並列処理のためのプログラム作成
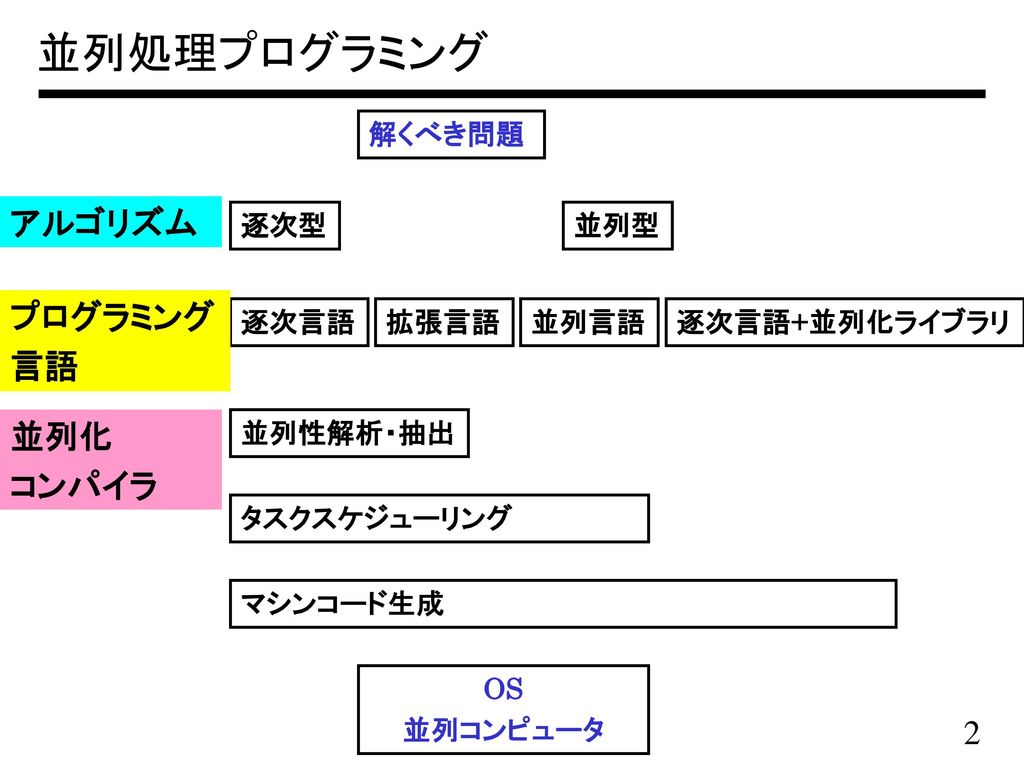
並列処理プログラミング アルゴリズム プログラミング 言語 並列化 コンパイラ 解くべき問題 逐次型 並列型 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミング アルゴリズム プログラミング 言語 並列化は行われていない 並列化 コンパイラ 解くべき問題 逐次型 並列型 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ 並列化は行われていない 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミング 人手による 並列化が必要 アルゴリズム プログラミング 言語 並列化 コンパイラ 解くべき問題 逐次型 並列型 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミング 並列型アルゴリズムが必要 アルゴリズム プログラミング 言語 アルゴリズムの並列性 以外の並列化は必要 並列化 解くべき問題 並列型アルゴリズムが必要 アルゴリズム 逐次型 並列型 プログラミング 言語 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ アルゴリズムの並列性 以外の並列化は必要 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミング アルゴリズム 並列化は行われていない プログラミング 言語 並列化のすべてを コンパイラが行う 並列化 コンパイラ 解くべき問題 アルゴリズム 逐次型 並列型 並列化は行われていない プログラミング 言語 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ 並列化のすべてを コンパイラが行う 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミング アルゴリズム 並列化が行われている プログラミング 言語 残された並列化を コンパイラが行う 並列化 コンパイラ 解くべき問題 アルゴリズム 逐次型 並列型 並列化が行われている プログラミング 言語 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ 残された並列化を コンパイラが行う 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミング (一部)並列化が行われている アルゴリズム 並列化のための書換え プログラミング 言語 並列化 コンパイラ 解くべき問題 (一部)並列化が行われている アルゴリズム 並列化のための書換え 逐次型 並列型 プログラミング 言語 逐次言語 拡張言語 並列言語 逐次言語+並列化ライブラリ 並列化 コンパイラ 並列性解析・抽出 タスクスケジューリング マシンコード生成 OS 並列コンピュータ
並列処理プログラミングモデル プログラミングモデル(ソフトウェア的な通信モデル)の観点からは次の二つに分類される. 共有変数型(単一メモリ空間型) メッセージ転送型
共有変数型 異なるプロセッサ上のプロセス間で変数を共有 共有変数を介してプロセス間通信 → ポインタ変数などの扱いが楽 共有メモリ型や分散共有メモリ型並列計算機上で用いられることが多い 物理的にメモリを共有する必要は必ずしも無い → OSサポートなど 分散メモリ型並列計算機での実装では性能低下は大 P0 P1 代入 参照 共有変数
メッセージ転送型 異なるプロセッサ上のプロセス間での通信手段 →メッセージ転送のみ 変数のパッキングなどが必要 異なるプロセッサ上のプロセス間での通信手段 →メッセージ転送のみ 変数のパッキングなどが必要 送信側と受信側のプロセッサが協調してデータ転送 分散メモリ型並列計算機上で用いられることが多い 共有メモリ型並列計算機でも実現可能 → 共有メモリ上に通信チャネルを用意する P0 P1 send receive
