Download presentation
1
Bias2 - Variance - Noise 分解
クラシックな機械学習の入門 4. 学習データと予測性能 Bias2 - Variance - Noise 分解 過学習 損失関数と Bias,Variance, Noise K-Nearest Neighbor法への応用 bias2とvarianceの間のトレードオフの 線形回帰への応用 by 中川裕志(東京大学)
")
2
過学習:over-fitting 教師データによる学習の目的は未知のデータの正確な分類や識別 過学習(over-fitting)
教師データに追従しようとすればするほど、複雑なモデル(=パラメタ数の多い)になり、教師データへの過剰な適応が起こりやすい。 このことを数学的に整理してみるのが目的。
になり、教師データへの過剰な適応が起こりやすい。 このことを数学的に整理してみるのが目的。")
3
損失関数と Bias,Variance, Noise
xが与えられたときの結果:tの推定値=y(x) 損失関数: L(t,y(x)) ex. (y(x)-t)2 損失の期待値:E[L]を最小化する t の推定値=E[t|x] この導出は次の次のページを参考にしてください E[L]を計算してみると(次のページ参照) 第1項は予測値と学習データからの期待値の差の2乗、第2項は雑音(noise)
 損失関数: L(t,y(x)) ex. (y(x)-t)2. 損失の期待値:E[L]を最小化する t の推定値=E[t|x] この導出は次の次のページを参考にしてください. E[L]を計算してみると(次のページ参照) 第1項は予測値と学習データからの期待値の差の2乗、第2項は雑音(noise)")
4
参考:E[L]の計算
![参考:E[L]の計算](http://slidesplayer.net/slide/11479281/62/images/4/%E5%8F%82%E8%80%83%EF%BC%9AE%5BL%5D%E3%81%AE%E8%A8%88%E7%AE%97.jpg "参考:E[L]の計算")
5
参考:E[L]を最小化するt の推定値=E[t|x]の導出
![参考:E[L]を最小化するt の推定値=E[t|x]の導出](http://slidesplayer.net/slide/11479281/62/images/5/%E5%8F%82%E8%80%83%EF%BC%9AE%5BL%5D%E3%82%92%E6%9C%80%E5%B0%8F%E5%8C%96%E3%81%99%E3%82%8Bt+%E3%81%AE%E6%8E%A8%E5%AE%9A%E5%80%A4%3DE%5Bt%7Cx%5D%E3%81%AE%E5%B0%8E%E5%87%BA.jpg "参考:E[L]を最小化するt の推定値=E[t|x]の導出")
6
E[t|x]はxによって決まる。E[L]は次式でした。
第2項 ()内の左の項は、観測値として与えられたxに対してE[L]を最小化するtの予測値だから、()内の右の項すなわち真のt との差は、観測における誤差と考えられる。 y(x)の作り方で解決できないノイズ
![E[t|x]はxによって決まる。E[L]は次式でした。](http://slidesplayer.net/slide/11479281/62/images/6/E%5Bt%7Cx%5D%E3%81%AFx%E3%81%AB%E3%82%88%E3%81%A3%E3%81%A6%E6%B1%BA%E3%81%BE%E3%82%8B%E3%80%82E%5BL%5D%E3%81%AF%E6%AC%A1%E5%BC%8F%E3%81%A7%E3%81%97%E3%81%9F%E3%80%82.jpg "第2項. ()内の左の項は、観測値として与えられたxに対してE[L]を最小化するtの予測値だから、()内の右の項すなわち真のt との差は、観測における誤差と考えられる。 y(x)の作り方で解決できないノイズ.")
7
は、データ点の観測に伴う誤差あるいはノイズの効果を示し、真のデータ点は、大体 のような範囲にある。このノイズの項が既に述べた次の式:

8
E[L]の第1項と教師データ集合:Dから機械学習で得た y(x;D)の関係について考えてみよう。
母集団のモデルとしてp(x,t)を想定する。このモデルからDという教師データ集合が繰り返し取り出される状況を考えてみる。 Dからの機械学習の結果のy(x;D)の統計的性質は、同じサイズのDを多数回、母集団モデルp(t,x)から取り出して、その上で期待値をとったED[y(x;D)]によって評価する。 E[L]の第1項はy(x;D)を用いると次の式
![E[L]の第1項と教師データ集合:Dから機械学習で得た y(x;D)の関係について考えてみよう。](http://slidesplayer.net/slide/11479281/62/images/8/E%5BL%5D%E3%81%AE%E7%AC%AC1%E9%A0%85%E3%81%A8%E6%95%99%E5%B8%AB%E3%83%87%E3%83%BC%E3%82%BF%E9%9B%86%E5%90%88%EF%BC%9AD%E3%81%8B%E3%82%89%E6%A9%9F%E6%A2%B0%E5%AD%A6%E7%BF%92%E3%81%A7%E5%BE%97%E3%81%9F+y%28x%EF%BC%9BD%29%E3%81%AE%E9%96%A2%E4%BF%82%E3%81%AB%E3%81%A4%E3%81%84%E3%81%A6%E8%80%83%E3%81%88%E3%81%A6%E3%81%BF%E3%82%88%E3%81%86%E3%80%82.jpg "母集団のモデルとしてp(x,t)を想定する。このモデルからDという教師データ集合が繰り返し取り出される状況を考えてみる。 Dからの機械学習の結果のy(x;D)の統計的性質は、同じサイズのDを多数回、母集団モデルp(t,x)から取り出して、その上で期待値をとったED[y(x;D)]によって評価する。 E[L]の第1項はy(x;D)を用いると次の式.")
9
この式をED[]すると、第3項は消え 第1項はvariance 第2項はbias2 variance: y(x)の機械学習による推定値が、教師データ集合によって変動する度合いの期待値:教師データに依存しすぎるモデルになって新規データの予測誤差が悪化する度合い bias2:y(x)の機械学習による推定値が、損失の期待値:E[L]を最小化するtからずれる度合いの期待値:モデルを記述が単純になるとき予測誤差が悪化する度合い。
![この式をED[]すると、第3項は消え 第1項はvariance 第2項はbias2.](http://slidesplayer.net/slide/11479281/62/images/9/%E3%81%93%E3%81%AE%E5%BC%8F%E3%82%92ED%5B%5D%E3%81%99%E3%82%8B%E3%81%A8%E3%80%81%E7%AC%AC3%E9%A0%85%E3%81%AF%E6%B6%88%E3%81%88+%E7%AC%AC1%E9%A0%85%E3%81%AFvariance+%E7%AC%AC2%E9%A0%85%E3%81%AFbias2..jpg "variance: y(x)の機械学習による推定値が、教師データ集合によって変動する度合いの期待値:教師データに依存しすぎるモデルになって新規データの予測誤差が悪化する度合い. bias2:y(x)の機械学習による推定値が、損失の期待値:E[L]を最小化するtからずれる度合いの期待値:モデルを記述が単純になるとき予測誤差が悪化する度合い。")
10
以上により損失の期待値:E[L]=bias2+variance+noise
![以上により損失の期待値:E[L]=bias2+variance+noise](http://slidesplayer.net/slide/11479281/62/images/10/%E4%BB%A5%E4%B8%8A%E3%81%AB%E3%82%88%E3%82%8A%E6%90%8D%E5%A4%B1%E3%81%AE%E6%9C%9F%E5%BE%85%E5%80%A4%EF%BC%9AE%5BL%5D%3Dbias2%2Bvariance%2Bnoise.jpg "以上により損失の期待値:E[L]=bias2+variance+noise")
11
新規データに対する誤差:variance+ bias2+ noise 予測誤差
小 正則化項の重みλ 大

