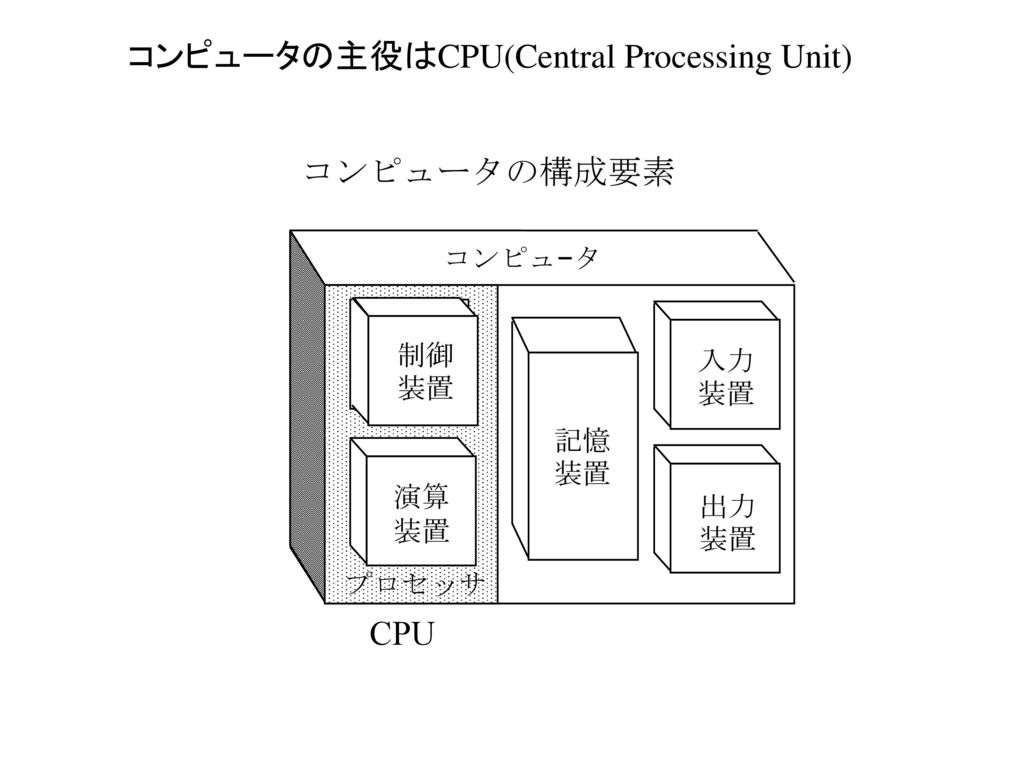
コンピュータの主役はCPU(Central Processing Unit) コンピュータの構成要素 コンピュ−タ 制御 入力 装置 装置 記憶 装置 演算 装置 出力 装置 プロセッサ CPU
コンピュ−タの世代 世代 期間 中核テクノロジ 主な新製品 1 1950-1959 真空管 商用電子計算機 1960-1968 トランジスタ 事務・技術計算機から汎用機へ 1969-1977 集積回路(IC) ミニコンピュ−タ 1978-199? LSIおよびVLSI パソコンとワ−クステ−ション 5 199?-20?? マイクロプロセッサ 個人用携帯端末と並列プロセサ
1951 UNIVAC I(商用コンピュ−タとして最初に成功) 1000 124,500 1,900 48 $1,000,000 1 年 機種 サイズ 消費電力 性能 メモリ 時価 価格性能比 立方feet ワット 加算/秒 Kバイト 1 feet = 30 cm 1951 UNIVAC I(商用コンピュ−タとして最初に成功) 1000 124,500 1,900 48 $1,000,000 1 1964 IBM S360/50(コンピュ−タ・ファミリ,大型コンピュ−タ市場支配) 60 10,000 500,000 64 $1,000,000 263 1965 PDP-8(最初の商用ミニコンピュ−タ) 8 500 330,000 4 $16,000 10,855 1976 Cray-1(ス−パ−コンピュ−タ) 58 60,000 166,000,000 32,768 $4,000,000 21,842 1981 IBM PC(パソコンのベストセラ−) 1 150 240,000 256 $3,000 42,105 1991 HP 9000/750(ワークステーション) 2 500 50,000,000 16,384 $7,400 3,556,188 1996 Intel PPro PC (200MHz) 2 500 400,000,000 16,384 $4,400 47,846,890 2003 Intel Pentium 4 PC (3.0GHz) 2 500 6,000,000,000 262,144 $1,600 11,452,000,000
millions of computers D.A.Patterson and J.L.Hennessy: Computer Organization and Design The Hardware/Software Interface, 3rd edition, Morgan Kaufmann, 2005
millions of processors D.A.Patterson and J.L.Hennessy: Computer Organization and Design The Hardware/Software Interface, 3rd edition, Morgan Kaufmann, 2005
コンピュータの性能の定義 クロック(clock) コンピュ−タは一定の速度で時を刻むクロックに基づいて動作する クロック・サイクル時間(clock cycle time) 単位:秒/サイクル クロックの時間間隔,クロック周期ともいう.たとえば10ns 1間隔=1サイクル クロック周波数(clock rate) 単位:サイクル/秒 (Hz) クロック・サイクル時間の逆数.たとえば100MHz たとえば、クロック・サイクル時間が1μ秒なら クロック周波数は1MHz 数の単位 1015 peta 1012 tera 109 giga 106 mega 103 kilo 10-15 femto 10-12 pico 10-9 nano 10-6 micro 10-3 milli