プログラミングモデルとH/Wの構成 ハードウェア構成とプログラミングモデルを無関係にしたい. ハードのメモリ制御(キャッシュ制御を含む)機構や通信制御機構 通信ライブラリ ソフトウェア分散共有メモリ コンパイラ パフォーマンス向上にはH/W構成に適したプログラミングが必要. PGAS: Partitioned Global Address Space モデル 例) UPC(Unified Parallel C), CAF(co-Array Fortran)
並列処理を可能とするOS環境 並列処理コンピュータ上での並列処理を実現するOS機能 プロセス間並列(マルチタスキング) 単一プロセッサでの複数プロセスの並行処理の発展形 プログラム中のタスク群を複数のプロセスに割り当て,それらを複数プロセッサで実行する. スレッド間並列(マルチスレッディング) ひとつのプロセスをさらにスレッドに分割しそれらを複数のプロセッサで実行する. プログラム中のタスク群はスレッドに割り当て,空らを複数のプロセッサで実行する.
プロセス間並列 例) 1プロセッサでの複数プロセスの並行処理 実行中 プロセスb アイドル コンテキスト スイッチ プロセスa2 プロセス生成 時間
プロセス間並列 例) 1プロセッサでの複数プロセスの並行処理 例) 2プロセッサでの複数プロセスの並列/並行処理 実行中 プロセスb アイドル プロセスa2 コンテキスト スイッチ プロセスa1 プロセス生成 時間 プロセスb プロセッサ1 プロセスa3 プロセスa2 プロセッサ2 プロセスa1 時間
プロセス間並列 プロセスの生成・終了・待ち合わせ機能 fork(), exit(), wait()などの関数 プロセス間でのデータの授受(IPC)のための機能 データ転送 「パイプ」,「ソケット」,「メッセージキュー」など データ共有 共有メモリ領域: 複数プロセスのメモリ空間の一部をオーバーラップ 同期 「シグナル」,「セマフォ」など 各種操作のコストが大きい. プロセス生成,コンテキストスイッチ,同期,通信
スレッド間並列(マルチスレッド:MT) スレッド: 同一プロセス内で複数制御フロー(スレッド)を実現. 個別の制御フローを個別のスレッドに対応させる. スレッドをプロセッサへのスケジュール単位とする. 同一プロセスのスレッドはアドレス空間を共有. → メモリ管理の負荷が小さい → 通信・同期のコストが小さい スレッド固有情報(プログラムカウンタ,スタックポインタ,レジスタセット)がプロセス情報(アドレス空間,ユーザID,etc.)より少ない. → スレッド生成や各種操作のコストが小さい.
スレッド間並列(マルチスレッド:MT) スレッド: プロセスb スレッド1 プロセッサ1 スレッド3 プロセスa スレッド2 プロセッサ2 実行中 時間 アイドル コンテキスト スイッチ スレッド生成
並列プログラミングの方法 逐次言語 + マルチタスキング 逐次言語 + スレッドライブラリ 逐次言語 + メッセージ通信ライブラリ 例) MPI (Message Passing Interface) 逐次言語 + コンパイラディレクティブ(+α) 例) OpenMP 並列言語 例) HPF (High Performance Fortran) 逐次言語 + 自動並列化コンパイラ
並列プログラミングの方法 参考書/例題プログラムの出典 「はじめての並列プログラミング」
マルチタスキングによる並列処理 forkシステムコールにより複数プロセスを立ち上げての並列処理(並行処理) 子プロセスが生成される. 子プロセス環境は親プロセスの環境が複製される. 親プロセスと子プロセスはfork関数呼出しから戻ったところからそれぞれ実行を再開. fork関数の戻り値は,子プロセスでは0となり,親プロセスでは子プロセスのプロセスIDとなる. 子プロセスでは,処理終了後exit()システムコールなどでプロセスを終了する. 親プロセス,子プロセス間では共有変数などを用いてデータの授受を行う.
