遺伝的アルゴリズム概説 An Outline of Parallel Distributed Genetic Algorithms 同志社大学工学部知識工学科 知的システムデザイン研究室 分散遺伝的アルゴリズム研究グループ 佐野 正樹,上浦 二郎,水田 伯典 ○福永 隆宏,花田 良子,片浦 哲平 遺伝的アルゴリズム研究グループの研究紹介に先立ちまして,知的システムデザイン研究室の水田が分散GAについて簡単に説明させていただきます. よろしくお願いします.
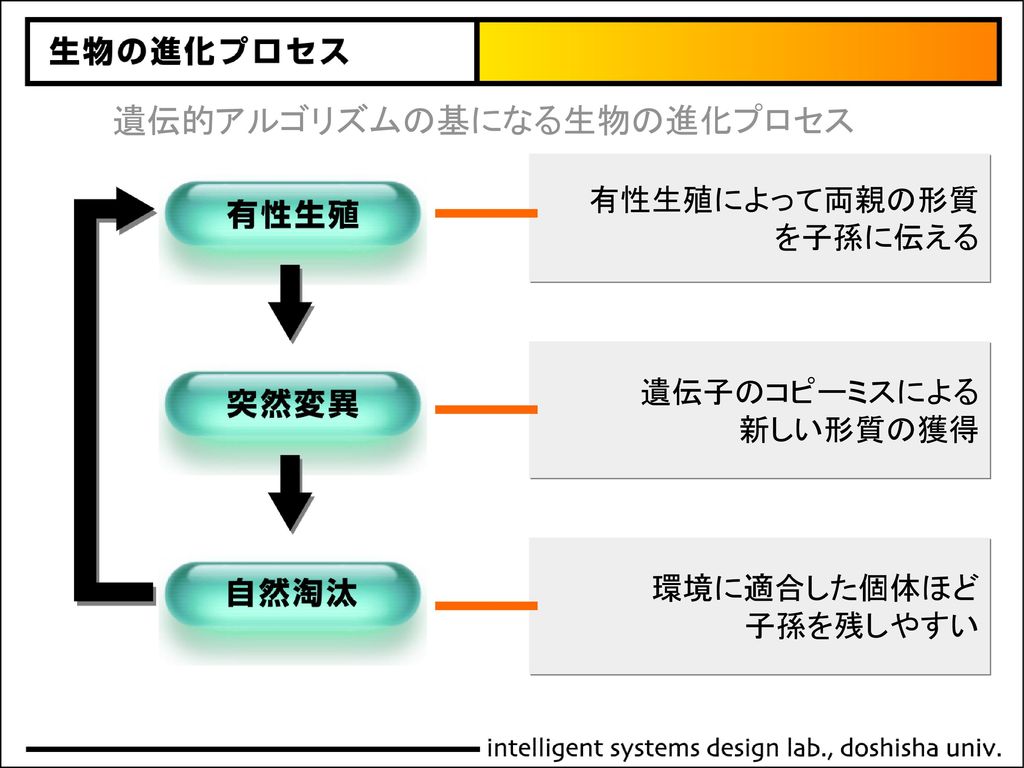
遺伝的アルゴリズムの基になる生物の進化プロセス 有性生殖によって両親の形質 を子孫に伝える 遺伝子のコピーミスによる 新しい形質の獲得 GAは生物の進化を模倣したと述べましたが,実際の生物の進化のプロセスを単純化するとこのようなものになります. まず,有性生殖によって,両親の形質が子に伝わります. その際に,遺伝子のコーピーミス,突然変異によって新しい形質が生まれることがあります. こうして生まれた新しい個体のうち環境に適応する個体は生き残り,子孫を残していきますが,適応できない個体は淘汰され死滅します. GAはこのようなプロセスを遺伝的オペレータとして実装しています. 環境に適合した個体ほど 子孫を残しやすい
親個体が持たないビットを生み出す 母集団内の多様性の維持 環境に適合した個体ほど 子孫を残しやすい 遺伝子を組み替えて新しい個体を生成 GAのプロセス 遺伝子を組み替えて新しい個体を生成 個体間の情報交換 親個体が持たないビットを生み出す 母集団内の多様性の維持 環境に適合した個体ほど 子孫を残しやすい
パラメータチューニング 並列処理・並列GA 目的関数の形質を直接利用しない 確率的な多点探索 最適なパラメータ設定が困難 計算コストが大きい 目的関数の形質を直接利用しない 確率的な多点探索 最適なパラメータ設定が困難 計算コストが大きい パラメータチューニング GAには次のような特徴と,問題点があります. まず,長所としては,パラメータをコード化したものを個体とするため実装が容易であるという点が挙げられます.そのため,大規模な問題や複雑な問題にも適用が可能です. 逆に問題点としては,まず,パラメータ設定の困難さが挙げられます.GAには設定すべきパラメータが多く,最適なパラメータ設定は問題によって変化します.このため,パラメータの最適なチューニングや自律的なコントロールに関しては多くの研究がなされています. 2つめに,GAでは反復計算を必要とするため,計算コストが大きいという問題点があります.これを解決するためのアプローチとしてGAの並列化が挙げられます. GA並列モデルとしてはこれまで様々なものが提案されていますが,その中の一つである島モデルの,分散遺伝的アルゴリズムについて説明します. 並列処理・並列GA
特徴 母集団を複数のサブ母集団に分割 一定世代ごとに移住(移住率,移住間隔) 並列計算機との親和性が高い 並列分散GA 単一母集団のSGAでは,その名の通り全ての個体を単一の母集団で処理しますが,並列分散GAでは,母集団を複数のサブ母集団に分割し,各サブ母集団で独立にGAを実行します. その上で,移住間隔とよばれる周期ごとにサブ母集団間で個体を交換します.このときに交換する個体の割合を移住率と呼びます. 並列分散GAでは各サブ母集団が独立に解探索を行い,しかもサブ母集団間で個体情報を交換することでSGAより多様性を維持したまま探索を進めることが可能です. このため,SGAよりも高速に高品質な解が得られます. また,移住の処理以外は各サブ母集団ごとに独立に実行するため,サブ母集団ごとにプロセッサを割り当てるだけで高い並立か効率を得ることが可能です. 特徴