例:クロック周波数が100MHzのマシン上で10秒で実行できるプログラム のクロックサイクル数は あるプログラムの CPU実行時間 そのプログラムの クロック・サイクル数 = × クロック・サイクル時間 そのプログラムのクロック・サイクル数 = クロック周波数 例:クロック周波数が100MHzのマシン上で10秒で実行できるプログラム のクロックサイクル数は CPU時間×クロック周波数 = 10秒×100×106サイクル/秒 = 1000×106サイクル 命令あたりの平均クロック・サイクル数(Clock Cycles Per Instruction: CPI) 実行したプログラムのクロック・サイクル数 = そのプログラムで実行した命令数 CPU時間 = 実行命令数×CPI×クロック・サイクル時間 例:クロック・サイクル時間が10ns(ナノ秒),CPIが2.0の場合, 100,000命令実行するのに要する時間は 100000命令×2.0サイクル/命令×10×10-9秒/サイクル= 2.0×10-3秒= 2.0ミリ秒
クロック・周波数が100MHzのマシン上で10秒で実行できるプログラムがある. このプログラムの実行に要するクロック・サイクル数はいくつか. 問1: クロック・周波数が100MHzのマシン上で10秒で実行できるプログラムがある. このプログラムの実行に要するクロック・サイクル数はいくつか. このプログラムを6秒で実行できるマシンを開発したい. クロック周波数を上げると,その影響が別の面にでて,そのプログラムでは 1.2倍のクロック・サイクル数が必要になるという. クロック周波数をどこまで上げればよいか. 問2: 同じ命令セットア−キテクチャを実現した2種類のマシンがある(機械語は同じ). マシンAはクロック・サイクル時間が10nsで,あるプログラムでのCPIが2.0であり, マシンBはクロック・サイクル時間が20nsで,同じプログラムでのCPIが1.2である とする.このプログラムでは,どちらがどのくらい速いか. 問3: あるマシンには3種類の命令のクラスA,B,Cがあり, それぞれの命令クラスのCPIは1,2,3である. あるコンパイラ設計者が,ある文に対してコンパイラが生成するコ−ド系列を2通り検討している.1つは,A,B,Cの各クラスの命令が2,1,2回実行されるものであり,もう1つは4,1,1回実行されるものである. どちらのコ−ド系列の方が実行される命令数が多いか.実行速度はどちらが速いか. それぞれのCPIはいくつか. (1)サイクル数=10秒*(100*10^6サイクル/秒)=10^9サイクル, 6秒*(xサイクル/秒)=10^9*1.2サイクル: x= 10^9*0.2=200*10^6 (2)実行時間=サイクル数*クロックサイクル時間=実行命令数*CPI*クロックサイクル時間、 A:実行命令数*2.0*10ns=実行命令数*20ns、B:実行命令数*1.2*20ns=実行命令数*24ns、A:B = 10 : 12 (3)2+1+1=5, 4+1+1=6で前者の方が命令数が少ない。 2*1+1*2+2*3=10cycles, 4*1+1*2+1*3=9cycles, で後者の方が速い。 CPI: 10/5=2, 9/6=1.5