マルチタスキング-例題プログラム 和を部分和として二つの プロセスで求めるプログラム 続く #include <sys/shm.h> #include <sys/types.h> #include <sys/ipc.h> #include <stdio.h> pid_t pid1, pid2; int shared_mem_id; int *shared_mem_ptr; int main() { int *rc1, *rc2; int arg1[2] = {1,5}, arg2[2] = {6,10}; int status; shared_mem_id=shmget(IPC_PRIVATE, 2*sizeof(int),0666); shared_mem_ptr=shmat(shared_mem_id,0,0); rc1 = shared_mem_ptr; rc2 = (shared_mem_ptr+1); 続く
マルチタスキング-例題プログラム 和を部分和として二つの プロセスで求めるプログラム 続く if((pid1=fork())==0){ *rc1=sum(&arg1); exit(0); } if((pid2=fork())==0){ *rc2=sum(&arg2); waitpid(pid1, status, 0); waitpid(pid2, status, 0); printf("%d %d\n", *rc1 ,*rc2); printf("%d+..+%d=%d\n", arg1[0],arg2[1], *rc1 + *rc2); int sum(int *arg_ptr) { int min = *arg_ptr; int max = *(arg_ptr+1); int i, sum; for (i=min,sum =0;i<=max;i++) sum += i; return sum; } 続く
マルチタスキング-例題プログラム 和を部分和として二つの プロセスで求めるプログラム ヘッダファイルの読み込み プロセスID変数 #include <sys/shm.h> #include <sys/types.h> #include <sys/ipc.h> #include <stdio.h> pid_t pid1, pid2; int shared_mem_id; int *shared_mem_ptr; int main() { int *rc1, *rc2; int arg1[2] = {1,5}, arg2[2] = {6,10}; int status; shared_mem_id=shmget(IPC_PRIVATE, 2*sizeof(int),0666); shared_mem_ptr=shmat(shared_mem_id,0,0); rc1 = shared_mem_ptr; rc2 = (shared_mem_ptr+1); ヘッダファイルの読み込み プロセスID変数 共有変数管理のための変数 共有変数へのポインタ変数 共有変数領域IDの確保 共有変数領域開始アドレス 続く
マルチタスキング-例題プログラム 子プロセスを生成: 戻り値は子プロセスには0、 親プロセスには子プロセスID 和を部分和として二つの プロセスで求めるプログラム if((pid1=fork())==0){ *rc1=sum(&arg1); exit(0); } if((pid2=fork())==0){ *rc2=sum(&arg2); waitpid(pid1, status, 0); waitpid(pid2, status, 0); printf("%d %d\n", *rc1 ,*rc2); printf("%d+..+%d=%d\n", arg1[0],arg2[1], *rc1 + *rc2); 子プロセスならsumを実行し 結果を共有変数へ代入 親プロセスは子プロセスIDを得る 子プロセスならsumを実行し 結果を共有変数へ代入 親プロセスは子プロセスIDを得る 子プロセスの終了を待つ 子プロセスの終了を待つ 共有変数を参照する 続く
マルチタスキング-例題プログラム 和を部分和として二つの プロセスで求めるプログラム int sum(int *arg_ptr) { int min = *arg_ptr; int max = *(arg_ptr+1); int i, sum; for (i=min, sum =0; i<= max; i++) sum += i; return sum; }
マルチタスキングによる並列処理 プロセス間での 同期(セマフォ): semop関数など データ授受: msgsnd/msgrcv関数など SMPやマルチコアシステムでの単一プログラムの並列処理では,次に紹介するマルチスレッドよる方法の方が一般的.
マルチスレッディングによる並列処理 スレッドライブラリを使用しスレッドコントロール スレッドライブラリはスレッドコントロールのためのAPIを提供している.
