Download presentation
1
Qualitative Response Model

2
被説明変数がダミー変数の回帰 例) MROZ.RAW 女性労働 –inlf 女性が外で働いていれば 1 ,そうでなけれ ば 0 –inlf=f( 家計所得,教育年数,年齢,子育て費 用) 推定方法 – 線型確率モデル (linear probability model) – プロビットモデル probit model – ロジットモデル logit model
 MROZ.RAW 女性労働 –inlf 女性が外で働いていれば 1 ,そうでなけれ ば 0 –inlf=f( 家計所得,教育年数,年齢,子育て費 用) 推定方法 – 線型確率モデル (linear probability model) – プロビットモデル probit model – ロジットモデル logit model")
3
線型確率モデル 被説明変数 y は 1 または 0 の値をとるダミー変数 線型モデルをそのまま当てはめる y 1 0 x 当てはめられた直線 y の予測値(当てはめ られた直線)は,説 明変数が特定の値を とるときに, y が 1 と なる確率を表すと解 釈することができる 係数 b は x の増加が y が 1 となる確率をどのく らい増加させるかを 表す
は,説 明変数が特定の値を とるときに, y が 1 と なる確率を表すと解 釈することができる 係数 b は x の増加が y が 1 となる確率をどのく らい増加させるかを 表す")
4
線型確率モデルの問題点 y の予測値が 0 と 1 の間に収まらない – Pr(y=1|x) のもっと良い定式化は ? – Pr(y=1|x)=F(b’x) – F( ) に確率分布関数を当てはめるとこの問題 は回避できる 分散不均一性の問題
=F(b’x) – F( ) に確率分布関数を当てはめるとこの問題 は回避できる 分散不均一性の問題.")
5
分布関数の当てはめ

6
probit model, logit model 次のようなモデルを想定 F( ) は確率分布関 数 Probit model 標準正規分布 Logit model logisitic 分布 ただし, y*= ’x+u
 は確率分布関 数 Probit model 標準正規分布 Logit model logisitic 分布 ただし, y*= ’x+u")
7
係数の意味 probit model, logit model f( ) は確率密度関数, y*= ’x+u probit model や logit model での係数の解釈 y の期待値に与える影響を正確に求めるためには, f(y*) の計算が必要 x 1,x 2,..,x k の水準に依存 (他の説明変数がとる値によっても異なる)
 は確率密度関数, y*= ’x+u probit model や logit model での係数の解釈 y の期待値に与える影響を正確に求めるためには, f(y*) の計算が必要 x 1,x 2,..,x k の水準に依存 (他の説明変数がとる値によっても異なる)")
8
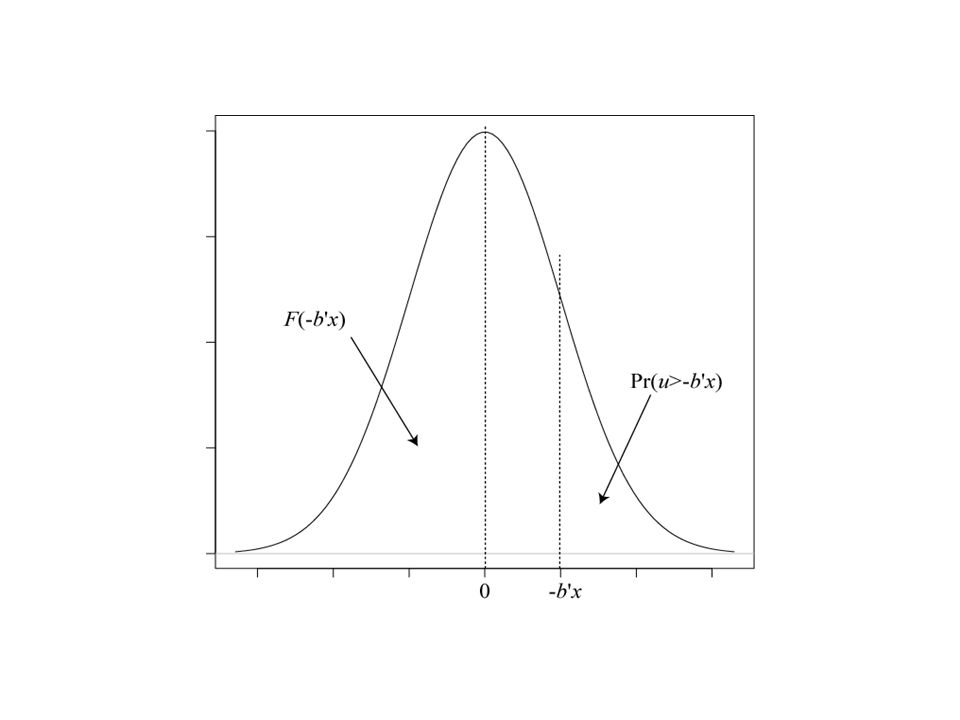
Probit model, logit model の考え方 ここで y は観察される変数であるが, y* は観察不可能な変数であるとする。 また,誤差項はある確率分布にしたがう。 例) 女性の労働参加を決定するある観察不可能な変数がある( y* )。 観察不可能な変数 y* は,説明変数 x の線型関数 + 誤差項で決定される。 y* がある閾値 (critical value) を超えると女性は労働に参加する (y=1) 。 しかし, y* が閾値を越えなければ女性は労働に参加しない (y=0)
 女性の労働参加を決定するある観察不可能な変数がある( y* )。 観察不可能な変数 y* は,説明変数 x の線型関数 + 誤差項で決定される。 y* がある閾値 (critical value) を超えると女性は労働に参加する (y=1) 。 しかし, y* が閾値を越えなければ女性は労働に参加しない (y=0)")
9
Probit model, logit model の考え方 ( 続き) 最後の等式は,確率密度関数が x=0 に関して対称的な場合に成 立 標準正規分布, ロジスティック分布では成立
 最後の等式は,確率密度関数が x=0 に関して対称的な場合に成 立 標準正規分布, ロジスティック分布では成立")
11
線形確率モデル

