured as the normalized similarity between the current and final button push strategy
 the amount of money obtained in. 6 button pushes (one term) Accumulated Reward (yen) the amount of money accumulated. from the start of each transition rule. to the current term. Learning rate index. the amount of behavioral changes. between two adjacent terms. Learning convergence index. the degree of learning convergence. measured as the normalized similarity. between the current and final button. push strategy.")
53
尾状核の活動と強化学習による行動の変容は
異なる学習の速度に対応して相関がある

54
明らかになったモジュール構造 尾状核 強化学習の主要な座で 、 短期報酬に導かれる (LRI and SR) 前頭眼窩野と前頭前野
強化学習の主要な座で 、 短期報酬に導かれる (LRI and SR) 前頭眼窩野と前頭前野 長期に渡る累積報酬 (AR) 小脳、運動前野、SMA 内部モデルの格納、最適行動の記憶と 実行 (LCI)
 前頭眼窩野と前頭前野. 長期に渡る累積報酬 (AR) 小脳、運動前野、SMA. 内部モデルの格納、最適行動の記憶と. 実行 (LCI)")
60
ビデオカメラによる運動認知 ˇ Ales Ude
ビデオに基づく人の動きの取り込み:ヒトの運動データをヒューマノイドロボットの動きに変換するためのキネマティックモデルを自動生成する。遮蔽がある場合にも2次元画面内で実時間で確率的にブロッブを追跡するアルゴリズムも示す。

61
センスーツを用いて、ヒトの関節の動き46自由度を同時に計測できる。これをDBの動きに変換するのは簡単な問題ではない。
センスーツTMデモ(ロックンロール) Stefan Schaal センスーツを用いて、ヒトの関節の動き46自由度を同時に計測できる。これをDBの動きに変換するのは簡単な問題ではない。
 Stefan Schaal. センスーツを用いて、ヒトの関節の動き46自由度を同時に計測できる。これをDBの動きに変換するのは簡単な問題ではない。")
62
キャッチボール Marcia Riley ボールの自由落下軌道を視覚に基づいて予測する。
腕の軌道は予測した把持位置まで前向きに計画され、制御される。

63
AIBO (SONY)
")
64
P2, P3 (HONDA)
")
65
運動軌道計画と軌道予測・力制御に基づいてヒトとロボットの物理的相互作用を行った。
スティッキーハンド Joshua Hale 運動軌道計画と軌道予測・力制御に基づいてヒトとロボットの物理的相互作用を行った。

66
ジャグリング Christopher Atkeson Chris Atkesonは上手なジャグラーです。
彼の3つ玉ジャグリングをDBにまねさせました。

67
沖縄舞踊(カチャーシ) Marcia Riley, Ales Ude, Christopher Atkeson, Stefan Schaal ˇ オプトトラックで踊り手の動きを計測し、それに基づいてB-スプライン ウェイブレットでヒューマノイドロボットの関節の軌道を計画した。