MT-例題プログラム 和を部分和として二つの スレッドで求めるプログラム 続く #include <pthread.h> #include <stdio.h> extern int *sum(int *); pthread_t th1, th2; int main() { int *ps1, *ps2; int arg1[2]={1,5}, arg2[2] = {6,10}; pthread_create(&th1,NULL,(void*(*)(void*))sum,&arg1); pthread_create(&th2,NULL,(void*(*)(void*))sum,&arg2); pthread_join(th1, (void**)&ps1); pthread_join(th2, (void**)&ps2); printf("%d+..+%d=%d\n", arg1[0], arg2[1], *ps1+*ps2); free(ps1); free(ps2); } 続く
MT-例題プログラム 和を部分和として二つの スレッドで求めるプログラム int *sum(int *arg_ptr) { int lb = *arg_ptr; int ub = *(arg_ptr+1); int i, sum; int *p; for (i=lb, sum =0; i<= ub; i++) { sum += i;} p =(int *)malloc(sizeof(int)); *p = sum; return p; }
MT-例題プログラム 和を部分和として二つの スレッドで求めるプログラム ヘッダファイルの読み込み スレッドID変数 #include <pthread.h> #include <stdio.h> extern int *sum(int *); pthread_t th1, th2; int main() { int *ps1, *ps2; int arg1[2]={1,5}, arg2[2] = {6,10}; pthread_create(&th1,NULL,(void*(*)(void*))sum,&arg1); pthread_create(&th2,NULL,(void*(*)(void*))sum,&arg2); pthread_join(th1, (void**)&ps1); pthread_join(th2, (void**)&ps2); printf("%d+..+%d=%d\n", arg1[0], arg2[1], *ps1+*ps2); free(ps1); free(ps2); } ヘッダファイルの読み込み スレッドID変数 二つのスレッド生成 スレッド開始関数への引数 スレッド開始関数 スレッドの終了待ち スレッド終了状態 続く
MT-例題プログラム 和を部分和として二つの スレッドで求めるプログラム スレッドローカルな変数 スレッド外からもアクセス できるように int *sum(int *arg_ptr) { int lb = *arg_ptr; int ub = *(arg_ptr+1); int i, sum; int *p; for (i=lb, sum =0; i<= ub; i++) { sum += i;} p =(int *)malloc(sizeof(int)); *p = sum; return p; } スレッドローカルな変数 スレッド外からもアクセス できるように pが終了ステータスとして通知される pthread_exit(p);でもOK
マルチスレッディングによる並列処理 スレッド間の同期 相互排除 pthread_mutex_lock(&mt) pthread_mutex_unlock(&mt) pthread_mutex_trylock(&mt) mtは同期変数: pthread_mutex_t mt 条件同期 pthread_cond_wait(&ct, &mt) pthread_cond_signal(&mt) pthread_cond_broadcast(&mt) ctは同期変数: pthread_cond_t ct など
MT-相互排除 和を部分和として二つの スレッドで求めるプログラム 続く #include <pthread.h> #include <stdio.h> extern int *sum(int *); pthread_t th1, th2; pthread_mutex_t mt = PTHREAD_MUTEX_INITIALIZER; int gsum; int main() { int *ps1, *ps2; int arg1[2]={1,5}, arg2[2] = {6,10}; pthread_create(&th1,NULL,(void*(*)(void*))sum,&arg1); pthread_create(&th2,NULL,(void*(*)(void*))sum,&arg2); pthread_join(th1, (void**)&ps1); pthread_join(th2, (void**)&ps2); printf("%d+..+%d=%d\n", arg1[0], arg2[1], gsum); free(ps1); free(ps2); } または pthread_mutex_init(&mt, NULL); 続く
MT-相互排除 和を部分和として二つの スレッドで求めるプログラム int *sum(int *arg_ptr) { int lb = *arg_ptr; int ub = *(arg_ptr+1); int i, sum; for (i=lb, sum =0; i<= ub; i++) { sum += i;} pthread_mutex_lock(&mt); gsum=gsum+sum; pthread_mutex_unlock(&mt); return 0; }
MT-条件同期 pthread_mutex_t mt = PTHREAD_MUTEX_INITIALIZER; pthread_cond_t ct = PTHREAD_COND_INITIALIZER; int flag; または pthread_cond_init(&ct, NULL); thread 0 ... pthread_mutex_lock(&mt); flag = 1; pthread_mutex_unlock(&mt); pthread_cond_signal(ct); thread 1 ... pthread_mutex_lock(&mt); while(flag == 0){ pthread_cond_wait(&ct, &mt); } pthread_mutex_unlock(&mt);
マルチスレッドプログラミング かなり玄人向けの方法 他の方法で並列プログラミングするとしても,スレッドのメカニズムは理解しておくほうが良い. 参考書 「実践マルチスレッドプログラミング」アスキー出版局 S.Kleimanら/岩本信一訳 「Pスレッドプログラミング」ピアソン・エデュケーション B.Lewisら/岩本信一訳 など