クロック・周波数が5GHzのマシン上であるプログラムを実行したところ 問4: クロック・周波数が3GHzのマシン上で2秒で実行できるプログラムがある. このプログラムの実行に要するクロック・サイクル数はいくつか. このプログラムで5*109の命令が実行されたとしてCPIを求めよ。 問5: クロック・周波数が5GHzのマシン上であるプログラムを実行したところ 7.5*109の命令が実行され、CPIは0.8であった。 このマシンのクロックサイクル時間と、このプログラムの実行にかかったCPU時間を求めよ。 問6: あるマシンで、Javaで書かれたあるプログラムが15秒で実行された。 新しいJavaコンパイラがリリースされて、古いコンパイラが生成する命令の0.6倍の命令ですむようになった。ただし、CPIは1.1倍になってしまった。 このJavaプログラムは、新しいコンパイラを使えば何秒で実行されるか。 (ヒント:変数をいくつか使う。たとえば、命令数をx、サイクル数をyなど)
性能尺度 以前に利用された性能尺度 MIPS (Million Instruction Per Second) = = = = 実行命令数 = 実行時間×106 実行命令数 = クロック・サイクル数×クロック・サイクル時間×106 実行命令数×クロック周波数 クロック周波数 = = 実行命令数×CPI×106 CPI×106 注意:CPIは実行されるプログラムによって,またコンパイラによって も異なるから,あるマシンのMIPSを正確に求めることは不可能 メ−カの発表するMIPSは最小のCPIを仮定したピ−クMIPS ベンチマークによる性能比較 実際のプログラムによる性能比較 SPEC CPU2000
MFLOPS(million floating-point operations per second: Mega FLOPS) 実行した浮動小数点演算の個数 = 実行時間×106 GFLOPS (Giga FLOPS) TFLOPS (Tera FLOPS) 注意:MFLOPS値はプログラムに強く依存するが,MIPSほどマシンには 依存しない.メ−カの発表するMFLOPS値は浮動小数点演算だけ を都合よく実行したときの(ピ−ク性能)値. TOP500 http://www.top500.org/ ここでは、LINPACKベンチマ−ク(線形計算のプログラム)で 世界中の高速マシンの順位付けが行われている. 筑波大のCP-PACS(2048台の超並列マシン)は368GFLOPS (ピ−ク性能614GFLOPS)で1996年に1位、1998年6位、2003年314位 2003年の1位は日本の地球シミュレータ(スパコン5000台の超並列機)で35.86TFLOPS 2005年の1位はIBM BlueGene/L(6万5千台の超並列機)で136.8TFLOPS 地球シミュレータは4位 2007年の1位はIBM BlueGene/L(13万台)で280.6TFLOPS, 日本の最高は14位(東工大)で48.9TFLOPS, 地球シミュレータは20位
コンピュータのアーキテクチャ 最初は単純(なアーキテクチャ)であったが複雑になってきた。 CISC (Complex Instruction Set Computer) それを思い切り単純化して、ワンチップCPUが作られた。 RISC (Reduced Instruction Set Computer) RISC もその後、機能を拡張して複雑化しているが、以下のような 特徴がある。 CISC: メインフレーム、インテルX86系 命令語長可変、演算はレジスタ間とメモリー、レジスタ少数 RISC: MIPS, PPC, SH4, ARM 命令語長固定、メモリーアクセスはLOAD/STOREのみ、 レジスタ多数、演算はレジスタ間のみ パイプライン制御が容易