12
probit, logit モデルの推定 menu から Quick Estimate equation を選択して,次の画面 の Estimation settings で method に BINARY を選択する。 specification に Binary estimation method とい う option が表れるので, Probit または Logit を 選択する

13
Probit model

14
係数の比較 olsprobitlogit coefs.e.coefs.e.coefs.e. C0.7070.1500.5800.4960.8380.841 NWIFEINC-0.0030.001-0.0120.005-0.0200.008 EDUC0.0400.0070.1340.0250.2270.043 EXPER0.0230.0020.0700.0080.1200.014 AGE-0.0180.002-0.0560.008-0.0910.014 KIDSLT6-0.2720.034-0.8740.118-1.4390.201 KIDSGE60.013 0.0350.0430.0580.073

15
Probit, Logit model の推定方法 最尤法による推定 尤度関数 likelihood function probit model, logit model : F( ) を特定化し,最尤法でパラメータを決 める
 を特定化し,最尤法でパラメータを決 める")
16
係数の意味 : marginal effect probit model, logit model f( ) は確率密度関数, y*= ’x+u logit model の場合 probit model の場合 f(y*)= (y*) 標準正規分布の密 度関数
 は確率密度関数, y*= ’x+u logit model の場合 probit model の場合 f(y*)= (y*) 標準正規分布の密 度関数")
17
係数の意味: marginal effect (2) probit model, logit model の係数の比は, marginal effect の相対 的な比率を表す
 probit model, logit model の係数の比は, marginal effect の相対 的な比率を表す")
18
vector prob_b = @coefs scalar yhat = prob_b(1)* 1 + prob_b(2) *@mean(nwifeinc) + prob_b(3)* @mean(educ) + prob_b(4)* @mean(exper) + prob_b(5) * @mean(age) + prob_b(6) *@mean(kidslt6) + prob_b(7) * @mean(kidsge6) scalar dnorm_y = @dnorm(yhat) vector (7) dydx dydx(2) = dnorm_y * prob_b(2) dydx(3) = dnorm_y * prob_b(3) dydx(4) = dnorm_y * prob_b(4) dydx(5) = dnorm_y * prob_b(5) dydx(6) = dnorm_y * prob_b(6) dydx(7) = dnorm_y * prob_b(7) marginal effect の求め方 説明 直前の回帰の係数 @coefs を prob_b というベクトルに代入 説明変数が平均値をとる場合の y* を計算し, yhat というスカラー変 数に代入 yhat の値での標準正規分布の密度 関数の値を計算し,それを dnorm_y というスカラー変数に代 入 Marginal effects の結果を代入す るベクトルを dydx とする(要素 数は 7 個) 各要素に,それぞれの説明変数 の限界効果を代入 Eviews のコマンドウィンドウで次のようにタイプ probit 分析の結果を開いたまま, View/ Representation とたどり, そこの結果を張り付けて編集すると楽
* 1 + prob_b(2) prob_b(5) + prob_b(6) + prob_b(7) scalar dnorm_y vector (7) dydx dydx(2) = dnorm_y * prob_b(2) dydx(3) = dnorm_y * prob_b(3) dydx(4) = dnorm_y * prob_b(4) dydx(5) = dnorm_y * prob_b(5) dydx(6) = dnorm_y * prob_b(6) dydx(7) = dnorm_y * prob_b(7) marginal effect の求め方 説明 を prob_b というベクトルに代入 説明変数が平均値をとる場合の y* を計算し, yhat というスカラー変 数に代入 yhat の値での標準正規分布の密度 関数の値を計算し,それを dnorm_y というスカラー変数に代 入 Marginal effects の結果を代入す るベクトルを dydx とする(要素 数は 7 個) 各要素に,それぞれの説明変数 の限界効果を代入 Eviews のコマンドウィンドウで次のようにタイプ probit 分析の結果を開いたまま, View/ Representation とたどり, そこの結果を張り付けて編集すると楽")
19
