生物統計学・第4回 全体を眺める(3) 各種クラスター分析 生物統計学・第4回 全体を眺める(3) 各種クラスター分析 2013年10月28日 生命環境科学域 応用生命科学類 尾形 善之
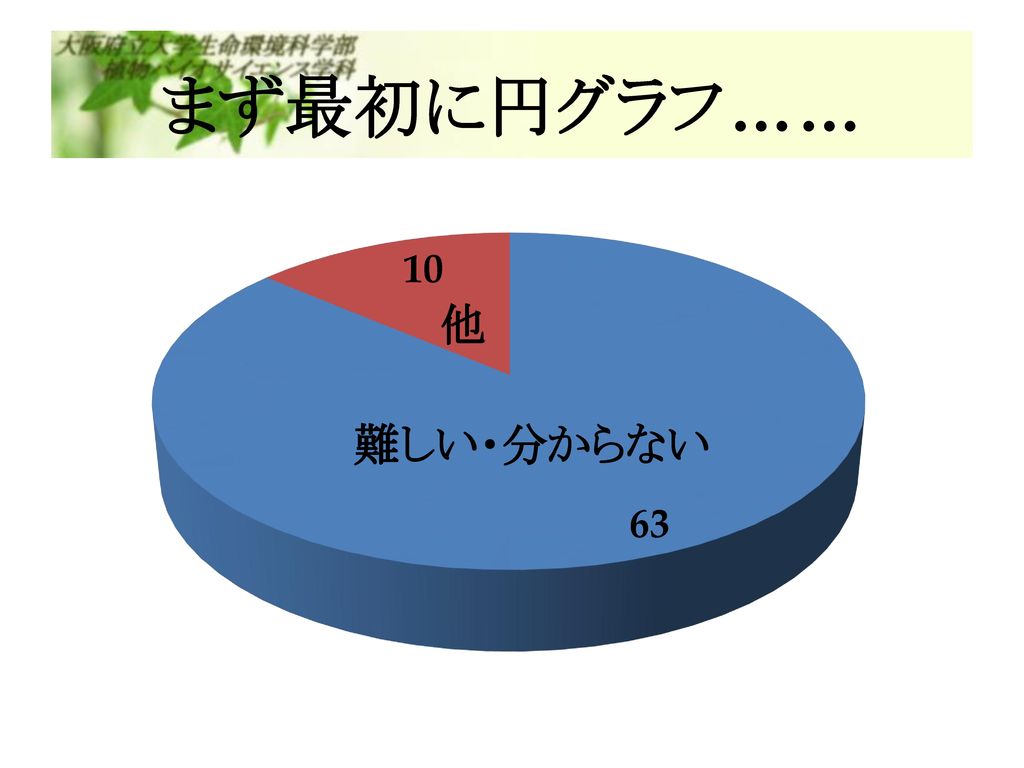
まず最初に円グラフ…… 他 難しい・分からない
先週のレポートから 多かった意見 そもそも「主成分」が分からない 寄与率のグラフからついていけない 得点のグラフからついていけない グラフの軸(目盛り)の意味が分からない 3つのグラフの関係が分からない 計算の仕方が分からない どうやって解釈していいのか分からない ともかく全部分からない、目的も分からない、何が分からないかも分からない
生物統計学・第4回 全体を眺める(3) 主成分分析からのクラスター分析 生物統計学・第4回 全体を眺める(3) 主成分分析からのクラスター分析 2013年10月28日 生命環境科学域 応用生命科学類 尾形 善之
そもそもなんで主成分分析? 79実験条件あると、79個の軸でデータを見ないといけない 2実験なら、そのままグラフ化 なるべく少ない軸(できれば2つの軸)でデータ全体を眺めたい そのためには、うまく実験データを組み合わせたい
目で見る主成分分析の原理 主成分の利点 1.4倍の幅でデータ(点)を表すことができる データを分けやすくしている 実験 (成分)2 幅140 第1主成分(Z1) 主成分の利点 1.4倍の幅でデータ(点)を表すことができる データを分けやすくしている 幅140 幅100 発現量 実験(成分)1
目で見る主成分分析の原理 実験 主成分 成分1 50% 80% 成分2 20% 実験 (成分)2 遺伝子 発現量 実験(成分)1 寄与率50% 実験 主成分 成分1 50% 80% 成分2 20% 第1主成分(Z1) 寄与率80% 第2主成分(Z2) 寄与率20%
79実験成分なら…… 主成分分析とは… 主成分分析の目的 実験 主成分 成分1 1.3% 84.1% 成分2 3.5% 成分3 3.3% 成分4 2.3% 成分5 1.6% 成分6 0.8% … 成分79 0.01% 主成分分析とは… データをうまく説明する軸を作り直す 主成分分析の目的 たくさんの成分(実験条件)のデータを2本の軸で説明する まずは寄与率の大きい主成分を探す
チェックポイント・I 主成分分析の目的は? 「主成分」は理解できましたか?