68
見まねによるテニス Stefan Schaal

69
小脳とヒト知性 ◎小脳部位の系統発生 ◎小脳のサイズと知能 小脳皮質 歯状核 背内側部 歯状核 腹外側部 大脳皮質左側頭葉は無相関
内側核0.8倍、歯状核4.5倍(キツネザル類比) 小脳皮質 歯状核 体重 体積 幅・高さ 長さ 65kg 1,167mm3 同じ 2倍 45kg mm3 同じ 半分 歯状核 背内側部 ヒト 歯状核 腹外側部 チンパ ンジー ◎小脳のサイズと知能 Paradiso (1997) 指タッピング r= p<0.05 言語記憶 r=0.27 p<0.02 一般的IQ r=0.19 p<0.07 (WAIS-R) 大脳皮質左側頭葉は無相関
 小脳皮質. 歯状核. 体重 体積 幅・高さ 長さ. 65kg 1,167mm3 同じ 2倍. 45kg 456mm3 同じ 半分. 歯状核. 背内側部. ヒト. 歯状核. 腹外側部. チンパ. ンジー. ◎小脳のサイズと知能. Paradiso (1997) 指タッピング r=0.22 p<0.05. 言語記憶 r=0.27 p<0.02. 一般的IQ r=0.19 p<0.07. (WAIS-R) 大脳皮質左側頭葉は無相関.")
70
小脳の高次認知機能への関与 I. 脳活動計測 II. 損傷脳 III. 解剖
(1) 運動の想像 SPECT Ryding et al. (1993) (2) 名詞からの動詞の連想 PET Raichle et al. (1994) (3) ペグボードパズル fMRI Kim et al. (1994) (4) 複数の形の視覚識別 PET Parsons et al. (1995) (5) 心的回転 PET Parsons et al. (1995) (6) 皮膚感覚による物体認識 fMRI Gao et al. (Bower) (1996) (7) 視覚的注意 fMRI Allen et al. (1997) II. 損傷脳 (1) ハノイの塔 小脳皮質変性症 Grafman et al. (Hallet M.) (1992) (2) 視覚運動認知 小脳皮質変性症 Nawrot & Rizzo (1995) (3) 自閉症患者 小脳サイズ Courchesne et al. (1995) III. 解剖 (1) 46野 HSVI Middleton & Strick (1994) (2) IQ 小脳サイズ Paradiso et al. (1997)
 運動の想像 SPECT Ryding et al. (1993) (2) 名詞からの動詞の連想 PET Raichle et al. (1994) (3) ペグボードパズル fMRI Kim et al. (1994) (4) 複数の形の視覚識別 PET Parsons et al. (1995) (5) 心的回転 PET Parsons et al. (1995) (6) 皮膚感覚による物体認識 fMRI Gao et al. (Bower) (1996) (7) 視覚的注意 fMRI Allen et al. (1997) II. 損傷脳. (1) ハノイの塔 小脳皮質変性症 Grafman et al. (Hallet M.) (1992) (2) 視覚運動認知 小脳皮質変性症 Nawrot & Rizzo (1995) (3) 自閉症患者 小脳サイズ Courchesne et al. (1995) III. 解剖. (1) 46野 HSVI Middleton & Strick (1994) (2) IQ 小脳サイズ Paradiso et al. (1997)")
72
計算論的神経回路モデルの学習で視覚運動変換を実現した。
視覚ー運動学習 Stefan Schaal 計算論的神経回路モデルの学習で視覚運動変換を実現した。

73
見まねによる棒立て:道具の内部モデル Stefan Schaal

74
サッカード Sethu Vijayakumar

75
神経生理学、解剖学の知識に基づいて前庭動眼反射の神経回路モデルをDBに組み込んだ。
前庭動眼反射適応 柴田智広 1.VOR 学習 研究内容自体は特に変わっておりません.ジョイントの stiction の改善を行なった後のビデオですので,前より見栄えがします. <内容> 1.カチャーシー+首の上下運動をしている際中にVOR学習をしていることを示す外部からの映像 2.周辺視における視覚処理を示す映像(retinal error と retinal slip を,それぞれテンプレート追跡器とオプティカルフロー算出によって行なっている). 3.VOR学習中の4つのカメラの出力.学習前と学習後の間はカットしてあり,少し分かりにくいです. 4.retinal error 算出のための追跡器を3個に増やし,しかも 画面中央ではなく,画面周辺に配置しています.これにより,人間が画像中央でダンスを教えても大丈夫,といったストーリーの映像です. 神経生理学、解剖学の知識に基づいて前庭動眼反射の神経回路モデルをDBに組み込んだ。
. 3.VOR学習中の4つのカメラの出力.学習前と学習後の間はカットしてあり,少し分かりにくいです. 4.retinal error 算出のための追跡器を3個に増やし,しかも 画面中央ではなく,画面周辺に配置しています.これにより,人間が画像中央でダンスを教えても大丈夫,といったストーリーの映像です. 神経生理学、解剖学の知識に基づいて前庭動眼反射の神経回路モデルをDBに組み込んだ。")
76
円滑性追跡眼球運動 柴田智広 2.Smooth Pursuit 学習 学習方法は先日トークで説明したものです. 1.振子の追跡.学習は左目に関して行なっており,右目ではフィードバック制御が行なわれています. 1.1 振子を追跡している際の外部からの映像. 1.2 振子を追跡している際の4つのカメラの出力. (技術的な補足)画像処理には QuickMag を使用しました. 2.人間の顔の追跡.学習は左目に関して行なっており,右目ではフィードバック制御が行なわれています. 2.1 顔を追跡している際の外部からの映像. 2.2 顔を追跡している際の4つのカメラの出力. 学習前と学習後の間はカットしてあり,少し分かりにくいです. 2.3 顔を追跡している際の PC での Ude さんの追跡器の処理の様子を示す映像. 円滑性追跡眼球運動をゲイン1で行うためには視覚入力速度が0の時にも視標の動きを身体座標で予測する必要がある。クイックマグと確率的トラッキングを用いてこれを実現した。
画像処理には QuickMag を使用しました. 2.人間の顔の追跡.学習は左目に関して行なっており,右目ではフィードバック制御が行なわれています. 2.1 顔を追跡している際の外部からの映像. 2.2 顔を追跡している際の4つのカメラの出力. 学習前と学習後の間はカットしてあり,少し分かりにくいです. 2.3 顔を追跡している際の PC での Ude さんの追跡器の処理の様子を示す映像. 円滑性追跡眼球運動をゲイン1で行うためには視覚入力速度が0の時にも視標の動きを身体座標で予測する必要がある。クイックマグと確率的トラッキングを用いてこれを実現した。")
77
眼球運動プリミティブの統合 柴田智広