MPI(Message-Passing Interface) メッセージ通信ライブラリ(のAPI仕様) プロセス間でのデータ授受のための通信関数のライブラリ(百数十) [1]. バージョン 1994 May MPI-1.0 ・・・ 2012 Sep. MPI-3.0 複数プロセスが協調して動作する並列実行モデル プログラム開始時に複数プロセスが一斉に実行を開始し,一斉に終了する(MPI-1) 例) mpirun –np 8 my_program [1] http://www.mpi-forum.org/ MPI Forum
MPI(Message-Passing Interface) メッセージは次の三つの組で指定される 通信範囲を示すプロセスグループ(コミュニケータ) プロセスグループ中でのプロセスID(ランク) 通信の識別子(タグ)
MPIー例題プログラム プロセス間でデータを 授受するプログラム #include “mpi.h” int main(int argc, char **argv) { int myrank, error, buffer MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { error = MPI_Send(&buffer, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); } else if (myrank == 1) { error = MPI_Recv(&buffer, 1, MPI_INT, 0, 1234, MPI_COMM_WORLD, &status); } MPI_Finalize();
MPIー例題プログラム MPIプログラムの全体の枠組み ヘッダファイルの読み込み MPIライブラリの初期化 MPIライブラリの終了処理 #include “mpi.h” int main(int argc, char **argv) { int myrank, error, buffer MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { error = MPI_Send(&buffer, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); } else if (myrank == 1) { error = MPI_Recv(&buffer, 1, MPI_INT, 0, 1234, MPI_COMM_WORLD, &status); } MPI_Finalize(); ヘッダファイルの読み込み MPIライブラリの初期化 MPIライブラリの終了処理
MPIー例題プログラム メッセージの送受信 送受信で指定する情報 バッファの指定:先頭アドレス,個数,型 #include “mpi.h” int main(int argc, char **argv) { int myrank, error, buffer MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { error = MPI_Send(&buffer, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); } else if (myrank == 1) { error = MPI_Recv(&buffer, 1, MPI_INT, 0, 1234, MPI_COMM_WORLD, &status); } MPI_Finalize(); バッファの指定:先頭アドレス,個数,型 相手と文脈の指定:ランク,タグ,コミュニケータ
MPIー例題プログラム メッセージの送受信 送受信で指定する情報 バッファの指定:先頭アドレス,個数,型 #include “mpi.h” int main(int argc, char **argv) { int myrank, error, buffer MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { error = MPI_Send(&buffer, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); } else if (myrank == 1) { error = MPI_Recv(&buffer, 1, MPI_INT, 0, 1234, MPI_COMM_WORLD, &status); } MPI_Finalize(); バッファの指定:先頭アドレス,個数,型 相手と文脈の指定:ランク,タグ,コミュニケータ 受信状態 受信メッセージのランクやタグ(ワイルドカード受信の際に利用)など
MPIー例題プログラム プロセスの識別 プログラム中の各プロセスにランクが付加されそれで区別する 自プロセスのランクの取得 #include “mpi.h” int main(int argc, char **argv) { int myrank, error, buffer MPI_Status status; MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &myrank); if (myrank == 0) { error = MPI_Send(&buffer, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); } else if (myrank == 1) { error = MPI_Recv(&buffer, 1, MPI_INT, 0, 1234, MPI_COMM_WORLD, &status); } MPI_Finalize(); 自プロセスのランクの取得 自分のランクが0の場合 自分のランクが1の場合
MPIー双方向通信例題プログラム 双方向送受信をしたい.次のコードは動作するか? ブロッキングsend/receiveのためデッドロック! 双方向送受信をしたい.次のコードは動作するか? if (myrank == 0) { MPI_Send(&sb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); MPI_Recv(&rb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD, &status); } else if (myrank == 1) { 0, 1234, MPI_COMM_WORLD); 0, 1234, MPI_COMM_WORLD, &status); } ブロッキングsend/receiveのためデッドロック!