設計変数間の依存関係によって難易度が異なる 連続関数最適化への適用 連続関数最適化問題への適用 最適化問題 連続関数でモデル化が可能なものが多い GAの特性 設計変数間の依存関係によって難易度が異なる 依存関係がない 解きやすい 依存関係がある 解きにくい これらの性質を持つテスト関数を解くことで 非線形最適化問題全般に有効と考えられる
多峰性関数 変数間に依存関係なし 多峰性関数 変数間に依存関係なし 多峰性関数 変数間に中程度の依存関係 単峰性関数 変数間に依存関係あり 対象問題 多峰性関数 変数間に依存関係なし 多峰性関数 変数間に依存関係なし 多峰性関数 変数間に中程度の依存関係 単峰性関数 変数間に依存関係あり 最後に我々がGAの性能評価に用いている対象問題について説明します.我々はおもに,連続関数の最大化問題を対象としており,図に示すような関数をもちいて性能を評価します.なお,図は2変数の場合のものですが,実際には10次元以上で実験を行います. 一般にGAでは,設計変数間に依存関係のない問題は解きやすく,逆に設計変数に依存関係のある問題は解きにくいとされています.そのため,設計変数に依存関係のある問題とそうでない問題の両方について性能を評価することで,そのほかの非線形最適化問題における性能をはかることができます. 単峰性関数 変数間に依存関係あり
生物の進化を模倣した 最適化手法 <身近な最適化問題の例> 遺伝的アルゴリズムは・・・ 最 適 化 問 題 与えられた制約条件の下で ある目的関数を最大にする 解を求める. 遺伝的アルゴリズム,以後はGAとよびます,は生物の進化の過程を工学的に模倣した最適化法です. GAが対象にする,最適化問題とは一般には「与えられた制約条件の下である目的関数を最大にする 解を求めること」と定義することができます. われわれの身近にも最適問題はたくさん存在します.たとえば,複数の携帯電話の料金プランの中から最もやすいプランを選択するというのも一つの最適化問題です. ex) 携帯電話の料金プラン
生物の進化とGAの対応 生物の進化 GAのオペレータ GAには次のようなオペレータがあります. 交叉と突然変異については生物の場合と同じです. また,自然淘汰は評価および選択というオペレータとになります. それぞれについて,簡単に説明していきます. 生物の進化とGAの対応
個体を評価,適合度を計算 次の世代の個体を決定 適合度の高い個体ほど 子孫を残しやすい 選択 個体を評価,適合度を計算 次の世代の個体を決定 最後に評価と選択ですが,母集団に含まれる全ての個体は,評価関数によって評価され適合度が計算されます. GAではこの適合度が高いものほど,環境に適合した個体であると考えます. 選択は,適合度に応じて次の世代の個体を決定するオペレータです.図のように,適合度の高い個体は,次の世代でその数を増やし,低い個体は死滅します. こうして,何世代も世代を重ねるうちに,しだいに適合度の高いものが増えていき,最適解に近づくというのがGAの基本的な概念です. 適合度の高い個体ほど 子孫を残しやすい
親個体が持たないビットを生み出す 母集団内の多様性の維持 突然変異率に応じてビットを 反転させる 突然変異は,突然変異率というパラメータに応じてビットを反転させるオペレータです. 先ほど説明した交叉では,親個体の中に存在しない遺伝子の配列は作れません.突然変異を行うことにより新しい個体が生み出され母集団の多様性を維持することができます. 突然変異率は一般に染色体長分の1程度であり,各個体につき1ビット程度の確率で起こります. 突然変異率に応じてビットを 反転させる