説明変数の平均 値をここにコ ピーする(定数 項は 1 とする) 係数の値 この列は B 列 と C 列の掛け 算 上のセルの合計 関数を使って y* における密度関 数の値を得る norm.s.dist(, ) marginal effects marginal effect の求め方 Excel を用いた方法
 係数の値 この列は B 列 と C 列の掛け 算 上のセルの合計 関数を使って y* における密度関 数の値を得る norm.s.dist(, ) marginal effects marginal effect の求め方 Excel を用いた方法")
20
問題 (1) MROZ.RAW のデータを用い,女性の労働 参加を,線型確率モデルと logit model, probit model で推計し,係数を解釈せよ。 – 被説明変数: inlf 労働力であれば 1 – 説明変数: nwifeinc( non wife income), educ( 教育年数), exper( 実際に働いた年 数),, age (年齢), kidslt6 ( 6 歳未満の子 供の数), kidsge6 ( 6-18 歳の子供の数) logit model の場合の f(y*) は ?
 MROZ.RAW のデータを用い,女性の労働 参加を,線型確率モデルと logit model, probit model で推計し,係数を解釈せよ。 – 被説明変数: inlf 労働力であれば 1 – 説明変数: nwifeinc( non wife income), educ( 教育年数), exper( 実際に働いた年 数),, age (年齢), kidslt6 ( 6 歳未満の子 供の数), kidsge6 ( 6-18 歳の子供の数) logit model の場合の f(y*) は")
21
問題 (2)
")
22
vector prob_b = @coefs scalar yhat = prob_b(1)* 1 + prob_b(2) *@mean(nwifeinc) + prob_b(3)* @mean(educ) + prob_b(4)* @mean(exper) + prob_b(5) * ( @mean(exper ) )^2 + prob_b(6) * @mean(age) + prob_b(7) *@mean(kidslt6) + prob_b(8) * @mean(kidsge6) scalar dnorm_y = @dnorm(yhat) vector (8) dydx dydx(2) = dnorm_y * prob_b(2) dydx(3) = dnorm_y * prob_b(3) dydx(4) = dnorm_y * ( prob_b(4) + 2 * prob_b(5) * @mean(exper) ) dydx(6) = dnorm_y * prob_b(6) dydx(7) = dnorm_y * prob_b(7) dydx(8) = dnorm_y * prob_b(8) marginal effect の求め方 説明 直前の回帰の係数 @coefs を prob_b というベクトルに代入 説明変数が平均値をとる場合の y* を計算し, yhat というスカラー変 数に代入 Yhat の値での標準正規分布の密 度関数の値を計算し,それを dnorm_y というスカラー変数に代 入 Marginal effects の結果を代入す るベクトルを dydx とする(要素 数は 8 個) 各要素に,それぞれの説明変数 の限界効果を代入 この例では, expersq という exper の平方の項があるため, dydx(4) の計算は他とは異なって いる Eviews のコマンドウィンドウで次のようにタイプ probit 分析の結果を開いたまま, View/ Representation とたどり, そこの結果を張り付けると便利
* 1 + prob_b(2) prob_b(5) * ) )^2 + prob_b(6) + prob_b(7) + prob_b(8) scalar dnorm_y vector (8) dydx dydx(2) = dnorm_y * prob_b(2) dydx(3) = dnorm_y * prob_b(3) dydx(4) = dnorm_y * ( prob_b(4) + 2 * prob_b(5) ) dydx(6) = dnorm_y * prob_b(6) dydx(7) = dnorm_y * prob_b(7) dydx(8) = dnorm_y * prob_b(8) marginal effect の求め方 説明 を prob_b というベクトルに代入 説明変数が平均値をとる場合の y* を計算し, yhat というスカラー変 数に代入 Yhat の値での標準正規分布の密 度関数の値を計算し,それを dnorm_y というスカラー変数に代 入 Marginal effects の結果を代入す るベクトルを dydx とする(要素 数は 8 個) 各要素に,それぞれの説明変数 の限界効果を代入 この例では, expersq という exper の平方の項があるため, dydx(4) の計算は他とは異なって いる Eviews のコマンドウィンドウで次のようにタイプ probit 分析の結果を開いたまま, View/ Representation とたどり, そこの結果を張り付けると便利")
23
説明変数の平 均値をここに コピーする 係数の値 この列は B 列 と C 列の掛け 算 上のセルの合計 関数を使っ て y* におけ る密度関数 の値を得る marginal effects marginal effect の求め方 Excel を用いた方法