MPIー双方向通信例題プログラム 双方向送受信をしたい.次のコードは動作するか? send/receiveの順序を入れ替えてもだめ 双方向送受信をしたい.次のコードは動作するか? if (myrank == 0) { MPI_Recv(&rb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD, &status); MPI_Send(&sb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); } else if (myrank == 1) { 0, 1234, MPI_COMM_WORLD, &status); 0, 1234, MPI_COMM_WORLD); } send/receiveの順序を入れ替えてもだめ
MPIー双方向通信例題プログラム 双方向送受信をしたい.次のコードは動作するか? 双方の順序を逆にする必要 双方向送受信をしたい.次のコードは動作するか? if (myrank == 0) { MPI_Send(&sb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD); MPI_Recv(&rb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD, &status); } else if (myrank == 1) { 0, 1234, MPI_COMM_WORLD, &status); 0, 1234, MPI_COMM_WORLD); } 双方の順序を逆にする必要
MPIー双方向通信例題プログラム ノンブロッキングのIsendとWait Isendではブロッキングせずにreceiveに移行 if (myrank == 0) { MPI_Isend(&sb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD, &id); MPI_Recv(&rb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD, &rstatus); MPI_Wait(&id, &wstatus); } else if (myrank == 1) { 0, 1234, MPI_COMM_WORLD, &id); 0, 1234, MPI_COMM_WORLD, &status); MPI_Wait(&id, &wstatus); } Isendではブロッキングせずにreceiveに移行
MPIー双方向通信例題プログラム 双方向送受信を指示する関数 if (myrank == 0) { 双方向送受信を指示する関数 if (myrank == 0) { MPI_Sendrecv(&sb, 1, MPI_INT, 1, 1234, &rb, 1, MPI_INT, 1, 1234, MPI_COMM_WORLD, &status); } else if (myrank == 1) { MPI_Sendrecv(&sb, 1, MPI_INT, 0, 1234, &rb, 1, MPI_INT, 0, 1234, MPI_COMM_WORLD, &status); }
MPIー集団通信関数 典型的な通信パターンに対応する集団通信関数 交換 MPI_Sendrecv ブロードキャスト MPI_Bcast gather MPI_Gather 1 2 1 2 1 2 123 123 123 123 123 1 2 3 4 1234
MPIー集団通信関数 典型的な通信パターンに対応する集団通信関数 scatter MPI_Scatter all gather MPI_Allgather all to all MPI_Alltoall 1234 1 2 3 4 1 2 3 4 1234 1234 1234 1234 1234 abcd ABCD @!%\ 1aA@ 2bB! 3cC% 4dD\
MPIー集団通信関数 集団通信関数の利点 send/receiveの組み合わせより プログラムの意図がわかりやすい 同期関数としてはバリアが用意されている MPI_Barrier
MPIーまとめ 分散メモリ向型並列コンピュータ向きの並列プログラムAPI 実装は,MPICH2[3],Open MPI[2] が有名 参考書 MPI並列プログラミング: P.Pacheco著,秋葉博訳 実践MPI-2: W. Groppほか著 畑崎隆雄訳 参考サイト [1] http://www.mpi-forum.org/ MPI Forum [2] http://www.open-mpi.org/ [3] http://www.mcs.anl.gov/mpi/ [4] http://phase.hpcc.jp/phase/mpi-j/ml/
OpenMP 共有メモリ型並列計算機上での並列プログラミングのために, コンパイラ指示文,実行時ライブラリ,環境変数 でベース言語(C/C++, Fortran)を拡張する[1]. バージョン 1997 Oct. Fortran ver.1.0 1998 Oct. C/C++ ver.1.0 ・・・ 2011 July ver.3.1 2013 July ver. 4.0 並列実行(同期)はコンパイラ指示文として記述 ループなどに対しては自動的な負荷分散が可能 [1] http://www.openmp.org/ OpenMP ARB
OpenMP コンパイラ指示文 Fortranではdirective !$OMP... Cではpragma #pragma omp ... 指示文を無視すれば逐次実行可能 インクリメンタルに並列化が可能 プログラム開発が容易 逐次版と並列版が同じソースで管理できる
OpenMPー実行モデル マルチスレッド上でのfork-joinモデル Parallel Region 複数のスレッドで重複して実行する部分を指定する #pragma omp parallel { sub(); } マスタスレッド fork マスタスレッド スレーブスレッド call sub() call sub() call sub() call sub() join マスタスレッド
OpenMPーParallel Region 和計算のプログラム #pragma omp parallel { int chunk,start,end,psum; chunk = 100/omp_get_num_threads(); start = chunk*omp_get_thread_num(); end = start + chunk; psum = 0; for(i=start; i < end; i++) psum += a[i]; #pragma omp atomic sum += psum; } スレッドプライベート変数
OpenMPーParallel Region 和計算のプログラム #pragma omp parallel { int chunk,start,end,psum; chunk = 100/omp_get_num_threads(); start = chunk*omp_get_thread_num(); end = start + chunk; psum = 0; for(i=start; i < end; i++) psum += a[i]; #pragma omp atomic sum += psum; } スレッド数を得る関数 スレッドIDを得る関数 k = ceil(n/np) lb= k*(p-1)+1 ub= min(k*p,n) do i=lb,ub ループボディ enddo