遺伝子を組み替えて新しい個体を生成 個体間の情報交換 交叉は親個体の遺伝子を組み替えて新しい個体を生成するオペレータです. GAの個体は図に示すような,染色体によって特徴づけられています. 交叉においては,親となる2つの個体が選択され,ランダムに交叉点が設定されます. アニメ そして,交叉点を境に遺伝子を交換し,新しい個体が生成されます. 図に示した交叉は一般に1点交叉と呼ばれるものです.このほかにも2点交叉や一様交叉などがありますがここでは省略します. 交叉
2変数のRastrigin関数にGAを適用する 連続関数最適化への適用 連続最適化問題への適用 2変数のRastrigin関数にGAを適用する Rastrigin関数の外形 Rastrigin関数の等高線
GAの適用(1) 初期化 ランダムにビット列を生成 デコード x y 初期母集団が形成される 1 0 0 1 1 0 0 0 1 1 適用1: 初期化 ランダムにビット列を生成 1 0 0 1 1 0 0 0 1 1 デコード 0.2 -0.2 x y 2D-Rastrigin 初期母集団が形成される
GAの適用(2) 交叉 ランダムに設定された 交叉点で遺伝子を交換 1 0 0 1 1 0 0 0 1 1 Parent 1 適用2: 交叉 1 0 0 1 1 0 0 0 1 1 Parent 2 0 1 0 1 0 1 0 1 0 1 1 0 0 1 1 0 0 1 0 1 0 1 0 1 0 1 0 0 1 1 Child 1 Child 2 ランダムに設定された 交叉点で遺伝子を交換
GAの適用(3) 突然変異 突然変異率に応じて ビットを反転 母集団内の多様性を維持 1 1 0 1 0 1 0 1 0 1 適用3: 突然変異 1 1 0 1 0 1 0 1 0 1 1 1 0 1 0 0 0 1 0 1 突然変異率に応じて ビットを反転 母集団内の多様性を維持
GAの適用(4) 評価・選択 デコード x= y = F(x,y)を計算,評価値を求める 1 0 0 1 1 0 0 0 1 1 評 価 適用4: 評価・選択 1 0 0 1 1 0 0 0 1 1 デコード 0.4 0.8 x= y = F(x,y)を計算,評価値を求める 評価値をもとに適合度が求まる 選 択 適合度に応じて次の世代に 残る個体が選択される 世代 t 世代 t+1
GAの適用(1) 符号化 f ( x, y )= x + y 0 1 0 0 1 1 1 0 0 1 (x, y)= (-3, 2) 0 1 0 0 1 1 1 0 0 1 (x, y)= (-3, 2) 1 0 0 1 1 0 0 0 1 1 ( x, y )=(1 , -4) 探索領域内にランダムに個体を生成 設計変数を符号化=コーディング
GAの適用(2) 交叉 ランダムに設定された交叉点で遺伝子を交換 0 1 0 0 1 1 1 0 0 1 = (-3, 2) 0 1 0 0 1 1 1 0 0 1 = (-3, 2) 1 0 0 1 1 0 0 0 1 1 = (1, -4) 0 1 0 0 1 1 0 0 1 1 = (-3, 1) 1 0 0 1 1 0 1 0 0 1 = (1, -2) ランダムに設定された交叉点で遺伝子を交換
GAの適用(3) 突然変異 (x, y)= (-3, 2) 0 1 0 0 1 1 1 0 0 1 (x, y)= (-3, -2) 0 1 0 0 1 1 1 0 0 1 (x, y)= (-3, -2) 0 1 0 0 1 0 1 0 0 1 突然変異率に応じてビットを反転
GAの適用(4) 選択 f ( x, y )= x + y 評価 (x, y)= (-3, 2) 0 1 0 0 1 1 1 0 0 1 0 1 0 0 1 1 1 0 0 1 2 2 f (x, y)= -((-3) + 2 ) = -13 選択 適合度に応じて次の世代の個体を決定 適合度の高いものほど選択されやすい