78
行動プリミティブの記述に基づいて対戦型ゲームのヒトのやり方を観察して学習する。
エアホッケー Darrin Bentivegna Description: This video has two parts related to playing air hockey with a humanoid robot, DB. The first half show a person playing air hockey against the robot. In this video the robot is programmed with a playing strategy. It is the goal for the robot to learn a strategy from observing a human player. The second half shows the vision system used by DB to compute the position of the puck on the table. 行動プリミティブの記述に基づいて対戦型ゲームのヒトのやり方を観察して学習する。

79
中枢パターン生成機構が中枢神経系に存在し多くのリズム運動を作り出している。リミットサイクル振動子は外界からの周期的音響入力に同調する。
ドラミング、共演 琴坂信哉 中枢パターン生成機構が中枢神経系に存在し多くのリズム運動を作り出している。リミットサイクル振動子は外界からの周期的音響入力に同調する。

80
ボールと腕の運動が規定する物理学的ダイナミクスが安定なリミットサイクル解を持つことを利用してパドリングを行った。
Stefan Schaal ボールと腕の運動が規定する物理学的ダイナミクスが安定なリミットサイクル解を持つことを利用してパドリングを行った。

81
眼球運動のプリミティブ サッカード 前庭動眼反射 (VOR) 円滑性追跡眼球運動 追従眼球運動 (OFR)
 円滑性追跡眼球運動 追従眼球運動 (OFR)")
82
円滑性追跡眼球運動

83
5ヶ月の乳児では 円滑性追跡眼球運動はない 協力:本田佳野乃、大須理英子

84
5ヶ月の乳児では 追従眼球運動もない 協力:本田佳野乃、大須理英子

85
大脳皮質内部モデルと 小脳内部モデルの違い
眼球運動に関する小脳内部モデル 前庭動眼反射適応の論争 大脳皮質の内部モデル:確率分布の時間ダイナミクス 分散非線形カルマンフィルターとしての大脳小脳連関

86
小脳内部モデルが大脳ポピュレーション符号を解読する
フィードバック誤差学習によって、小脳がポピュレーション符号から発火率符号への復号器を学習で獲得する この復号器においてニューロンの最適刺激方向、速度選択性、発火頻度時間波形の特性が変換される 復号器の特性は制御対象の特性に応じて適応的に決まる

87
円滑性追跡眼球運動の視標消滅 眼球速度 視標消滅 眼球位置 視標位置 眼球運動 眼球位置 視標位置

88
円滑性追跡眼球運動の視標消滅 VS 追従眼球運動視覚刺激消滅 追従眼球運動 視覚刺激消滅 円滑性追跡眼球運動 追従眼球運動
MST野, 背外側橋核, 小脳皮質腹側傍片葉 随意 反射 小さな指標 大きな刺激 視標消滅: MST野と眼球運動 500ms間維持 視覚刺激消滅: MST野と眼球運動 速やかに消滅