12
新規データに対する誤差:variance+ bias2+ noise
予測誤差 bias2 variance noise 新規データに対する誤差:variance+ bias2+ noise variance+bias2 小 正則化項の重みλ 大 L2正則化の場合 観測データに大きく異存小 λ 大正則化項(事前分布)に大きく依存 L1正則化の場合:重みがゼロ化される次元をみると ゼロの次元が少なく複雑 小 λ 大ゼロの次元が多く単純
に大きく依存. L1正則化の場合:重みがゼロ化される次元をみると. ゼロの次元が少なく複雑 小 λ 大ゼロの次元が多く単純.")
13
bias2とvarianceの間のトレードオフをK-Nearest Neighbor法と線形回帰で具体的に見てみよう。
2クラスへの分類問題で考える。 教師データはクラス: とクラス: と判定された相当数 があるとする。 未知のデータxがクラス / である確率は xに近いほうからK個の教師データ点のうちでクラス / であるものの割合 至ってシンプルだがかなり強力。

14
下の図のような教師データの配置で考える

15
K=1の場合:クラス青,赤の確率が等しい境界線は以下のようにかなり複雑。相当多くのパラメターを使わないと記述できない。教師データ数に強く依存。
は新規に到着した分類すべきデータ の点は本来青い点かもしれないが、赤だと判断される。 の点は本来赤い点かもしれないが、青だと判断される。

16
境界線はだいぶ滑らか。K=1の場合より境界を決めるパラメターは多い
この点は本来赤かもしれないが青と判断される この青の近辺のデータは本当に青かもしれないが、新規データとしては頻出しない

17
K=13以上だと、どんな新規データでも赤と判定される。

18
K=1だと非常に複雑な境界線であり、個々の教師データに強く依存した結果をだすため、過学習をしやすい。 varianceが大きい。
Kが非常に大きくなると、境界線はますます滑らか(=いい加減?)になり、あるところから個別の教師データの影響が無視され、モデルとして大域のデータに依存し、個別データに対する精密さを欠くため、新規データを正確に分類できなくなってくる。 bias2 が大きい。 以上のから、 bias2とvarianceの間には次ページの図のような関係が見てとれる。
になり、あるところから個別の教師データの影響が無視され、モデルとして大域のデータに依存し、個別データに対する精密さを欠くため、新規データを正確に分類できなくなってくる。 bias2 が大きい。 以上のから、 bias2とvarianceの間には次ページの図のような関係が見てとれる。")
19
新規データの予測誤差=bias2+variance+noise
Error rate 新規データの予測誤差=bias2+variance+noise variance bias2 K=1 K=13 K=3 境界線が単純 境界線が複雑 最適なK

20
まず線形モデルのパラメタ-w推定の復習から
bias2とvarianceの間のトレードオフを 線形回帰で具体的に見てみよう。 まず線形モデルのパラメタ-w推定の復習から

21
入力ベクトル:x から出力:y を得る関数がxの線形関数(wとxの内積)にノイズが加算された場合を再掲
得られたN個の観測データ の組(y,X)に対して2乗誤差を最小化するようにwを推定し を得る。
に対して2乗誤差を最小化するようにwを推定し を得る。")
22
ここで、前にやった損失の期待値 E(L) を思いだそう
ただし、新規の未知データは以下の通り

23
XはDにおいては定数なので、(XTX)-1XTも定数と見なせることに注意
次に すなわちN個の観測データ の組(あるいは計画行列) (y,X)=Dを学習データとする部分について考える。 Xに対して繰り返しyを観測することでDを動かした場合の 期待 値:ED[..]を求めてみよう。 重みwの期待値: のD動かした場合の期待値 共分散行列は? XはDにおいては定数なので、(XTX)-1XTも定数と見なせることに注意
 (y,X)=Dを学習データとする部分について考える。 Xに対して繰り返しyを観測することでDを動かした場合の. 期待 値:ED[..]を求めてみよう。 重みwの期待値: のD動かした場合の期待値. 共分散行列は? XはDにおいては定数なので、(XTX)-1XTも定数と見なせることに注意.")
24
共分散行列

25
bias2が0にならない状況とはどんなもの?