OpenMPーParallel Region 和計算のプログラム #pragma omp parallel { int chunk,start,end,psum; chunk = ceil((float)100/omp_get_num_threads()); start = chunk*omp_get_thread_num(); end = start + chunk <100 ? start + chunk : 100; psum = 0; for(i=start; i < end; i++) psum += a[i]; #pragma omp atomic sum += psum; } k = ceil(n/np) lb= k*(p-1)+1 ub= min(k*p,n) do i=lb,ub ループボディ enddo
OpenMPー変数の共有 int i; int j; #pragma omp parallel { int k; i = .. j = .. } スレッド間シェアード変数 スレッド間シェアード変数 スレッドプライベート変数
OpenMPー変数の共有 int i; int j; #pragma omp parallel private(j) { int k; } スレッド間シェアード変数 スレッドプライベート変数 スレッドプライベート変数
OpenMPーWork sharing Parallel region内で複数のスレッドで分担して実行する部分を指定する sectionsの最後でバリア同期 #pragma omp sections { #pragma omp section { sub1(); } { sub2(); } }
OpenMPーWork sharing Parallel region内で複数のスレッドで分担して実行する部分を指定する 並列ループ スケジューリング: スタティック,ダイナミック(chunk, guided)を指定可 schedule(static,チャンクサイズ) schedule(dynamic,チャンクサイズ) schedule(guided,チャンクサイズ) schedule(runtime) forの最後でバリア同期 #pragma omp for for ( ; ; ) { }
OpenMPーWork sharing 並列ループ ループの制御変数は自動的に スレッドプライベート変数に #pragma omp for for (i=0; i<n; i++) a[i]=b[i]+c[i]; スレッドプライベート変数の明示が必要 #pragma omp for for (i=0; i<n; i++){ t=b[i]+c[i]; a[i]=t/2; } private(t)
OpenMPーWork sharing 並列ループ ループの制御変数は自動的に スレッドプライベート変数に #pragma omp for for (i=0; i<n; i++) a[i]=b[i]+c[i]; スレッドプライベート変数の明示が必要 #pragma omp for for (i=0; i<n; i++) for (j=0; j<n; j++) a[i][j]=b[i][j]+c[i][j]; private(j)
OpenMPー同期 バリア同期 チーム内のスレッドがバリアに到達するまで待つ #pragma omp barrier クリティカルセクション #pragma omp critical { } アトミック命令 メモリの更新をアトミックに行う #pragma omp atomic 文(x++, x+=...,など) マスタスレッドのみ実行 他のスレッドは素通り #pragma omp master { }
OpenMPー同期 単一のスレッドのみ実行 他のスレッドはバリア同期で待っている #pragma omp single { } paralle for のボディの一部を逐次と同順で実行 #pragma omp for ordered ... #pragma omp ordered { } メモリの一貫性保障 #pragma omp flush(変数名) メモリコンシステンシモデルはweak consistency
OpenMPー実行時ライブラリ (逐次内で)次のparallel regionでのスレッド数を指定 omp_set_num_threads(int) parallel region内で動作中のスレッド数を返す omp_get_num_threads() 利用できるスレッド数を返す omp_get_max_threads() スレッドidを返す omp_get_thread_num() 利用できるプロセッサ数を返す omp_get_num_procs() lock関数 omp_set_lock(omp_lock_t) omp_unset_lock(omp_lock_t)
OpenMPー環境変数 parallel regionでのスレッド数を指定 OMP_NUM_THREADS 並列ループのスケジューリング方法を指定 OMP_SCHEDULE
OpenMP 共有メモリ型並列コンピュータ向きの並列実行モデルとAPI インクリメンタルな並列化をサポート 参考書 C/C++プログラマーのためのOpenMP並列プログラミング (第2版)菅原清文 著 参考サイト [1] http://www.openmp.org/ gcc(ver 4.2~)でもお手軽に使えるのでお試しを
HPF(High Performance Fortran) 分散メモリ並列計算機での科学技術計算を対象 分散メモリ上へのデータ分割配置に主眼を置く. データアクセスの局所性を高める. プロセッサ間通信を減らす. データ分割をプログラマが明示的に指示する. プログラムのSPMD化や通信コードの挿入はコンパイラが行う. SPMD(Single Program Multiple Data Stream) : 各プロセッサは同一プログラムを実行するが,プロセッサIDなどに基づき異なるコード(異なるイタレーションや異なるプログラム部分など)を実行するモデル.
HPFーデータの分割配置 分散メモリ並列計算機でのデータの分散配置 例)配列変数 X(100) ブロック分割 プロセッサ1 X(1)~X(25) プロセッサ2 X(26)~X(50) プロセッサ3 X(51)~X(75) プロセッサ4 X(76)~X(100) サイクリック分割 プロセッサ1 X(1),X(5)...X(97) プロセッサ2 X(2),X(6)...X(98) プロセッサ3 X(3),X(7)...X(99) プロセッサ4 X(4),X(8)...X(100) データの分割方法の違いによって並列処理の効率に大きな影響が現れる.
