Download presentation
1
オンライン学習 Prediction Learning and Games Ch2
オンライン学習 Prediction Learning and Games Ch2. Prediction with Expert Advice

2
専門家の助言による予測

3
roundとは オンライン学習における1個のデータからの 推論1回分のこと
Cf. epoch とは、全データに対するroundを一回りすること このような状況における予測者の目標はroundあたりの regretをゼロにすること

4
予測者=専門家の予測を平均 時刻tにおける専門家の予測の重み付き平均

5
そこで、Ri,t-1の増加関数を、非負、凸、増加関数 の微分 を用い、 とする
よって Lemma2.1

7
Regret vectorの記法 時刻tのinstantaneous regret vector:
時刻Tまでの累積regret vector: potential function: 重み付き平均予測者:

8
Potential functionを用いた定理
Blackwell条件:Lemma2.1のΦによる表現 定理2.1: 予測者がpotential function に対してBlackwell条件を満たしているとき

9
この項はBlackwell条件より≤0 なので
定理2.1の証明 この項はBlackwell条件より≤0 なので

10
ΨがConcaveなのでこの項 ≤0 だから

11
定理2.1の利用 Regret: Ri,nの上限を与える これに定理2.1を組み合わせれば

12
定理2.1の利用: 多項式重み平均予測者

13
Corolloary 2.1 損失関数lは凸(convex)で[0,1]区間の値をとり、最小値=0。このとき Proof.
![Corolloary 2.1 損失関数lは凸(convex)で[0,1]区間の値をとり、最小値=0。このとき Proof.](http://slidesplayer.net/slide/11222029/60/images/13/Corolloary+2.1+%E6%90%8D%E5%A4%B1%E9%96%A2%E6%95%B0l%E3%81%AF%E5%87%B8%EF%BC%88convex%29%E3%81%A7%5B0%2C1%5D%E5%8C%BA%E9%96%93%E3%81%AE%E5%80%A4%E3%82%92%E3%81%A8%E3%82%8A%E3%80%81%E6%9C%80%E5%B0%8F%E5%80%A4%EF%BC%9D%EF%BC%90%E3%80%82%E3%81%93%E3%81%AE%E3%81%A8%E3%81%8D+Proof..jpg "Corolloary 2.1 損失関数lは凸(convex)で[0,1]区間の値をとり、最小値=0。このとき Proof.")
14
=N

15
定理2.1の利用 指数重み平均予測者

16
Corolloary 2.2 損失関数lは凸(convex)で[0,1]区間の値をとり、最小値=0。η>0に対して Proof.
![Corolloary 2.2 損失関数lは凸(convex)で[0,1]区間の値をとり、最小値=0。η>0に対して Proof.](http://slidesplayer.net/slide/11222029/60/images/16/Corolloary+2.2+%E6%90%8D%E5%A4%B1%E9%96%A2%E6%95%B0l%E3%81%AF%E5%87%B8%EF%BC%88convex%29%E3%81%A7%5B0%2C1%5D%E5%8C%BA%E9%96%93%E3%81%AE%E5%80%A4%E3%82%92%E3%81%A8%E3%82%8A%E3%80%81%E6%9C%80%E5%B0%8F%E5%80%A4%EF%BC%9D%EF%BC%90%E3%80%82%CE%B7%3E0%E3%81%AB%E5%AF%BE%E3%81%97%E3%81%A6+Proof..jpg "Corolloary 2.2 損失関数lは凸(convex)で[0,1]区間の値をとり、最小値=0。η>0に対して Proof.")
18
指数重み平均予測者の最適上限:定理2.2 最適上限は以下の式であり、3.7節でこれを改善することができないことが示される。
定理2.2は、以下の補題を使えば比較的簡単に証明できる。 Lemma2.2