24
Tobit model 耐久財の購入量 (y) の決定 – 購入しない人 (y=0) が存在 –y>0 と y=0 のみが観察される この場合も次のようなモデルを考える –y* 観察不可能な変数で,耐久財の購入量 (y) を決定する潜在変数
 の決定 – 購入しない人 (y=0) が存在 –y>0 と y=0 のみが観察される この場合も次のようなモデルを考える –y* 観察不可能な変数で,耐久財の購入量 (y) を決定する潜在変数")
25
Tobit model の当てはめ x y OLS の当てはめ y* と x の関係 Tobit model

26
Tobit model の応用 女性の労働供給 –MROZ.RAW – 労働参加していない女性が一定割合存在 耐久財の購入 低賃金労働者の労働供給 – 生活保護の受給との関係で

27
Tobit model の解釈

28
Tobit model の解釈 (2) ここで, z~N(0,1) のとき,次の式が成り 立つことを用いている inverse Mills ratio y>0 の条件付きの期待値は, xb よりも大きく なることが重要
 ここで, z~N(0,1) のとき,次の式が成り 立つことを用いている inverse Mills ratio y>0 の条件付きの期待値は, xb よりも大きく なることが重要")
29
Tobit model の解釈 (3) y の unconditional expected value 説明変数 x が与えられた場合のyの期待値 y>0 の条件付き期待値は前頁
 y の unconditional expected value 説明変数 x が与えられた場合のyの期待値 y>0 の条件付き期待値は前頁")
30
Tobit モデルの解釈 (4) 結果だけまとめておく
 結果だけまとめておく")
31
Tobit の推定方法 menu で Quick Estimate equation Estimation settings の method で CENSORED -.. を選択する 誤差項の分布を選択 ( Tobit は正規分布) 打ち切りの位置 を指定する。 0 以外の値も,右 側の指定もでき る。
 打ち切りの位置 を指定する。 0 以外の値も,右 側の指定もでき る。.")
32
E-Views での Tobit model の推定 の推計値

33
Dependent varhours Tobit OLS Coefs.e.Coefs.e. C965.31446.441330.48270.78 NWIFEINC-8.814.46-3.452.54 EDUC80.6521.5828.7612.95 EXPER131.5617.2865.679.96 EXPERSQ-1.860.54-0.700.32 AGE-54.417.42-30.514.36 KIDSLT6 - 894.02 111.88-442.0958.85 KIDSGE6-16.2238.64-32.7823.18 1122.02 750.179 Tobit model と OLS の比較 E-Views での出 力 Tobit の場合, xj の 1 単位の増加 y の期待値に与え る影響をみるた めには, x’b/s を 計算し,標準正 規分布関数から その涙液分布を 計算する必要あ り。単純に比較 できない

34
問題 (3) MROZ.RAW 女性の労働時間の回帰分析 –40% 強が労働時間 0 – 被説明変数: hours – 説明変数: nwifeinc, educ, exper, exper^2, age, kidslt6,kidsge6 –OLS と Tobit model で推計し,結果を解釈せよ
 MROZ.RAW 女性の労働時間の回帰分析 –40% 強が労働時間 0 – 被説明変数: hours – 説明変数: nwifeinc, educ, exper, exper^2, age, kidslt6,kidsge6 –OLS と Tobit model で推計し,結果を解釈せよ")



 母集団の分散(母分散) 母集団中のある値の比率(母比率) p Sample 標本平均 標本分散(不偏分散) 標本中の比率.>")

 仮説検定. 単一の制約 –t 検定 – メニューから行う方法 複数の制約 –F 検定 – メニューから行う方法 –F 統計量を実際に求める 構造変化 最適なモデルの決定.>")

 2 項分布、ポアソン分布、ガウス分布 ( 1H ) 最小二乗法( 1H )>")


 第12章 単回帰分析 廣野元久.>")
 generalized linear Models>")






.>")