HPFーデータの分割配置 PROGRAM EXAMPLE1 PARAMETER(N=100) REAL X(N), Y(N) !HPF$ PROCESSORS P(4) !HPF$ DISTRIBUTE X(BLOCK) ONTO P !HPF$ DISTRIBUTE Y(BLOCK) ONTO P ... DO I=2,N-1 Y(I) = X(I-1)+X(I)+X(I+1) ENDDO 抽象プロセッサ配列宣言 抽象プロセッサへの データレイアウト指定 プロセッサ1 X(1:25) Y(1:25) プロセッサ2 X(26:50) Y(26:50) プロセッサ3 X(51:75) Y(51:75) プロセッサ4 X(76:100) Y(76:100)
HPFー計算処理のプロセッサへの割り当て owner computes rule: 変数Xへ代入を行う代入文の計算は,その変数がローカルメモリに配置されているプロセッサ(Xのオーナー)が担当するという計算モデル. 先の例示プログラムでは: DO I=2,N-1 Y(I) = X(I-1)+X(I)+X(I+1) END DO プロセッサ1 が I=2,25 を実行 プロセッサ2 が I=26,50 を実行 プロセッサ3 が I=51,75 を実行 プロセッサ4 が I=76,99 を実行
HPFーSPMDコード コンパイラがIF文からなる実行ガードを挿入しSPMDコードを生成. 各プロセッサは同一プログラムを実行しながら,実際には異なる処理を行う. 先の例示プログラムでは,コンパイラが以下のようなコードを生成する. DO I=2,N-1 IF( Y(I)のオーナー ) THEN Y(I) = X(I-1)+X(I)+X(I+1) END DO
HPFーデータの分割配置(多次元配列) PROGRAM EXAMPLE2 PARAMETER(N=100) REAL Z(N,N) !HPF$ PROCESSORS P(4) !HPF$ DISTRIBUTE Z(BLOCK,*) ONTO P 抽象プロセッサ配列宣言 抽象プロセッサへの データレイアウト指定 配列変数Z プロセッサ1 プロセッサ2 プロセッサ3 プロセッサ4
HPFーデータの分割配置(多次元配列) !HPF$ PROCESSORS P(4) !HPF$ PROCESSORS P(2,2) (BLOCK,*) (*,BLOCK) (BLOCK,BLOCK) (SYCLIC,*) (*,SYCLIC) (SYCLIC,BLOCK)
!HPF$ ALIGN A(I) WITH B(I) !HPF$ ALIGN A(I) WITH B(I+1) !HPF$ ALIGN A(I,J) WITH B(J,I) 転置 !HPF$ ALIGN A(I,*) WITH C(I) 縮退 !HPF$ ALIGN C(I) WITH B(I,*) 複製
HPFープロセッサ間通信 先のプログラムで必要な通信 DO I=2,N-1 Y(I)=X(I-1)+X(I)+X(I+1) END DO 先のプログラムで必要な通信 プロセッサ1が, Y(25) = X(24)+X(25)+X(26) を実行する際にプロセッサ間でデータの通信が必要 データ配置 プロセッサ1 X(1)~X(25) プロセッサ2 X(26)~X(50) プロセッサ3 X(51)~X(75) プロセッサ4 X(76)~X(100) プロセッサ2,3,4でも同様 プロセッサ2から プロセッサ2が Y(26) = X(25)+X(26)+X(27) Y(50) = X(49)+X(50)+X(51) プロセッサ3が Y(51) = X(50)+X(51)+X(52) Y(75) = X(74)+X(75)+X(76) プロセッサ4が Y(76) = X(75)+X(76)+X(77) 合計6回の通信が必要
HPFープロセッサ間通信 DO I=2,N-1 Y(I)=X(I-1)+X(I)+X(I+1) END DO 例示プログラムで,データ分割配置がサイクリックの場合どのような通信が必要か? プロセッサ1 X(1),X(5)...X(97) プロセッサ2 X(2),X(6)...X(98) プロセッサ3 X(3),X(7)...X(99) プロセッサ4 X(4),X(8)...X(100) データの分割配置の形態によって通信回数が大きく異なる. → 実行効率に多大な影響 非常に多くの通信が必要となる!!! 全てのプロセッサが一つの代入文で2回づつ(98X2回!) Y(I) = X(I-1)+X(I)+X(I+1)
HPFープロセッサ間での計算負荷の均等化 負荷分散の面からはサイクリック分割の方が良い場合 DO I = 1,100 DO J = I,100 X(I,J) = X(I,J)/2 ENDDO J J I I ブロック分割 サイクリック分割
HPF データの分割配置はプログラマの知的作業とし,残りの部分(SPMD化など)をコンパイラに任せる. 科学技術計算分野ではそれなりの普及の兆し. 参考となるサイト http://www.hpfpc.org/ HPF推進協議会 →XcalableMP http://www.xcalablemp.org/
並列プログラミング 現在では完全な自動並列化は困難 ハードウェアアーキテクチャの違いを意識せずにプログラミングできる環境が望まれる 並列プログラミング 現在では完全な自動並列化は困難 ハードウェアアーキテクチャの違いを意識せずにプログラミングできる環境が望まれる 共有メモリマシン上でのMPI 分散メモリマシン上でのOpenMP 高性能を追及するためには,アーキテクチャを理解した上でのプログラミング,並列アルゴリズムの考案が必要 ヘテロジニアスな環境への対応 マルチコアCPU,マルチCPUノード,GPU搭載