26
レポート課題4:この場合variance of (loss 10)の近似はどうなる?
の近似はどうなる?")
30
過学習:over-fittingと bias2-variance分解
教師データによる学習の目的は未知のデータの正確な分類や識別 過学習(over-fitting) 学習するモデルを複雑な(=パラメタ数の多い)ものにすると過学習が起こりやすい。 モデルの良さ(=(対数)尤度あるいは2乗誤差などの損失-1 )を最大化し、かつ簡単なモデルであるほど良い モデルの簡単さを表すのは線形回帰における正規化項(正則化項とも呼ぶ)。cf.情報量基準、MDL
 学習するモデルを複雑な(=パラメタ数の多い)ものにすると過学習が起こりやすい。 モデルの良さ(=(対数)尤度あるいは2乗誤差などの損失-1 )を最大化し、かつ簡単なモデルであるほど良い. モデルの簡単さを表すのは線形回帰における正規化項(正則化項とも呼ぶ)。cf.情報量基準、MDL.")



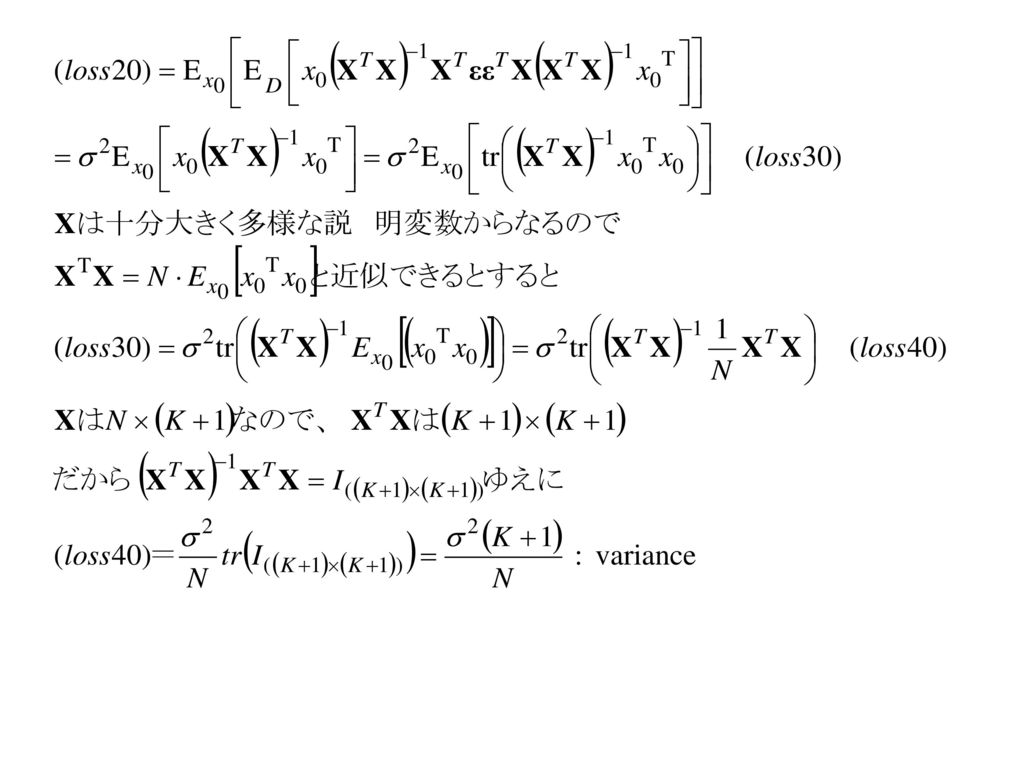
 発表者:時田 陽一.>")
 母集団の分散(母分散) 母集団中のある値の比率(母比率) p Sample 標本平均 標本分散(不偏分散) 標本中の比率.>")
 2 項分布、ポアソン分布、ガウス分布 ( 1H ) 最小二乗法( 1H )>")
 母集団における状態の推測(推測統計学)>")

 第12章 単回帰分析 廣野元久.>")


 電子情報工学科5年(前期) 7回目(21/5/2015) 担当:古山彰一 (shoichi@nc-toyma.ac.jp)>")





>")

 2項分布、ポアソン分布、ガウス分布(1H) 最小二乗法(1H)>")