89
MT野: 円滑性追跡眼球運動の 視標消滅 MSTd:円滑性追跡眼球運動の 視標消滅 背外側橋核: 追従眼球運動の 視覚刺激消滅
視標消滅 MSTd:円滑性追跡眼球運動の 視標消滅 Newsome et al., (1988) 背外側橋核: 追従眼球運動の 視覚刺激消滅 MST野: 円滑性追跡眼球運動の 視標消滅、潜時 Kawano et al., (1994) Kawano et al., (1992)
 背外側橋核: 追従眼球運動の. 視覚刺激消滅. MST野: 円滑性追跡眼球運動の. 視標消滅、潜時. Kawano et al., (1994) Kawano et al., (1992)")
90
VOR適応の座に関する小脳論争は 円滑性追跡眼球運動維持の場所で決まる
前庭動眼反射適応は主に小脳皮質のプルキンエ細胞のLTDによるものか? Yes:片葉仮説(伊藤) No: 視線速度理論 (Miles & Lisberger); 脳幹が中心 (Lisberger & Sejnowski) 『否』仮説では 脳幹ー小脳皮質のゲイン1のポジティブフィードバック回路が円滑性追跡眼球運動維持 『是』仮説では MST野で視標予測
 No: 視線速度理論 (Miles & Lisberger); 脳幹が中心 (Lisberger & Sejnowski) 『否』仮説では 脳幹ー小脳皮質のゲイン1のポジティブフィードバック回路が円滑性追跡眼球運動維持. 『是』仮説では MST野で視標予測.")
91
FL 登上線維 前庭入力 VN 眼球運動 FL VPFL 前庭入力 VN 眼球運動 視覚入力 MST FL VPFL 登上線維 前庭入力 VN 眼球運動

92
視線速度理論と並列制御経路理論の予測の比較
網膜上の滑りなし 円滑性追跡眼球運動 視標消滅 追従眼球運動 視覚刺激消滅 前庭動眼反射 暗闇 前庭動眼反射キャンセル 視線速度理論 並列制御 経路理論 視線速度理論と並列制御経路理論の予測の比較

93
確率分布のポピュレーション符号表現に基づくベイズフィルター
Kalmanフィルター:内部モデル、平均と分散の推定、予測誤差の適応的重み付け 平滑性追跡眼球運動のブリンク:時間がたつにつれて増加する視標運動の不確実性をポピュレーション神経活動の平坦化で表現 ポピュレーション符号が確率分布を表現する理論 (Zemel, Dayan, Pouget, Neural Comput, 1998). 平滑性追跡眼球運動の制御システムはベイズフィルターであり視標の運動の変化をポピュレーション符号で表現する
. 平滑性追跡眼球運動の制御システムはベイズフィルターであり視標の運動の変化をポピュレーション符号で表現する.")
94
円滑性追跡眼球運動と追従眼球運動の制御モデル
カルマンフィルターモデル Kt Ft Ht It + - 軌道入力 カルマンゲイン 遷移確率 推定確率 生成行列 Pt (r, V) ˆ 軌道入力 予測誤差 中心窩外 中心窩 + e f 小脳内部モデル による変換 プルキンエ細胞 眼球運動 シナプス荷重 網膜の滑り - 50ms 脳幹 視標の動き MST 小脳皮質 ポピュレーション符号 とMST神経場 カルマンゲイン 内部モデル 運動指令生成 推定入力
 ˆ. 軌道入力. 予測誤差. 中心窩外. 中心窩. + e. f. 小脳内部モデル. による変換. プルキンエ細胞. 眼球運動. シナプス荷重. 網膜の滑り. - 50ms. 脳幹. 視標の動き. MST. 小脳皮質. ポピュレーション符号. とMST神経場. カルマンゲイン. 内部モデル. 運動指令生成. 推定入力.")


















 ・たてがき / 縦書き (from right to.>")