20
ηの時間依存性を除く 定理2.3 Lemma 2.3

21
最も優秀=最少損失のexpertが知られている場合
半数以上が損失=0のexpertなら、多数決で半数ずつ損失≠0のexpertを排除していくことによってlogN回で収束する。 もう少し一般化すると 定理2.4

23
Colloary 2.4

24
損失の微分を用いる予測者 指数重み予測の重みwi,t-1の定義中に現れる累積損失を累積損失の勾配(微分)に置き換える
に置き換える")
25
損失の微分を用いる予測者 指数重み予測の重みwi,t-1の定義中に現れる累積損失を累積損失の勾配(微分)に置き換える
に置き換える")
27
スケール変換 損失関数がM倍されているので当然

28
payoff(利得)の最大化
の最大化")
29
Regretが減衰する場合 「現在の損失のほうが過去の損失より大切」というのはreasonable この考え方での累積損失を分析する

30
定理2.7 平均減衰累積regretの下限

31
定理2.8平均減衰累積regretの上限(多項式重みの予測者の場合)
")


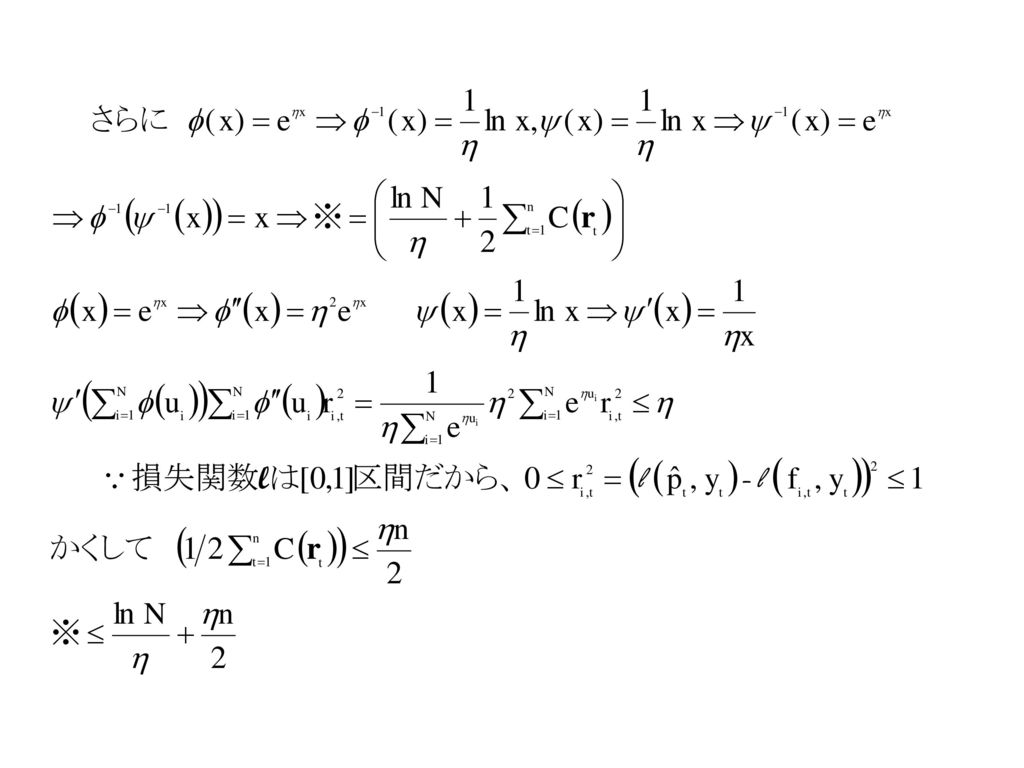





, 多項 式 ) Theorem. (補間多項式の存在と一意性) 各 i = 0, …, n について、 をみたす、次数が高々 n.>")








>")





繰返し法による方法>")
 教科書には相当する章はない>")
 三角関数 オイラーの公式 微分積分 微分方程式 付録 三角関数関連の公式>")
>")