主成分分析で使う3つのグラフ 寄与率 負荷量 得点 Rを使った主成分分析 第5回(次回)の「標準化」で説明します 第9回の「相関係数」で説明します Rを使った主成分分析 第13回の「Rを使いこなす」で説明します
主成分分析のグラフの使い方 寄与率:主成分のための指標 得点:遺伝子のための指標 負荷量:実験条件のための指標 どの主成分がデータ全体をうまく表しているか 高い寄与率の主成分(主成分Aとする)を選ぶ 得点:遺伝子のための指標 注目遺伝子が主成分Aと関係しているか 主成分の意味付けから遺伝子の特徴を推定する 負荷量:実験条件のための指標 どの実験が主成分Aに関わっているか 主成分の意味を実験条件で意味づける
この辺りも何か役に立つことを表しているかも 寄与率:主成分のための指標 データ全体をよく表している この辺りも何か役に立つことを表しているかも 高い寄与率の主成分を選ぶ データ全体を表している 注目遺伝子を特徴付けられるか?
寄与率の実際 分散(ばらつき) 累積(%) データ全体 582 100.0 第1主成分 489 84.1 第2主成分 20 87.6 第3主成分 19 90.9 第4主成分 13 93.2 第5主成分 9 94.8 第6主成分 4 95.5 … 第79主成分 0.02
得点=遺伝子の発現量(平均との差)×各実験の負荷量 得点:遺伝子のための指標 目盛りはあくまで目安です 得点=遺伝子の発現量(平均との差)×各実験の負荷量 ランダムとの比較 データに特徴があるかを確認 注目遺伝子 主成分ごとに位置を確認(今回は正) At1g56650
負荷量:実験条件のための指標 各成分 絶対値が大きい実験条件に注目 第1主成分 目盛は目安です すべての実験条件が「負」 注目遺伝子は「正」 ○に対応する実験群は? 成熟している組織
チェックポイント・II 主成分分析の流れに従って、「寄与率」「得点」「負荷量」の順に説明しなさい。 主成分分析の大まかな流れは理解できましたか?
本日の本題 クラスター分析(「クラスタリング」とも言います) 各種クラスター分析 データを分類するのに使います 実験群のクラスター 遺伝子群のクラスター 各種クラスター分析 主成分分析もクラスター分析のひとつです 階層(的)クラスターが一番有名です その他 自己組織化マップ(SOM)、ネットワーク解析、ヒートマップなど
階層的クラスター 最も近い関係を線で繋ぐ Rでは「dist」と「hclust」を使う トーナメント戦のやぐら 手順は「131028clusteringstep.txt」を参照 実験条件は「file.pdf」を参照
階段状になっているところには気を付ける 本当は似てないかも 実験間での階層的クラスター 階段状になっているところには気を付ける 本当は似てないかも
階層クラスターの特徴 データ全体をひとつの木に纏める ヒートマップと組み合わせられる 階段状のところには要注意 固まっているものが似ている ヒートマップと組み合わせられる 次のスライドで説明 階段状のところには要注意 本当は似ていないこともある 集まってほしい実験条件が分かれてしまう 方法によって分かれ方が異なる
階層的クラスターとヒートマップ 図の説明 縦:実験 横:遺伝子 赤いほど発現量が多い これで50遺伝子
遺伝子の発現傾向を分類できるが、丸の数は自分で決める 自己組織化マップ(SOM) 79実験での遺伝子発現 遺伝子名 遺伝子の発現傾向を分類できるが、丸の数は自分で決める
自己組織化マップの特徴 遺伝子発現傾向と遺伝子名を同時に見ることができる 丸の数は自分で設定する 遺伝子数が多いと遺伝子名は読めない 解釈しやすい(主成分分析と比べれば……) 丸の数は自分で設定する 何を分けたいか予め決めておく必要がある 遺伝子数が多いと遺伝子名は読めない 左の図から選び出すことはできる
遺伝子の関係は見やすいが、発現傾向は同時には見れない ネットワーク解析 遺伝子の関係は見やすいが、発現傾向は同時には見れない
ネットワーク解析の特徴 遺伝子間の関係を見やすくする 他の情報も併せて載せやすい 遺伝子の発現傾向を載せるのは難しい 解析手順が少し難しい けっこう数が多くても理解可能 他の情報も併せて載せやすい 遺伝子の機能情報とか 遺伝子の発現傾向を載せるのは難しい 一つ一つにグラフを書くと煩わしい 解析手順が少し難しい Rの作業が煩雑
クラスター分析の使い分け 主成分分析 階層的クラスター 自己組織化マップ ネットワーク解析 ともかくまずはこれが便利 遺伝子発現と実験の両方を見たいとき 自己組織化マップ グループ分けが目的のとき(グループ数固定) ネットワーク解析 全体の分かれ方を見たいとき 少数で関係をはっきり見たいとき
チェックポイント・III クラスター分析とは? 各種クラスター分析の使い分けは?
今日の自習のポイント Rでの階層クラスターと自己組織化マップ Rでの作業手順 そもそもRの使い方…… 131028clusteringstep.txt そもそもRの使い方…… Rの使い方.docx(まだ用意できていません……)
次回までの予習 次回は「標準偏差、標準誤差、標準化」です 教科書 インターネット 標準偏差、標準誤差、標準化、分散、偏差値 Z化、単位ベクトル
本日の課題 シロイヌナズナの79実験条件の遺伝子発現データを手に入れました。 遺伝子の発現と実験条件を同時に見たい場合のクラスター分析法を答えなさい。 生物データセットに対してクラスター分析を行った印象(疑問点)を書いてください。